9. Februar 2026
Die Kombination verschiedener Programmiersprachen verspricht das Beste aus beiden Welten – doch funktioniert das in der Praxis? Das Team von Island testete die Integration von Rust-Komponenten in eine C#-Umgebung und erzielte beachtliche Leistungssteigerungen. Der Schlüssel zum Erfolg: Foreign Function Interface (FFI) als Brücke zwischen den Laufzeitumgebungen.
Ausgangslage: Wenn C# an seine Grenzen stößt
Bei der Entwicklung einer Funktion zum Scannen von Dateitexten identifizierte das Team einen erheblichen Engpass. Die Aufgabe bestand darin, sensible Informationen in umfangreichen Textdokumenten zu erkennen – während dieser Operation sollte die Datei für Anwender weiterhin nutzbar bleiben.
Die primär in C# entwickelte Anwendung nutzte zunächst die standardmäßige Regex-Bibliothek der Plattform. Diese gilt zwar als gut optimiert, erwies sich jedoch für den spezifischen Einsatzzweck als zu langsam. Die Benutzererfahrung drohte darunter zu leiden.
Erste Optimierungsversuche im bestehenden Code brachten keine zufriedenstellenden Ergebnisse. Auch die Recherche nach alternativen C#-Bibliotheken für Regex-Matching führte nicht zum gewünschten Durchbruch – keine der gefundenen Lösungen vereinte Eignung und Performance.
Der FFI-Ansatz als Lösungsweg
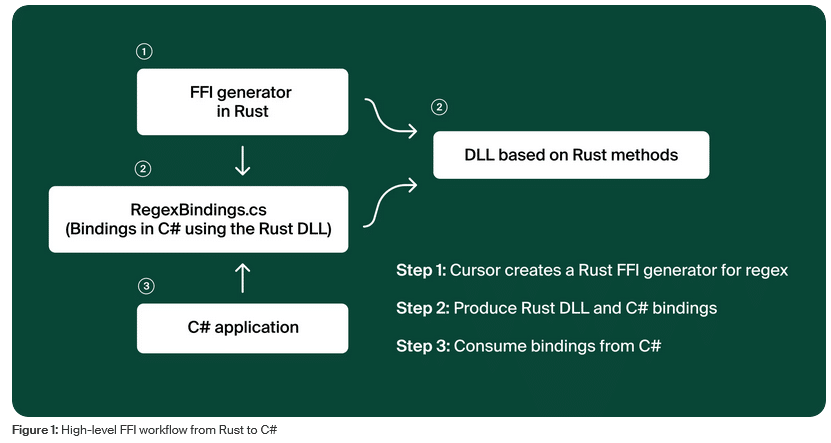
An diesem Punkt weitete das Team seine Suche auf andere Programmiersprachen aus. Rust stand bereits für andere Komponenten im Einsatz und verfügt über eine besonders leistungsfähige Regex-Engine. Um diese zu nutzen, war eine Brücke zwischen den Laufzeitumgebungen erforderlich: Foreign Function Interface.
FFI ermöglicht es, dass Code aus einer Programmiersprache Funktionen in einer anderen Sprache aufruft. Technisch wird dabei Rust-Code in eine Dynamic Link Library (DLL) kompiliert, die aus verwaltetem Code heraus geladen und angesprochen werden kann. Ein schlanker C#-Wrapper übernimmt den Aufruf der exportierten Methoden, überträgt Daten zwischen verwaltetem und nativem Code und gibt Resultate zurück an die Laufzeitumgebung.
So kann rechenintensive Logik in Rust abgearbeitet werden, während die übergeordnete Integration und API-Schnittstelle in C# verbleiben.
Grafik Quelle: Island
Umsetzung mit KI-Unterstützung
Für die rasche Implementierung setzte das Team auf Cursor, ein KI-gestütztes Entwicklungswerkzeug. Der Auftrag lautete: Entwicklung eines schlanken C#-Wrappers für die Rust-Regex-Bibliothek unter Verwendung eines FFI-Frameworks.
Das Tool generierte binnen kurzer Zeit eine funktionsfähige C#-Bibliothek, die auf die Rust-Regex-Engine zugreift. Dabei kam das bestehende FFI-Framework „interoptopus“ zum Einsatz.
