





1. Februar 2026
Eine neue Klasse von Angriffen bedroht Unternehmen, die Machine-Learning-Modelle über APIs bereitstellen. Dabei benötigen die Angreifer keine besonderen Privilegien – nur den gleichen Zugang, über den auch jeder normale Nutzer verfügt. Ein Forschungsteam von Praetorian zeigt, wie sich ein proprietäres Modell mit verhältnismäßig geringem Aufwand nachbilden lässt.
Der Angriff in der Praxis
Unternehmen investieren erhebliche Mittel in die Entwicklung eigener Machine-Learning-Modelle – von der medizinischen Bildanalyse über Betrugserkennungssysteme bis hin zu Empfehlungsalgorithmen. Diese Modelle verkörpern Monate Forschungsarbeit, spezialisierte Datensätze und akkumuliertes Fachwissen.
Genau diese Modelle können über einen Angriff repliziert werden, der unter dem Begriff Modellextraktion bekannt ist. Der Ablauf ist methodisch und verhältnismäßig einfach: Ein Angreifer sendet zahlreiche Eingaben an die öffentliche API eines Zielmodells, sammelt die zugehörigen Ausgaben und trainiert damit ein eigenes Ersatzmodell. Weder die Architektur des Originalmodells noch die Trainingsdaten müssen dabei bekannt sein.
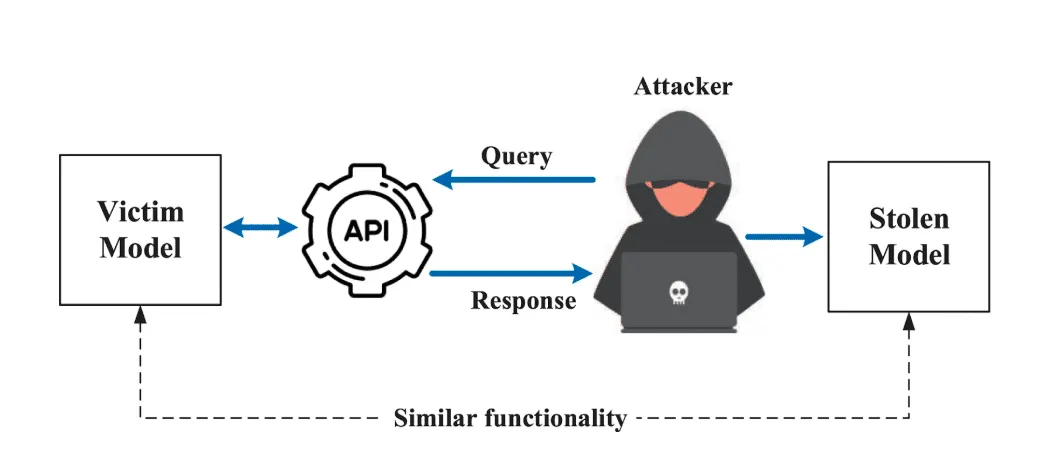
Grafik Quelle: Praetorian
Warum Wahrscheinlichkeiten den Unterschied machen
Der Wirkungsmechanismus des Angriffs liegt in den Ausgaben selbst. Viele ML-Systeme geben nicht nur eine einzelne Vorhersage zurück, sondern eine Verteilung über mehrere Kategorien – sogenannte weiche Wahrscheinlichkeiten. Ein Bildklassifikator, der ein Foto als „80 Prozent Sneaker, 15 Prozent Stiefeletten, 5 Prozent Sandalen“ einordnet, gibt dabei deutlich mehr Informationen preis als ein System, das schlicht „Sneaker“ zurückgibt.
Diese Verteilungen offenbaren, wie das Modell Zusammenhänge zwischen Kategorien gewichtet und wo es unsicher wird. Genau diese Nuancen lassen sich systematisch ausnützen, um eine wirkungsvolle Replik zu trainieren – ein Verfahren, das in der Fachwelt als Wissensdestillation bezeichnet wird.
Das Angriffsmodell von Praetorian
Das Forschungsteam von Praetorian hat einen vollständig reproduzierbaren Angriff auf Basis des Fashion-MNIST-Datensatzes vorgestellt. Das Zielmodell war ein CNN (Convolutional Neural Network) mit drei Faltungsschichten, einer Modelldatei von etwa 1,5 Megabyte und einer Validierungsgenauigkeit von 91 Prozent – ein realistisches Abbild eines proprietären Bildklassifikators.
Die Angreifer verfügten dabei über minimale Informationen: keinen Zugang zu Trainingsdaten und keine Kenntnis der Modellastruktur. Sie konnten lediglich Bilder einsenden und die Softmax-Wahrscheinlichkeiten beobachten.
Der Angriff verlief in drei Phasen. Zunächst wurde ein Datensatz aus 1.000 Abfragen gesammelt, wobei die Ausgaben des Zielmodells als Trainingsinformation genutzt wurden – die tatsächlichen Labels spielten dabei keine Rolle. Anschließend wurde ein sogenanntes Schülermodell mit einer bewusst anderen und einfacheren Architektur trainiert, um nachzuweisen, dass die Extraktion nicht von einer Kenntnnis der Zielstruktur abhängt. Die Methode der Wissensdestillation mit einem Temperaturparameter ermöglichte es, die Wahrscheinlichkeitsverteilungen des Zielmodells gezielter nachzulernen.
Nach einem Training von 50 Epochen erzielte unser gestohlenes Modell folgende Ergebnisse:

