284,3 Zettabyte – so hoch soll das weltweit generierte und replizierte Datenvolumen im Jahr 2027 sein, fast drei Milliarden Terabytes. Die Datenmassen nehmen beständig zu. Und sie werden auch für Unternehmen immer mehr zur Herausforderung. Diese sind kaum noch in der Lage, ihrer Daten Herr zu werden und schnell die richtigen Erkenntnisse aus ihnen zu ziehen. Da die Datenmengen nicht weniger werden, brauchen sie dringend einen neuen Ansatz für ihr Datenmanagement. Wie dieser aussehen sollte und welche Veränderungen dafür nötig sind, verrät Otto Neuer, Regional VP und General Manager bei Denodo.
Vor einigen Jahren entwickelte Zhamak Deghani das Data-Mesh-Konzept, das seither immer mehr Anhänger und Anwendung findet. Im Grunde handelt es sich hierbei um einen Ansatz zur Demokratisierung und Dezentralisierung von Data Engineering, um die Time-to-Value zu verkürzen. Dafür baut der Ansatz auf vier Prinzipien auf:
- Domain Ownership: Die Verantwortung für ihre Daten liegt bei den operativen Domänenteams, die diese Daten generieren, und nicht mehr bei den zentral in der IT-Abteilung positionierten Data Scientists oder Data Engineers. Denn die Domänenteams kennen ihre Daten am besten und wissen, wie man sie sinnvoll einsetzen könnte.
- Data as a Product: Daten werden von den Domänenteams in Produkte verwandelt, zum Beispiel in physisch vorhandene Datensets, virtuelle Ansichten, die Daten nach Bedarf aus einer oder mehrere Datenquellen integrieren, oder gespeicherte SQL-Querys und -Skripte, die aufgerufen werden können.
- Self-Service Data Platform: Damit die Domänenteams effizient mit ihren Daten arbeiten und eigene Datenprodukte entwickeln können, brauchen sie einfachen Zugriff auf diese Daten und gegebenenfalls auch auf andere, die sie mit ihren verbinden wollen.
- Federated Computational Governance: Für die ersten drei Prinzipien müssen gewisse Standards durchgesetzt werden, zum Beispiel im Hinblick auf die Datenstruktur, die Namensgebung von Datenprodukten oder die Datenqualität. Zudem muss sichergestellt sein, dass beispielsweise nur befugte Mitarbeiter Zugriff auf sensible Daten und Datenprodukte, die diese integrieren, haben.
Wie Unternehmen Data Mesh einführen können
Für die Umsetzung des Data-Mesh-Ansatzes ist vor allem ein kultureller und organisatorischer Wandel notwendig. Denn in der Praxis stellen sich oft die Data Scientists und Data Engineers als Nadelöhr heraus, in dem Datenanfragen aufgrund der hohen Menge stecken bleiben. Dies versucht Data Mesh über die Verlagerung ihrer Aufgaben in die Domänenteams zu lösen. Das bedeutet aber auch, dass die Teammitglieder dort bereit sein müssen, neue Fähigkeiten zu lernen und zu sogenannten „Citizen Data Engineers“ zu werden.
Diese Umstellung lässt sich durch mehrere Faktoren positiv beeinflussen: Zum einen können Unternehmen Offenheit schaffen, indem sie ihren Mitarbeitern die Vorteile für ihre tagtägliche Arbeit aufzeigen – keine Wartezeiten auf Daten und Analysen mehr, ein höherer Grad an Selbstständigkeit, eine schnellere Umsetzung von Initiativen oder Projekten. Zum anderen braucht es natürlich ein umfassendes Training der Mitarbeiter. Hierbei können auch die bereits angestellten Data Scientists und Data Engineers eingebunden werden, ihr Wissen teilen und auch in Zukunft bei Anfragen unterstützen.
