





3. März 2026
Gcore integriert das Open-Source-Framework NVIDIA Dynamo als vollständig verwalteten Dienst und adressiert damit zentrale Effizienzprobleme moderner LLM-Inferenz – von schwankender GPU-Auslastung bis hin zu kostspieliger KV-Cache-Neuberechnung.
Ausgangslage: Inferenz im Großmaßstab fordert neue Ansätze
Das Jahr 2026 markiert eine Phase, in der KI-Inferenz zum zentralen Arbeitsgebiet von Rechenzentren avanciert. Wachsende Modellgröße, komplexere Anwendungsfälle und steigende Nutzerzahlen setzen bestehende GPU-Architekturen unter Druck. Selbst moderate Auslastungslücken übersetzen sich heute direkt in messbare Latenzerhöhungen und sinkenden Return on Investment.
Gcore, Anbieter von Cloud- und Inferenzlösungen, hat deshalb das von NVIDIA entwickelte Open-Source-Framework Dynamo in sein Portfolio aufgenommen – als managed, per Mausklick aktivierbarer Dienst.
Fünf strukturelle Probleme moderner Inferenz
Typische Inferenz-Workloads kämpfen heute mit einem Bündel systemischer Schwachstellen:
- Ungleichmäßige GPU-Auslastung: Während der Vorfüllphase (Prefill) kann die GPU-Last über 90 Prozent steigen. In der Dekodierungsphase fällt sie auf bis zu zehn Prozent – weil nachgelagerte Pipeline-Schritte als Flaschenhals wirken.
- Starre Ressourcenzuweisung: Herkömmliche Systeme weisen GPUs statisch zu, unabhängig davon, wie stark die tatsächliche Nachfrage schwankt. Das erzeugt Leerlaufkapazitäten und Kostenverluste.
- Wiederholte KV-Cache-Berechnung: Fehlt eine effiziente Speicher- und Wiederverwendungslogik, müssen Key-Value-Werte wiederholt neu berechnet werden – mit entsprechendem Mehraufwand bei Rechenzeit und Latenz.
- Speicherengpässe bei langen Sequenzen: Große Modelle mit ausgedehnten Prompts oder hohen Batchgrößen belasten den GPU-Speicher erheblich, begrenzen die Parallelverarbeitung und können Cache-Verdrängungen auslösen.
- Ineffiziente Datenkommunikation: Gängige Kommunikationsbibliotheken wurden für stabile Trainingsworkloads konzipiert, nicht für die asynchrone, tokenweise Inferenz. Die Folge: Synchronisationsverzögerungen und schlechte Ausnutzung der Verbindungsbandbreite.

