So sorgen Unternehmen für umfassende Datensicherheit bei cloudnativen Anwendungen
Die Art und Weise, wie Unternehmen Anwendungen entwickeln und ausführen, hat sich dank des einfachen, modularen Container-Ansatzes grundlegend verändert. Angesichts der zunehmenden Verbreitung von Containern und der Tatsache, dass sie die erste Wahl für die Produktionsbereitstellung sind, entwickelt sich Kubernetes zur zentralen Technologie für die Container-Orchestrierung bei der Verwaltung von Produktionsanwendungen. Der Aufwärtstrend von Kubernetes wird wohl weiter anhalten und Container werden sich dementsprechend als Plattform für die Produktionsbereitstellung durchsetzen – noch vor virtuellen Maschinen. Unternehmen müssen Anwendungen unter Umständen mehrmals täglich aktualisieren. Und für diese ständigen Aktualisierungen benötigen sie Microservices, die zu groß für die eingesetzten virtuellen Maschinen sind.
Hinsichtlich Sicherheit und des Schutzes von Daten, ist Kubernetes oft schwer zu kontrollieren und Legacy-Tools und -Prozesse werden den Anforderungen an eine Cloud-native Plattform schlicht nicht gerecht. Im Gegensatz zu ausgereifteren virtuellen Umgebungen gibt es bei Kubernetes weniger Sicherheitsvorgaben, die gewährleisten, dass neue Workloads für den Schutz von Daten ordnungsgemäß konfiguriert werden. Entsprechend müssen IT-Teams zahlreiche wichtige Faktoren berücksichtigen, um die Datensicherheit im Zusammenhang mit Kubernetes zu optimieren. Unter anderem betrifft dies den Schutz von Container-Pipelines, Anwendungen (stateful und stateless) sowie die organisatorische Abstimmung von Cloud-Services.
Schutz für Container-Pipelines
Container-Images fungieren als permanente Ebenen des Installations- und Konfigurationsprozesses. Anstatt nur das Endergebnis – das Container-Image – zu erfassen, ist es sinnvoller, die Technologie zu schützen, die die Images erzeugt, einschließlich aller Konfigurationsskripte (wie Dockerfile-und Kubernetes-YAML-Dateien) und der Dokumentation. Dies wird auch als Pipeline bezeichnet. Die Anforderungen an die Datensicherheit für Systeme, die die Container als Teil der CI/CD-Pipeline erstellen, werden jedoch häufig nicht beachtet. Dazu gehören Tools wie Build-Server und Code- und Artefakt-Repositorys, die Container und Anwendungsversionen speichern. Indem diese Workloads geschützt werden, wird auch ein Großteil der Pipeline, die Container-Images generiert, automatisch effektiver geschützt.
Statusunabhängige und statusabhängige Anwendungen
Der Schutz persistenter Anwendungsdaten ist ein weiteres wichtiges Puzzleteil. Zur Erklärung: In den früheren Phasen der Entwicklung der Container-Technologie wurde oft behauptet, dass Container nur für statusunabhängige Workloads geeignet seien und dass das Speichern von Daten in einem Container nicht möglich sei. Die Technologien haben sich mittlerweile weiterentwickelt und heute unterstützen sowohl die zugrunde liegende Laufzeitumgebung für Container als auch Kubernetes selbst eine Vielzahl von Workloads, einschließlich statusabhängiger Anwendungen. Während die Container-Images selbst nur vorübergehend bestehen und sämtliche Änderungen am Dateisystem nach dem Löschen des ausgeführten Containers verloren gehen, gibt es nun verschiedene Möglichkeiten, einen Container mit statusabhängigem, persistentem Speicher zu versehen. Selbst Speicher-Arrays für Unternehmen, die bereits in lokalen Rechenzentren im Einsatz sind, können oft statusabhängigen Speicher für Kubernetes-Cluster bereitstellen. Bei der Datensicherheitsstrategie –und der Wahl der Plattform – müssen diese Funktionen berücksichtigt werden.
Organisatorische Abstimmung von Cloud-Services