Ergebnisse: 80 Prozent Verhaltensübereinstimmung
Nach 20 Trainingsepoche erreichte das Ersatzmodell eine Genauigkeit von 80,1 Prozent. Noch relevanter war die sogenannte Übereinstimmungsrate – der Anteil der Eingaben, bei denen Ersatz- und Originalmodell zur gleichen Vorhersage kommen. Diese lag bei 80,8 Prozent, bedeutet also, dass bei vier von fünf Bildern beide Modelle identisch reagieren.
Besonders aufschlussreich war, dass die beiden Modelle auch ähnliche Fehler machten. Wenn das Ersatzmodell eine Fehlklassifikation lieferte, war es häufig genau dieselbe, die auch das Zielmodell vornahm. Die Verwechslungsmatrizen beider Systeme zeigten identische Schwachpunkte – etwa die Unterscheidung zwischen Hemden und T-Shirts oder zwischen Pullovern und Mängeln.
Bei eindeutigen Kategorien wie Hosen, Taschen oder Sneakern lag die Übereinstimmung gar über 90 Prozent. Bei mehrdeutigen Kategorien war die Rate geringer, allerdings folgten die Fehler konsistent den gleichen Mustern wie beim Zielmodell.
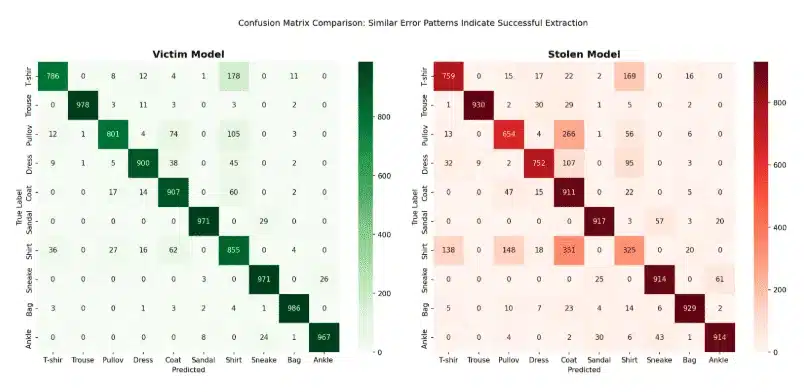
Grafik Quelle: Praetorian
Nachgelagerte Risiken
Die Modellextraktion ist kein Endprodukt, sondern eröffnet weitere Angriffsvektoren. Ein gestohlenes Modell kann lokal genutzt werden, um gegnerische Beispiele zu entwickeln – Eingaben, die das Originalsystem systematisch zu Fehlvorhersagen bringen. Das gestohlene Modell kann zudem als Grundlage für günstigere Ersatzdienste dienen, die den ursprünglichen Anbieter auf dem Markt unterbieten. Selbst eine unvollständige Extraktion liefert Informationen darüber, welche Merkmale ein Wettbewerber in seinen Systemen bevorzugt.
Der strukturelle Schwachpunkt
Viele Unternehmen gehen davon aus, dass es reicht, die Modellgewichte geheim zu halten. Diese Annahme greift jedoch zu kurz. Das Verhalten eines Modells ist das Modell – jede API-Antwort gibt ein Trainingsbeispiel für eine Replik preis. Der Schutz der Gewichte bei gleichzeitiger Freigabe unbegrenzter Abfragen verlegt die Angriffsfläche vom direkten Dateizugriff zur Verhaltensreplikation, schließt sie aber nicht aus.
Geeignete Abwehrmaßnahmen
Praetorian empfiehlt mehrere Maßnahmen, um das Risiko einer Extraktion zu reduzieren. Eine effektive Ratenbegrenzung kann die für eine Replikation nötigen Massenabfragen verhindern – der beschriebene Angriff nutzte 1.000 Abfragen, eine Anzahl, die bei geeigneter Überwachung auffallen sollte. Ausgabeverzerrung durch das Hinzufügen von kalibriertem Rauschen zu den Konfidenzwerten verschlechtert die für die Destillation verfügbaren Informationen, ohne die Nützlichkeit für legitime Nutzer wesentlich zu beeinträchtigen. Die Vorhersageverkürzung – also das Zurückgeben nur der Top-k-Kategorien oder harter Labels statt vollständiger Wahrscheinlichkeitsverteilungen – reduziert pro Abfrage den Informationsgehalt erheblich. Ergänzend sollte eine Verhaltensüberwachung eingesetzt werden, die systematische Abfragemuster erkennt, die sich von typischen Nutzungsgewohnheiten abheben. Schließlich ermöglichen Wasserzeichen – erkennbare Muster, die dem Modellverhalten eingebettet werden – eine spätere Zuordnung, falls ein extrahiertes Modell auftaucht.
Fazit
Der Angriff auf proprietäre ML-Modelle über APIs erfordert weder speziellen Zugang noch Insider-Wissen. Mit einer überschaubaren Anzahl von Abfragen und einer bewusst vereinfachten Architektur war es möglich, das Verhalten eines kommerziellen Modells in hohem Maße nachzubilden. Die Schlussfolgerung der Forscher ist eindeutig: Wer sein Modell über eine API veröffentlicht, gibt gleichzeitig Informationen preis, die in der Summe eine funktionsfähige Kopie ermöglichen. Gezielte Abwehrmaßnahmen sind daher nicht optional, sondern erforderlich.
Quelle: Praetorian – praetorian.com
Vielleicht spannend für Sie
Bild/Quelle: https://depositphotos.com/de/home.html