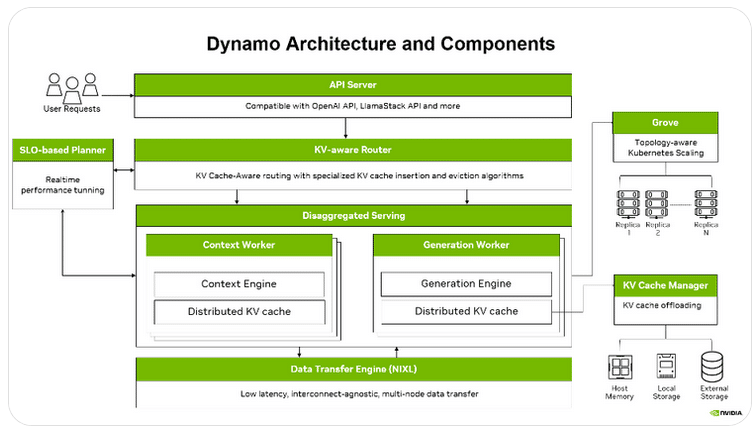
Dynamos Architektur: drei Kernmechanismen
Anstatt auf GPU-Kernel-Optimierungen zu setzen, greift Dynamo auf der Systemebene ein. Die Architektur besteht aus drei modular kombinierbaren Bausteinen, die sich je nach Anforderung aktivieren oder deaktivieren lassen.
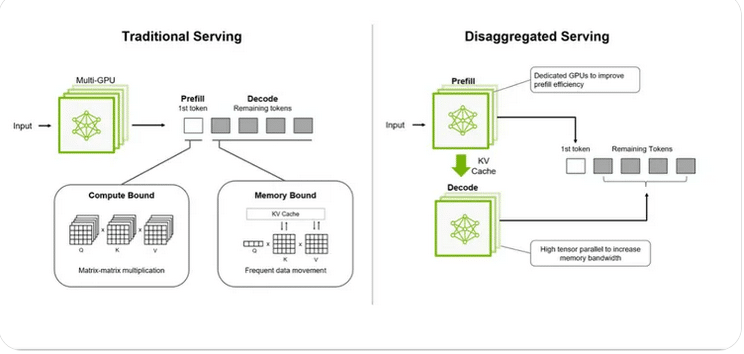
1 · Disaggregiertes Serving
Dynamo erlaubt die gezielte Verteilung von Prefill- und Dekodierungsphasen auf unterschiedliche GPU-Typen. Da das Vorfüllen rechenintensiver ist, während die Dekodierung primär speicherbandbreitengebunden läuft, können spezialisierte Hardwareprofile pro Phase zugewiesen werden. Die Trennung beider Phasen eröffnet zusätzliche Parallelverarbeitungspotenziale und senkt den Anteil ungenutzter GPU-Ressourcen spürbar.
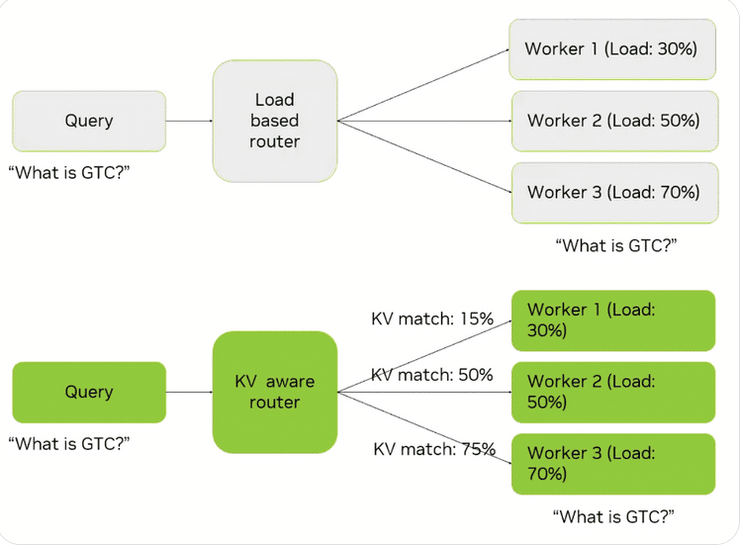
2 · KV-Cache-bewusstes Routing
Jede eingehende Anfrage wird an denjenigen Worker weitergeleitet, der die höchste Cache-Trefferwahrscheinlichkeit bei gleichzeitig akzeptabler Auslastung bietet. Dazu vergibt das System für jeden Worker eine Punktzahl, die Auslastung und Cache-Trefferrate gewichtet. Ergebnis: Die End-to-End-Latenz sinkt um bis zu 50 Prozent gegenüber herkömmlichem Round-Robin-Routing.
Weitere Vorteile dieser Cache-Logik:
- KV-Cache-Inhalte lassen sich bedarfsgesteuert laden und vorabrufeln – relevant für Multi-Turn-Chats und lange Kontextfenster.
- Bei agentischen Anwendungen, in denen Tool-Aufrufe traditionell hohe Wartezeiten erzeugen, reduziert zeitgesteuertes Aus- und Einlagern die Verzögerung messbar.
3 · NIXL: Hochdurchsatz-Datentransfer
Die NVIDIA Inference Transfer Library (NIXL) bildet das Kommunikations-Rückgrat von Dynamo. Als Punkt-zu-Punkt-Bibliothek mit geringer Latenz wurde sie explizit für die asynchronen, tokenweisen Muster der LLM-Inferenz entworfen – nicht für die blockorientierte Datenbewegung beim Training. NIXL ermöglicht nicht blockierende, nicht zusammenhängende Datentransfers über verschiedene Speicherebenen hinweg und senkt die Time-to-First-Token auch unabhängig vom Rest des Dynamo-Stacks um den Faktor 1,8.
Anstatt einzelne Pods zu skalieren, definiert Grove den gesamten Serving-Stack als eine einzige logische Bereitstellungseinheit – mit koordinierter Startreihenfolge, topologiebewusster Platzierung und mehrstufiger Autoskalierung.
4 · Kubernetes-Orchestrierung mit Grove
Als integrierte Komponente enthält Dynamo NVIDIA Grove, eine Kubernetes-native API für die Orchestrierung vielschichtiger KI-Inferenzsysteme. Grove behandelt Prefill-, Dekodierungs-, Routing- und sonstige Rollen als einheitliche, benutzerdefinierte Ressource. Unterstützt werden hierarchisches Gang-Scheduling, topologiebewusste Pod-Platzierung, mehrstufige Autoskalierung sowie eine explizit konfigurierbare Startreihenfolge. Das reduziert Betriebskomplexität und verbessert Zuverlässigkeit – von einzelnen Replikaten bis zum Rechenzentrumsmaßstab.
Für welche Anwendungsfälle lohnt sich Dynamo?
Grundsätzlich können alle Inferenz-Workloads von Dynamos Systemverbesserungen profitieren. Den größten Mehrwert entfaltet die Lösung jedoch in ressourcenintensiven Szenarien:
- Frontier-MoE-Reasoning-Modelle, bei denen Routing-Entscheidungen auf Experten-Ebene eng mit der Inferenzplanung verzahnt sind
- Multi-Turn-Chats mit langen Kontextfenstern, da sich die Vorteile des KV-Cache-Managements über mehrere Gesprächsrunden kumulieren
- Agentische Pipelines, die LLMs mit externen Werkzeugen und Diensten kombinieren und auf kurze Tool-Call-Latenzen angewiesen sind
- Verteilte Multi-GPU-Deployments über mehrere Knoten oder GPU-Typen, bei denen Auslastungskoordination und Lastverteilung entscheidend sind
Hinweis für Single-GPU-Deployments
Auch wer aktuell auf einer einzelnen GPU betreibt, profitiert von Dynamo: Das Framework liefert eine zukunftsfähige Serving-Architektur, ohne dass bestehende Modelle oder Pipelines neu aufgesetzt werden müssen.
Gcore: Dynamo als One-Click Managed Service
Gcore stellt Dynamo ab sofort über seine Produkte Gcore Inference und Everywhere AI bereit. Das Deployment reduziert sich auf die Auswahl des gewünschten Modells und einen einzigen Klick – sämtliche Konfiguration von Routing-Logik, KV-Cache-Management und GPU-Scheduling übernimmt Gcore im Hintergrund. Der Dienst ist in öffentlichen Cloud-, privaten Cloud-, Hybrid- und On-Premises-Umgebungen verfügbar.
NVIDIA entwickelt Dynamo aktiv weiter. Gcore sichert zu, neue Funktionen und Updates mit identischer Deployment-Einfachheit an seine Inferenzkunden weiterzugeben.
Der vollständige Quellcode von NVIDIA Dynamo ist auf GitHub einsehbar und steht der Open-Source-Community zur Mitarbeit offen.
Grafiken Quelle: GCore
Weitere Beiträge von GCore:
Bild/Quelle: https://depositphotos.com/de/home.html