Viele Unternehmen nutzen Cloud-Services für die Objekt- oder Dateispeicherung, weil sie sich schnell und einfach implementieren und verwalten lassen. Allerdings hat dies auch Nachteile, nicht zuletzt, weil die Daten nicht der Kontrolle der Verantwortlichen für Datensicherheit unterliegen. So kann das Vorhandensein nicht sichtbarer persistenter Speicherressourcen dazu führen, dass Daten ungeschützt bleiben – ohne Sicherung, Notfallwiederherstellung und Anwendungsmobilität. Daher ist es wichtig zu erkennen, dass die Verwaltung von Cloud-Speicher ebenso schwierig ist wie die Verwaltung von unternehmenseigenem lokalem Speicher. Unternehmen brauchen einen konsistenten Ansatz für den Zugriff auf und die Verwaltung von Cloud-Speicher, damit Entwickler die von ihnen benötigten Services nutzen können, während ihre Kollegen den Überblick behalten, die Sicherheit wahren und ihrer Verantwortung für den Schutz von Daten nachkommen können.
Bewältigung der Herausforderungen im Bereich Datensicherheit und Notfallwiederherstellung
Bei der Bewältigung dieser Herausforderungen müssen Unternehmen Datensicherheits- und Notfallwiederherstellungsplattformen einsetzen, die für ein ausgewogenes Verhältnis zwischen Verfügbarkeit und Ausfallsicherheit und der Notwendigkeit sorgen, eine effektive Entwicklungsgeschwindigkeit für Unternehmensanwendungen und -services zu ermöglichen. So können sie ihre Container schützen, wiederherstellen und verschieben, ohne zusätzliche Schritte, Tools und Richtlinien in den DevOps-Prozess einzubinden.
Beispielsweise hat die Minimierung von Anwendungsausfallzeiten und Datenverlusten für jede Anwendung Priorität, insbesondere für containerisierte Anwendungen. Die Verwendung einer nativen Lösung ermöglicht die Umsetzung einer „Data Protection as Code“-Strategie, bei der die Vorgänge für Datensicherheit und Notfallwiederherstellung von vornherein in den Lebenszyklus der Anwendungsentwicklung integriert werden und die Anwendungen von Anfang an geschützt sind. Unternehmen, die diesen Ansatz verfolgen, können die Ausfallsicherheit ihrer Anwendungen gewährleisten, ohne die Geschwindigkeit, Skalierbarkeit und Agilität ihrer containerisierten Anwendungen zu beeinträchtigen.
Darüber hinaus bietet der Einsatz von CDP-Technologie (Continuous Data Protection) den Benutzern die Sicherheit, einfach zu einem früheren Checkpoint zurückkehren zu können, was den RPO (Recovery Point Objective) minimiert. Dieser Ansatz ist zum einen mit nur geringfügigen Unterbrechungen verbunden und bietet zum anderen eine viel größere Flexibilität und höhere Verfügbarkeit als ein herkömmlicher Ansatz für den Schutz von Daten, der den Produktionssystemen durch die Verwendung von Snapshots möglicherweise um Stunden hinterherhinkt und zu einer lückenhaften Datensicherung führen kann. Im Gegensatz dazu ist CDP seit langem der De-facto-Standard im VM-Bereich und entwickelt sich schnell zur effektivsten Option für Container.
Herstellerbindung bei der Wahl der Plattform vermeiden
Bei der Abwägung all dieser Aspekte empfiehlt es sich grundsätzlich, die Bindung an einen bestimmten Anbieter zu vermeiden. Die Wahl einer Lösung zum Schutz von Daten sollte davon abhängen, ob sie alle Kubernetes-Plattformen für Unternehmen unterstützt und, ob sie es ermöglicht, Daten dorthin zu verschieben, wo die Anwendungen ausgeführt werden müssen, ohne an eine bestimmte Speicherplattform oder einen Cloud-Anbieter gebunden zu sein. Nur so bleiben die persistenten Daten genauso mobil wie die Container selbst.
Fazit: Daten schützen ohne Flexibilität zu verlieren
Durch die Implementierung einer Strategie und einer Plattform, die diese Herausforderungen effektiv angehen, können Unternehmen den Schutz der Daten priorisieren, ohne die Freiheiten einzuschränken, die Kubernetes Entwicklern bei der Erstellung, Entwicklung und schnellen Ausführung von Anwendungen eröffnet. Unternehmen können Anwendungen einfach schützen, wiederherstellen und verschieben, um ein intelligentes Datenmanagement zu erreichen und die Softwareentwicklung und -bereitstellung zu beschleunigen. Im Gegenzug können sie eine maximale Rendite aus diesem immer wichtiger werdenden Bereich ihrer Technologieinvestitionen erzielen.
Von Reinhard Zimmer, Zerto
Fachartikel





