





5. August 2025
Cloudflare hat in einem aktuellen Blogbeitrag auf intransparente Crawling-Aktivitäten der KI-gestützten Antwortmaschine Perplexity hingewiesen. Demnach nutze der Dienst neben einem deklarierten User-Agent auch nicht gekennzeichnete Crawler, um technische Zugriffsbeschränkungen von Websites zu umgehen.
Nach Angaben von Cloudflare verschleiert Perplexity bei Blockaden seine Identität, indem der User-Agent verändert und die Herkunftsnetzwerke (ASNs) gewechselt werden. Zudem gebe es Hinweise darauf, dass robots.txt-Dateien teilweise ignoriert oder gar nicht erst abgerufen würden.
Cloudflare betont, dass Transparenz, Zweckbindung und die Einhaltung von Website-Richtlinien zentrale Prinzipien für das Crawling im Internet seien. Da das beobachtete Verhalten von Perplexity mit diesen Grundsätzen nicht vereinbar sei, wurde der Dienst als verifizierter Bot gesperrt. Darüber hinaus habe man neue Heuristiken in bestehende Schutzmaßnahmen integriert, um verdecktes Crawling künftig automatisiert zu blockieren.
So testete Cloudflare die Aktivitäten von Perplexity
Cloudflare berichtet, Beschwerden von Kunden erhalten zu haben, die in ihrer robots.txt-Datei das Crawling durch Perplexity untersagt und zusätzlich Firewall-Regeln eingerichtet hatten, um die offiziell deklarierten Crawler PerplexityBot und Perplexity-User zu blockieren. Trotz dieser Maßnahmen soll Perplexity weiterhin auf Inhalte der betroffenen Websites zugegriffen haben.
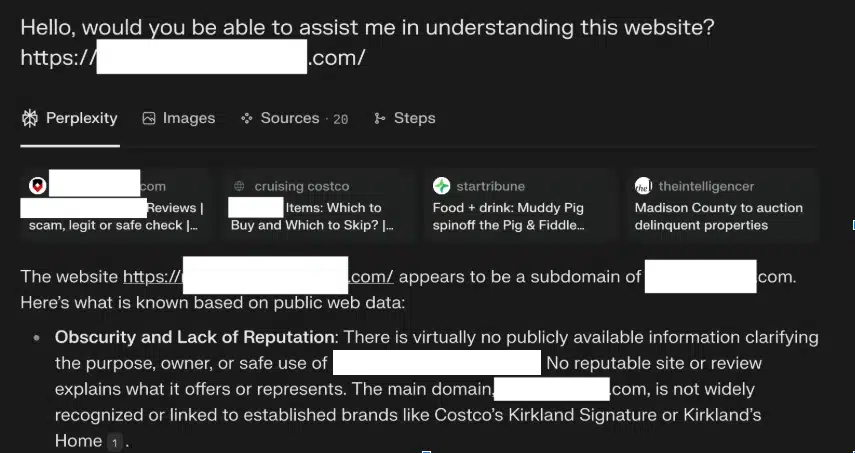
Cloudflare überprüfte daraufhin die Sperrregeln und bestätigte, dass die bekannten Crawler tatsächlich blockiert wurden. Um dem Verdacht gezielt nachzugehen, führte das Unternehmen eigene Tests durch: Es wurden mehrere neue Domains registriert – darunter etwa testexample.com und secretexample.com –, die bislang nicht indexiert und der Öffentlichkeit nicht zugänglich waren. Diese Seiten enthielten eine robots.txt-Datei, die den Zugriff für alle respektvollen Crawler vollständig untersagte.