Fachartikel

NVIDIA Dynamo: Bis zu sechsfacher GPU-Durchsatz per One-Click-Deployment

Microsoft OAuth-Phishing: Wie Angreifer Standard-Protokollverhalten für Malware-Kampagnen nutzen

Massenangriff auf SonicWall-Firewalls: 4.300 IP-Adressen scannen gezielt VPN-Infrastrukturen

Phishing-Kampagnen missbrauchen .arpa-Domains: Neue Methode umgeht Sicherheitssysteme

Google API-Schlüssel als ungewollte Gemini-Zugangsdaten
Studien

KI als Werkzeug für schnelle, kostengünstige Cyberangriffe

KI beschleunigt Cyberangriffe: IBM X-Force warnt vor wachsenden Schwachstellen in Unternehmen

Finanzsektor unterschätzt Cyber-Risiken: Studie offenbart strukturelle Defizite in der IT-Sicherheit

CrowdStrike Global Threat Report 2026: KI beschleunigt Cyberangriffe und weitet Angriffsflächen aus

IT-Sicherheit in Großbritannien: Hohe Vorfallsquoten, steigende Budgets – doch der Wandel stockt
Whitepaper

EBA-Folgebericht: Fortschritte bei IKT-Risikoaufsicht unter DORA – weitere Harmonisierung nötig

Böswillige KI-Nutzung erkennen und verhindern: Anthropics neuer Bedrohungsbericht mit Fallstudien

Third Party Risk Management – auch das Procurement benötigt technische Unterstützung

EU-Toolbox für IKT-Lieferkettensicherheit: Gemeinsamer Rahmen zur Risikominderung

EU-Behörden stärken Cybersicherheit: CERT-EU und ENISA veröffentlichen neue Rahmenwerke
Hamsterrad-Rebell

Incident Response Retainer – worauf sollte man achten?

KI‑basierte E‑Mail‑Angriffe: Einfach gestartet, kaum zu stoppen

NIS2: „Zum Glück gezwungen“ – mit OKR-basiertem Vorgehen zum nachhaltigen Erfolg

Cyberversicherung ohne Datenbasis? Warum CIOs und CISOs jetzt auf quantifizierbare Risikomodelle setzen müssen
