Der mehrtägige Totalausfall des Cloud-Providers OHVcloud zeigt, wie eng die IT von Firmen mit der Cloud verknüpft sind und wie wichtig die Wahl des richtigen Providers ist. Denn der Effekt der Datengravitation lässt schnelle und leichte Wechsel nicht zu. Je mehr Daten und Dienste ein Unternehmen eines bestimmten Providers nutzt, desto größer ist die Datenlast und desto langwieriger und träger die Migration zu alternativen Angeboten.
Daher lohnt es sich, vorab einige wichtige Punkte zu klären, bevor man sich „ewig“ bindet: Denn der Wahn ist kurz, die Reu ist lang. Die folgenden Fragen helfen Unternehmen, die Cloud-Angebote auf die wichtigsten Punkte zu prüfen, um eine zukunftssichere Wahl zu treffen:
Werden alle Workloads unterstützt?
Die Workloads spiegeln die Service-Leistung und Innovationskraft des jeweiligen Providers wider. Gerade bei Digitalisierungsvorhaben ist es entscheidend, dass der Provider bereits wichtige Eckdienste liefert und in seiner Roadmap moderne Module, wie Big Data oder IoT (Internet of Things) ankündigt. Denn der Cloud-Provider sollte der digitalen Transformation auf keinen Fall im Wege stehen.
Folgende wichtige Workloads sollten unterstützt werden:
- Big Data: Diese Servicemodule helfen, große Datenmengen schnell auszuwerten und mithilfe von Prognosemodellen neue Erkenntnisse aus den Daten zu gewinnen.
- Open Source: Der Provider sollte idealerweise neben den kommerziellen auch eine Reihe von Open Source Plattformen einbinden können, damit ein Unternehmen die freie Wahl bei diesen hat. Insbesondere Plattformen wie MongoDB, OpenStack und auf Container basierte Umgebungen wie Docker oder Kubernetes sollten abgedeckt werden, um zukunftssicher zu sein.
- Hyperkonvergente Infrastrukturen: Der Provider sollte hyperkonvergente Infrastrukturen unterstützen und dem Unternehmen das entsprechende Ankoppeln ermöglichen, damit kritische Daten und Anwendungen möglichst hochverfügbar und ausfallsicher arbeiten können.
- Hybride traditionelle Anwendungen: Damit Firmen ihre älteren Anwendungen weiterhin betreiben können, sollte der Provider hybride Cloud-Konstellationen unterstützen.
Wie klug lassen sich Daten wiederherstellen?
Der Fall OHVcloud unterstreicht, dass Unternehmen für ihre Daten und ihre Sicherheit am Ende selbst verantwortlich sind. Denn sind Daten ungesichert, garantiert der Provider keineswegs, dass er sie nach einem Ausfall vollständig wiederherstellen kann. Daher sollten Firmen Daten in der Cloud prinzipiell selbst per Backup sichern: Hier lautet das Stichwort „Shared Responsibility“.
Wie lassen sich im Ernstfall dann ganze Datenbestände oder nur wichtige Teile wiederherstellen? Der Provider sollte granulare Recovery-Prozesse mit unterstützen, damit ein Unternehmen beispielsweise eine virtuelle Maschine oder einzelne Dateien einer virtuellen Applikation granular zurückholen kann, ohne den gesamten Datenbestand herunterladen und neu aufsetzen zu müssen. Das spart viel Zeit und reduziert den Aufwand enorm. Es muss gewährleistet sein, dass die kritischen Anwendungen und Daten priorisiert rekonstruiert werden können, sodass wichtige Dienste nach einem Totalausfall schnell wieder verfügbar sind.