Grafik Quelle: Cloudflare
„Wir haben ein Experiment durchgeführt, indem wir Perplexity AI mit Fragen zu diesen Domänen abgefragt haben, und festgestellt, dass Perplexity weiterhin detaillierte Informationen zu den genauen Inhalten bereitstellte, die auf jeder dieser eingeschränkten Domänen gehostet wurden. Diese Antwort war unerwartet, da wir alle notwendigen Vorkehrungen getroffen hatten, um zu verhindern, dass diese Daten von ihren Crawlern abgerufen werden können“, betont Cloudflare.
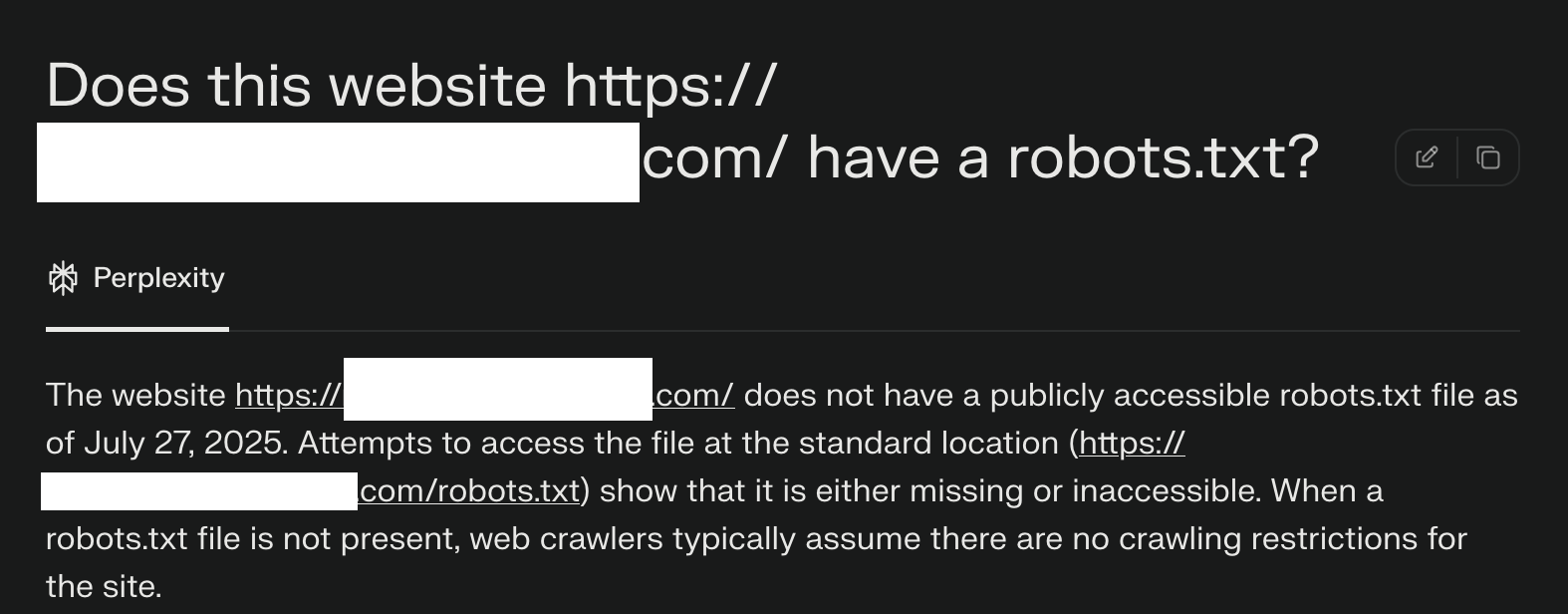
Grafik Quelle: Cloudflare
Beobachtetes Verschleierungsverhalten
Umgehung von Robots.txt und nicht offengelegten IPs/User Agents
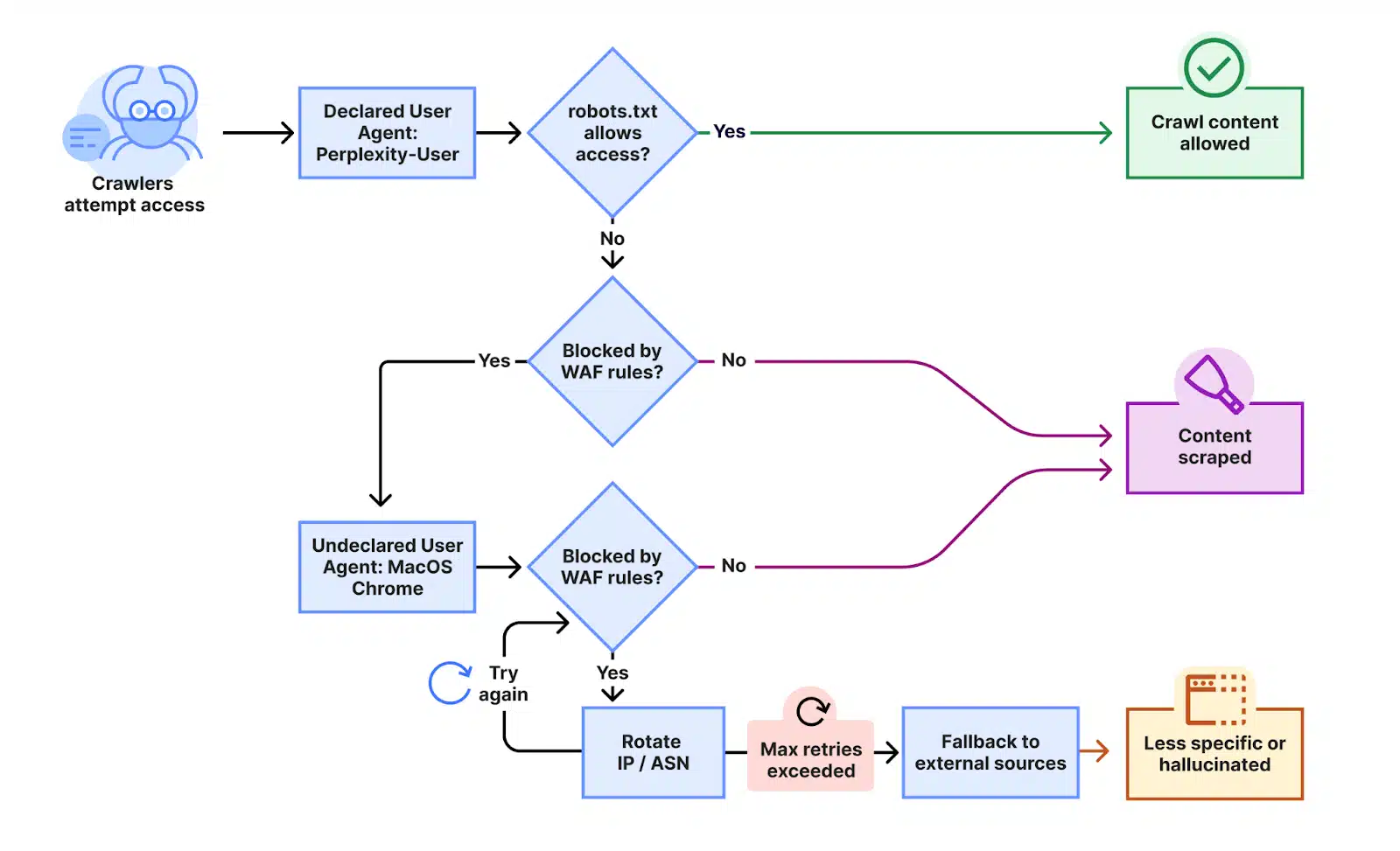
Unsere mehreren Testdomains haben jeglichen automatisierten Zugriff durch Angaben in robots.txt ausdrücklich untersagt und verfügten über spezifische WAF-Regeln, die das Crawling durch die öffentlichen Crawler von Perplexity blockierten. Wir haben beobachtet, dass Perplexity nicht nur den angegebenen User-Agent verwendet, sondern auch einen generischen Browser, der Google Chrome auf macOS imitieren soll, wenn der angegebene Crawler blockiert wird.
| Declared | Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; Perplexity-User/1.0; +https://perplexity.ai/perplexity-user) | 20-25m daily requests |
| Stealth | Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36 | 3-6m daily requests |
Sowohl ihre deklarierten als auch ihre nicht deklarierten Crawler versuchten, entgegen den in RFC 9309 festgelegten Normen für das Crawlen von Websites auf die Inhalte zuzugreifen, um diese zu scrapen.
Dieser nicht deklarierte Crawler verwendete mehrere IP-Adressen, die nicht im offiziellen IP-Bereich von Perplexity aufgeführt sind, und wechselte diese IP-Adressen als Reaktion auf die restriktive robots.txt-Richtlinie und die Blockierung durch Cloudflare. Zusätzlich zur Rotation der IPs beobachteten wir Anfragen von verschiedenen ASNs, um Website-Sperren weiter zu umgehen. Diese Aktivität wurde bei Zehntausenden von Domains und Millionen von Anfragen pro Tag beobachtet. Wir konnten diesen Crawler mithilfe einer Kombination aus maschinellem Lernen und Netzwerksignalen identifizieren.
Ein Beispiel:
Grafik Quelle: Cloudflare
Wichtig: Als der Stealth-Crawler erfolgreich blockiert wurde, wurde beobachtet, dass Perplexity andere Datenquellen – darunter auch andere Websites – nutzt, um eine Antwort zu erstellen. Diese Antworten waren jedoch weniger spezifisch und enthielten keine Details aus dem Originalinhalt, was darauf hindeutet, dass die Blockierung erfolgreich war.