Fachartikel

Keepit KI-Integration: Warum Backup-Systeme andere KI-Regeln brauchen

Phishing über LiveChat: Wie Angreifer SaaS-Plattformen für Datendiebstahl nutzen
XWorm 7.1 und Remcos RAT: Angreifer setzen auf dateilose Techniken und Windows-Bordmittel

KI im Cyberkonflikt: Warum Verteidiger die Nase vorn haben

KadNap: Wie ein neues Botnetz tausende Asus-Router als Proxy-Knoten missbraucht
Studien

Drucksicherheit bleibt in vielen KMU ein vernachlässigter Bereich

Sieben Regierungen einigen sich auf 6G-Sicherheitsrahmen

Lieferkettenkollaps und Internetausfall: Unternehmen rechnen mit dem Unwahrscheinlichen

KI als Werkzeug für schnelle, kostengünstige Cyberangriffe

KI beschleunigt Cyberangriffe: IBM X-Force warnt vor wachsenden Schwachstellen in Unternehmen
Whitepaper

KI-Betrug: Interpol warnt vor industrialisierter Finanzkriminalität – 4,5-fach profitabler

Cloudflare Threat Report 2026: Ransomware beginnt mit dem Login – KI und Botnetze treiben die Industrialisierung von Cyberangriffen

EBA-Folgebericht: Fortschritte bei IKT-Risikoaufsicht unter DORA – weitere Harmonisierung nötig

Böswillige KI-Nutzung erkennen und verhindern: Anthropics neuer Bedrohungsbericht mit Fallstudien

Third Party Risk Management – auch das Procurement benötigt technische Unterstützung
Hamsterrad-Rebell

Sichere Enterprise Browser und Application Delivery für moderne IT-Organisationen
Sicherer Remote-Zugriff (SRA) für Operational Technology (OT) und industrielle Steuerungs- und Produktionssysteme (ICS) – Teil 2

Incident Response Retainer – worauf sollte man achten?

KI‑basierte E‑Mail‑Angriffe: Einfach gestartet, kaum zu stoppen