Damit in diesem Stressmoment möglichst alles reibungslos abläuft, sollten folgende Funktionen vom Cloud-Provider in der Business Continuity beziehungsweise in den Recovery-Plänen mit unterstützt werden:
- Automatisierte und orchestrierte Wiederherstellung: So lassen sich ganze, komplexe Multi-Tier Anwendungen per Mausklick vollautomatisch wiederherstellen.
- One-for-One-Orchestrationen: Hierbei muss ein IT-Verantwortlicher die Schritte mit minimalen Befehlen bestätigen, sodass er weiterhin die volle Kontrolle über den Prozess behält.
- Testen des Wiederherstellungsplans: Es ist wichtig, diesen Disaster Recovery-Prozess, genauso wie mögliche Migrationsszenarien auf sichere Weise zu testen, ohne dass der Produktionsbetrieb davon beeinträchtigt wird.
- Herstellerübergreifendes Konzept: Die Recovery-Mechanismen werden gegebenenfalls Anwendungen unterschiedlichster Art auf verschiedensten Plattformen wiederherstellen müssen. Daher ist es essenziell, herstellerübergreifende beziehungsweise unabhängige Disaster Recovery-Mechanismen zu wählen, die die Daten Ende-zu-Ende schützen können.
Wie lässt sich Speicherplatz sparen?
Viele Firmen nutzen bereits Deduplizierung in ihren eigenen Backup-Umgebungen, um die Größe der Backups so klein wie möglich zu halten und Speicherplatz zu sparen. Es wäre ideal, wenn der Cloud-Provider diese Form der Deduplizierung ebenfalls unterstützt. So lassen sich Speicher und Bandbreiten schonen, da die Gesamtmenge der zu speichernden Daten verkleinert wird. Eine Option ist es, dass eine Backup- und Recovery-Lösung diese Intelligenz unabhängig vom Cloud-Provider einbringt, sodass eine Multi-Cloud-Strategie ermöglicht wird.
Außerdem ist es wichtig, unterschiedlich performante Speicher anzubieten. Hochperformante, kritische Anwendungen sollten auf höheren, leistungsfähigeren Speichern laufen, während weniger wichtige Daten auf langsameren und günstigeren Storage-Diensten beim Provider abgelegt werden. Auch die Aktualität des Backups spielt bei dieser Bewertung eine Rolle.
Wie lässt sich der Überblick über die IT-Infrastruktur behalten?
Wer seine Daten in die Cloud migriert, wird sehr wahrscheinlich für lange Zeit eine hybride Infrastrukturarchitektur pflegen. Die Daten werden im Alltag auf all diese verschiedenen Plattformen verteilt, die untereinander gewisse Abhängigkeiten haben. Es ist wichtig, diese Abhängigkeiten zu verstehen und zu überblicken. Denn fällt eine Komponente aus, ist es möglicherweise notwendig, sofort entsprechende Gegenmaßnahmen einzuleiten. Daher ist es wichtig, die gesamte Infrastruktur, den Datenbestand und den Gesundheitszustand kontinuierlich zu überwachen.
Auf diese Weise lassen sich kritische Situationen, wie der Totalausfall eines Cloud-Providers, gut überbrücken, da Daten und Applikationen gesichert sind und im Idealfall per automatisiertem Disaster Recovery-Prozess alle kritischen Dienste auf die Cloud eines anderen Anbieters übertragen werden. So bleibt das Unglück in einem Rechenzentrum auch nur auf dieses beschränkt.
Mehr Informationen finden Sie unter www.veritas.com/de
Fachartikel