Darüber hinaus müssen Unternehmen aber auch einen Weg finden, wie sie ihre Daten ihren Mitarbeitern – vor allem, wenn diese keine formale IT-Ausbildung haben – bestmöglich zur Verfügung stellen können. Darauf zielt das dritte Prinzip von Data Mesh ab. Aber die immer komplexeren IT-Umgebungen, die jeden Tag Massen an Daten generieren, werden dabei zur Herausforderung. Zentrale Speicher wie Data Lakes oder Data Warehouses könnten zwar im ersten Moment Abhilfe schaffen, sorgen langfristig aber für weitere Probleme, wenn etwa neue Daten doch an einer anderen Stelle gespeichert werden und neue Datensilos entstehen, beim Bewegen der Daten deren Qualität sinkt oder das Auffinden der richtigen Daten mühsam ist. Deshalb bietet sich eine Data-Fabric-Lösung als zugrundeliegende Plattform für den Data-Mesh-Ansatz an.
Zentraler Zugriff auf dezentrale Daten
Bei diesem Ansatz handelt es sich um eine Plattform, die eine Vielzahl von Datenquellen anbinden kann, einschließlich On-Premises-Systeme, Cloud-Anwendungen, SaaS-Bereitstellungen und Internet of Things (IoT)-Geräte. Zudem ist sie in der Lage, externe Datenquellen, die für Datenprodukte und -analysen einen Mehrwert haben, anzubinden. Dabei kann es sich beispielsweise um Anwendungen von Partnern oder Dienstleistern handeln, aber auch öffentlich zugängliche Datenquellen. Über die Konnektoren werden alle im Unternehmen vorhandenen Daten erfasst, klassifiziert und es wird ihre Qualität überprüft. Gleichzeitig lassen sich mithilfe von einer entsprechenden Anwendung Data-Governance-Richtlinien durchsetzen – wie es das vierte Prinzip von Data Mesh fordert. So können Daten zum Beispiel über diese zentrale Plattform für bestimmte Mitarbeiter maskiert werden, damit diese keine Informationen sehen, die sie nicht sehen sollten.
Bei der Auswahl einer Data-Fabric-Software sollten Unternehmen allerdings darauf achten, dass sie auch einen Datenkatalog bietet, was in der Regel aber der Fall ist. In diesem Datenkatalog werden diese Daten mitsamt ihrer Metadaten – wo befinden sich die Daten in der IT-Umgebung, wer hat sie gespeichert, wann wurden sie zuletzt verändert, etc. – verzeichnet. Erst dadurch sind die Citizen Data Engineers in der Lage, alle für ihre Arbeit relevanten Daten zu finden. Daneben sollte die Data-Fabric-Lösung auch über ein User Interface verfügen, dass für alle Mitarbeiter intuitiv nutzbar ist, unabhängig davon, wie technisch versiert sie sind.
Fazit
Wenn Unternehmen das Potenzial ihrer Daten besser als bisher nutzen wollen, müssen sie zum einen mehr Mitarbeitern Zugang zu diesen Daten bieten. Die Grundlage dafür schafft eine Data-Fabric-Plattform. Zum anderen müssen sie ihnen aber auch beibringen, mit diesen Daten selbstständig zu arbeiten. Dadurch beschleunigt sich die Time-to-Value, da die Data Scientists und Data Engineers sich nicht mehr um unzählige Anfragen aus dem gesamten Unternehmen kümmern müssen. Stattdessen können die einzelnen Teams mit den Unternehmensdaten arbeiten und mit diesen Datenprodukte entwickeln, die in ihren Augen Potenziale bieten.
Autor: Otto Neuer, Regional VP und General Manager bei Denodo
Fachartikel