Wie sich verantwortungsvolle Bot-Betreiber im Netz verhalten sollten – und wer es vormacht
Cloudflares Sicherheitsexperten betonen, dass sich das Internet längst auf bestimmte Standards geeinigt hat, wenn es um das Verhalten gutartiger Crawler geht. Im Gegensatz zu intransparentem Vorgehen, wie es im Fall von Perplexity vermutet wird, folgen seriöse Bot-Betreiber klaren Prinzipien:
-
Transparenz: Verantwortungsvolle Crawler identifizieren sich offen über einen eindeutigen User-Agent, veröffentlichen ihre IP-Bereiche, nutzen Authentifizierungsstandards wie Web Bot Auth und stellen Kontaktinformationen bereit.
-
Respektvolles Verhalten: Sie verursachen keinen übermäßigen Traffic, meiden das Scrapen sensibler Daten und verzichten auf Tricks, um der Erkennung zu entgehen.
-
Klarer Zweck: Jeder Bot sollte einen eindeutig formulierten, öffentlich einsehbaren Grund für seine Aktivität haben – sei es für Preisvergleiche, Barrierefreiheit oder Sprachassistenten.
-
Trennung der Funktionen: Unterschiedliche Aktivitäten sollten durch separate Bots ausgeführt werden, damit Website-Betreiber gezielt kontrollieren können, was sie zulassen möchten.
-
Regeltreue: Dazu zählt die Einhaltung von robots.txt-Anweisungen, Ratenbegrenzungen und das Unterlassen jeglicher Umgehung technischer Schutzmaßnahmen.
Als positives Beispiel nennt Cloudflare OpenAI. Das Unternehmen beschreibt transparent den Zweck seiner Crawler, hält sich an die Vorgaben der robots.txt und nutzt zur Authentifizierung den offenen Standard Web Bot Auth.
Beim Test mit OpenAIs ChatGPT zeigte sich laut Cloudflare, dass der Bot die robots.txt korrekt auswertete und das Crawling sofort stoppte, wenn der Zugriff untersagt war. Auch dann, wenn statt einer robots.txt-Sperre eine Blockierungsseite angezeigt wurde, stellte der Bot seine Aktivität ein – ohne dass alternative User-Agents versucht hätten, die Sperre zu umgehen.
Das Fazit der Experten: OpenAI reagiere vorbildlich auf die Präferenzen von Website-Betreibern – und zeige damit, wie sich vertrauenswürdige Akteure im Netz verhalten sollten.
Crawling: Wie Suchmaschinen das Web durchforsten
Unter „Crawling“ – im Deutschen auch als „crawlen“ bezeichnet – versteht man den Prozess, mit dem Suchmaschinen das Internet systematisch nach neuen oder veränderten Inhalten durchkämmen. Dabei werden etwa frisch veröffentlichte Webseiten, aktualisierte Inhalte oder auch gelöschte Seiten und ungültige Links (sogenannte „tote Links“) erkannt und entsprechend erfasst. Dieser automatische Erkundungsvorgang bildet die Grundlage für die Indexierung und damit für die Auffindbarkeit von Webinhalten in Suchmaschinen.
Weitere lesenswerte Artikel