Studien

Drei Viertel aller DACH-Unternehmen haben jetzt CISOs – nur wird diese Rolle oft noch missverstanden

AI-Security-Report 2024 verdeutlicht: Deutsche Unternehmen sind mit Cybersecurity-Markt überfordert

Cloud-Transformation & GRC: Die Wolkendecke wird zur Superzelle

Threat Report: Anstieg der Ransomware-Vorfälle durch ERP-Kompromittierung um 400 %

Studie zu PKI und Post-Quanten-Kryptographie verdeutlicht wachsenden Bedarf an digitalem Vertrauen bei DACH-Organisationen
Whitepaper




Unter4Ohren

Datenklassifizierung: Sicherheit, Konformität und Kontrolle

Die Rolle der KI in der IT-Sicherheit
CrowdStrike Global Threat Report 2024 – Einblicke in die aktuelle Bedrohungslandschaft
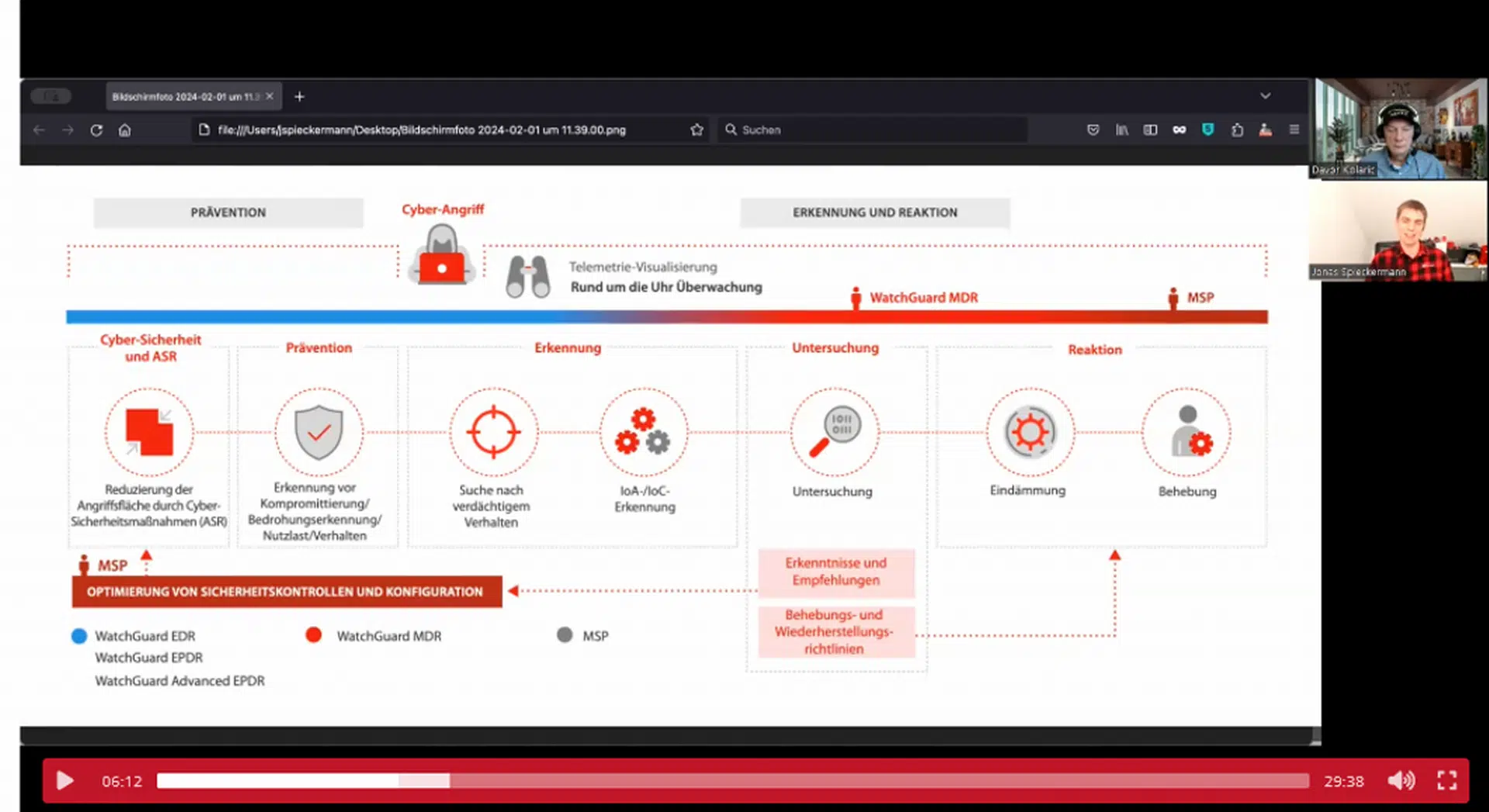
WatchGuard Managed Detection & Response – Erkennung und Reaktion rund um die Uhr ohne Mehraufwand