Studien

Drei Viertel aller DACH-Unternehmen haben jetzt CISOs – nur wird diese Rolle oft noch missverstanden

AI-Security-Report 2024 verdeutlicht: Deutsche Unternehmen sind mit Cybersecurity-Markt überfordert

Cloud-Transformation & GRC: Die Wolkendecke wird zur Superzelle

Threat Report: Anstieg der Ransomware-Vorfälle durch ERP-Kompromittierung um 400 %

Studie zu PKI und Post-Quanten-Kryptographie verdeutlicht wachsenden Bedarf an digitalem Vertrauen bei DACH-Organisationen
Whitepaper




Unter4Ohren

Datenklassifizierung: Sicherheit, Konformität und Kontrolle

Die Rolle der KI in der IT-Sicherheit
CrowdStrike Global Threat Report 2024 – Einblicke in die aktuelle Bedrohungslandschaft
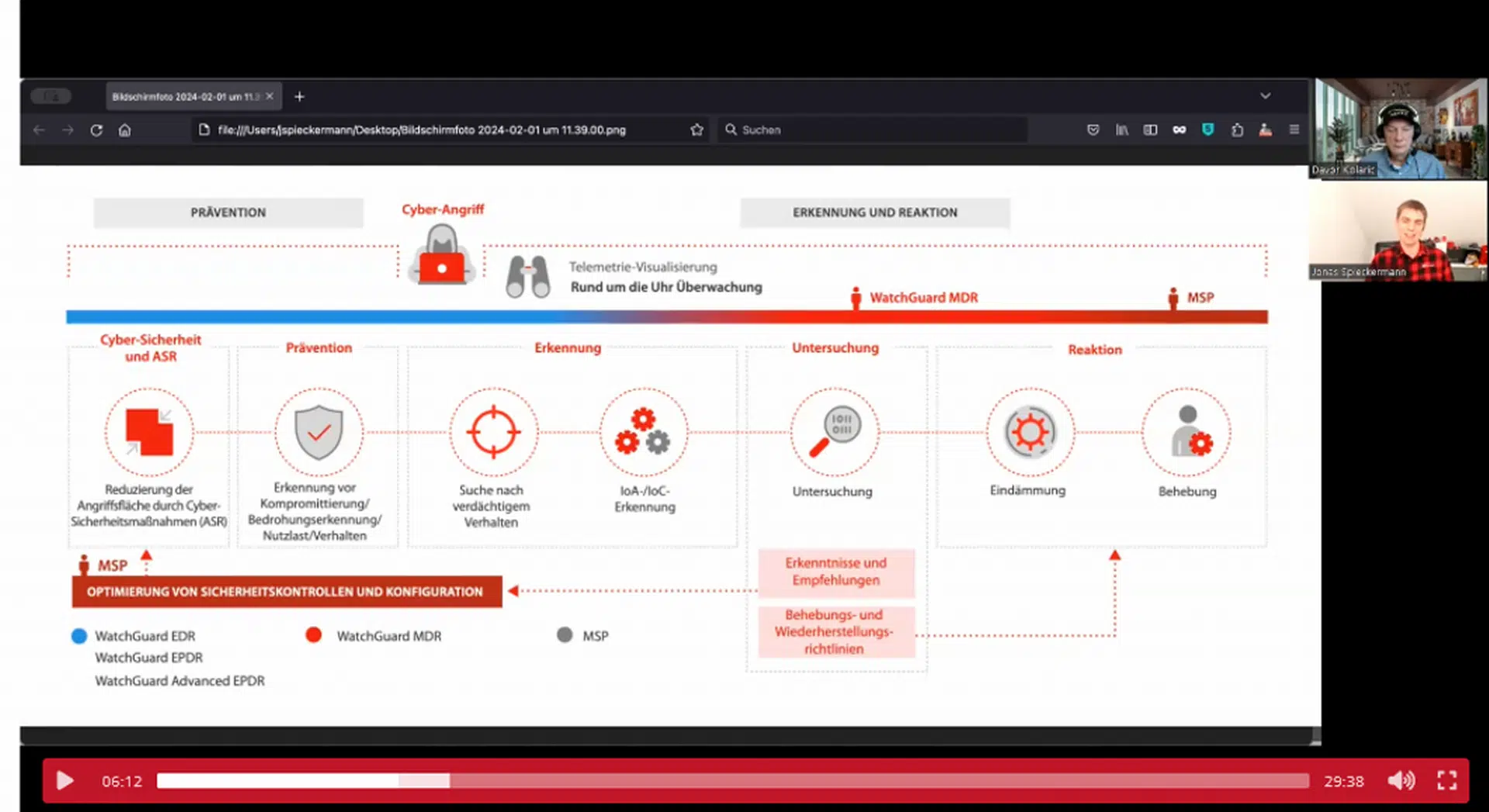
WatchGuard Managed Detection & Response – Erkennung und Reaktion rund um die Uhr ohne Mehraufwand