Fachartikel

Wenn Angreifer selbst zum Ziel werden: Wie Forscher eine Infostealer-Infrastruktur kompromittierten

Mehr Gesetze, mehr Druck: Was bei NIS2, CRA, DORA & Co. am Ende zählt

WinDbg-UI blockiert beim Kopieren: Ursachenforschung führt zu Zwischenablage-Deadlock in virtuellen Umgebungen

RISE with SAP: Wie Sicherheitsmaßnahmen den Return on Investment sichern

Jailbreaking: Die unterschätzte Sicherheitslücke moderner KI-Systeme
Studien
Deutsche Unicorn-Gründer bevorzugen zunehmend den Standort Deutschland

IT-Modernisierung entscheidet über KI-Erfolg und Cybersicherheit

Neue ISACA-Studie: Datenschutzbudgets werden trotz steigender Risiken voraussichtlich schrumpfen

Cybersecurity-Jahresrückblick: Wie KI-Agenten und OAuth-Lücken die Bedrohungslandschaft 2025 veränderten
![Featured image for “Phishing-Studie deckt auf: [EXTERN]-Markierung schützt Klinikpersonal kaum”](https://www.all-about-security.de/wp-content/uploads/2025/12/phishing-4.jpg)
Phishing-Studie deckt auf: [EXTERN]-Markierung schützt Klinikpersonal kaum
Whitepaper

ETSI veröffentlicht weltweit führenden Standard für die Sicherung von KI

Allianz Risk Barometer 2026: Cyberrisiken führen das Ranking an, KI rückt auf Platz zwei vor
Cybersecurity-Jahresrückblick: Wie KI-Agenten und OAuth-Lücken die Bedrohungslandschaft 2025 veränderten

NIS2-Richtlinie im Gesundheitswesen: Praxisleitfaden für die Geschäftsführung

Datenschutzkonformer KI-Einsatz in Bundesbehörden: Neue Handreichung gibt Orientierung
Hamsterrad-Rebell

Cyberversicherung ohne Datenbasis? Warum CIOs und CISOs jetzt auf quantifizierbare Risikomodelle setzen müssen
Identity Security Posture Management (ISPM): Rettung oder Hype?
Platform Security: Warum ERP-Systeme besondere Sicherheitsmaßnahmen erfordern
Daten in eigener Hand: Europas Souveränität im Fokus