Studien

Drei Viertel aller DACH-Unternehmen haben jetzt CISOs – nur wird diese Rolle oft noch missverstanden

AI-Security-Report 2024 verdeutlicht: Deutsche Unternehmen sind mit Cybersecurity-Markt überfordert

Cloud-Transformation & GRC: Die Wolkendecke wird zur Superzelle

Threat Report: Anstieg der Ransomware-Vorfälle durch ERP-Kompromittierung um 400 %

Studie zu PKI und Post-Quanten-Kryptographie verdeutlicht wachsenden Bedarf an digitalem Vertrauen bei DACH-Organisationen
Whitepaper




Unter4Ohren

Datenklassifizierung: Sicherheit, Konformität und Kontrolle

Die Rolle der KI in der IT-Sicherheit
CrowdStrike Global Threat Report 2024 – Einblicke in die aktuelle Bedrohungslandschaft
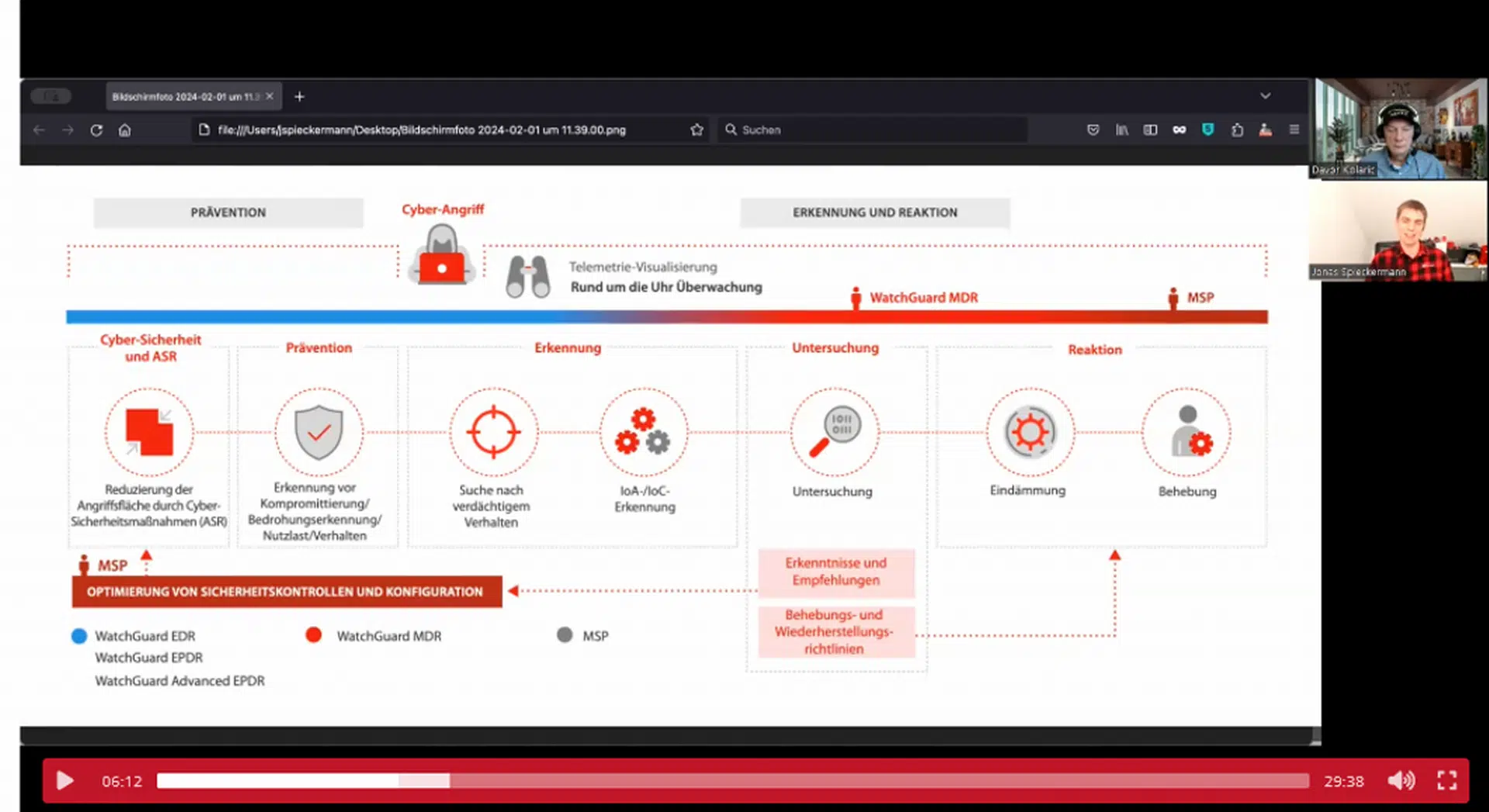
WatchGuard Managed Detection & Response – Erkennung und Reaktion rund um die Uhr ohne Mehraufwand