Die generierte Lösung bestand aus mehreren Komponenten:
- Einem Wrapper für die Rust-Regex-Bibliothek mit entsprechenden Exportmarkierungen für FFI
- Rust-Code, der automatisch eine C#-Klasse generiert
- Diese Klasse wiederum kann die Methoden aus der Rust-DLL aufrufen
Ein praktischer Nebeneffekt: Die bereits vorhandenen Unit-Tests für die Anwendung ließen sich direkt für die Rust-Bibliothek verwenden, was zusätzliches Vertrauen in die Migration schaffte.
Benchmark-Ergebnisse im Detail
Nach der Code-Generierung folgte der Praxistest. Die neue Bibliothek stellte zwar Methoden bereit, die sich wie jede Standard-C#-Bibliothek verwenden ließen – die Ausführungsgeschwindigkeit unterschied sich jedoch deutlich.
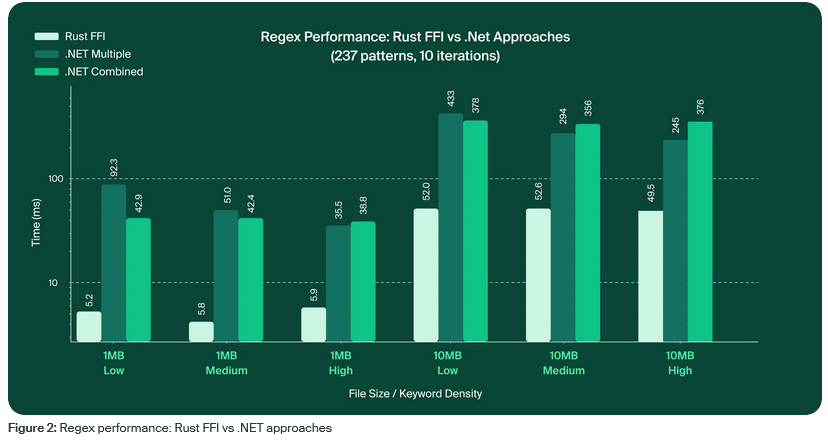
Bei langen Textdokumenten verbesserte die Rust-Lösung die Laufzeit um das Drei- bis Zehnfache. Der durchschnittliche Geschwindigkeitsgewinn lag beim Sechsfachen. Für die Anwendung ein entscheidender Vorteil, auch wenn in bestimmten Szenarien die C#-Implementierung überlegen blieb.
Für eine systematische Bewertung entwickelte das Team eine umfassende Benchmark-Suite mit 237 verschiedenen Mustern. Die Tests deckten Dateigrößen von 1 MB bis 50 MB ab, mit variierenden Trefferdichten zur Simulation realer Szenarien.
Rust bietet mit RegexSet eine Funktion, die mehrere Muster gleichzeitig mit einem Text abgleicht. In C# musste dafür entweder jedes Muster einzeln geprüft oder ein verkettetes Muster mit benannten Gruppen erstellt werden.
Grafik Quelle: Island
Kleine bis mittlere Dateien (1-10 MB)
In diesem Bereich zeigte Rust FFI konstante Leistungssteigerungen zwischen dem 4,9- und 8,25-Fachen. Das beste Ergebnis wurde bei 1-MB-Dateien mit geringer Trefferdichte erreicht: 8,25-mal schnellere Verarbeitung (5,2 ms gegenüber 42,9 ms). Selbst bei höherer Trefferdichte blieb ein Vorteil um den Faktor 7,3 bestehen.
Größere Dokumente (25-50 MB)
Bei längeren Dokumenten fiel der Gewinn etwas geringer aus, blieb aber substantiell. 25-MB-Dateien wurden 4- bis 7,2-mal schneller verarbeitet, bei 50 MB lag der Faktor zwischen 3,3 und 6,5.
Wo C# punktet
Nicht in allen Szenarien erwies sich die FFI-Lösung als vorteilhaft. Bei einfachen regulären Ausdrücken oder wenigen Schlüsselwörtern arbeitete der reine C#-Ansatz effizienter. Dasselbe galt für Regex-Patterns mit vielen Alternativen.
Komplexe Muster hingegen – etwa für E-Mail-Validierung (\b[A-Za-z0-9._%+-]+@[A-Za-z0-9.-]+\.[A-Z|a-z]{2,}\b) oder Datumsformate mit Monatsnamen-Alternativen – zeigten klare Vorteile für die FFI-Implementierung. Da diese Fälle den Hauptanwendungsfall darstellten, fiel die Entscheidung zugunsten der Rust-basierten Lösung.
Technische Implementierung im Überblick
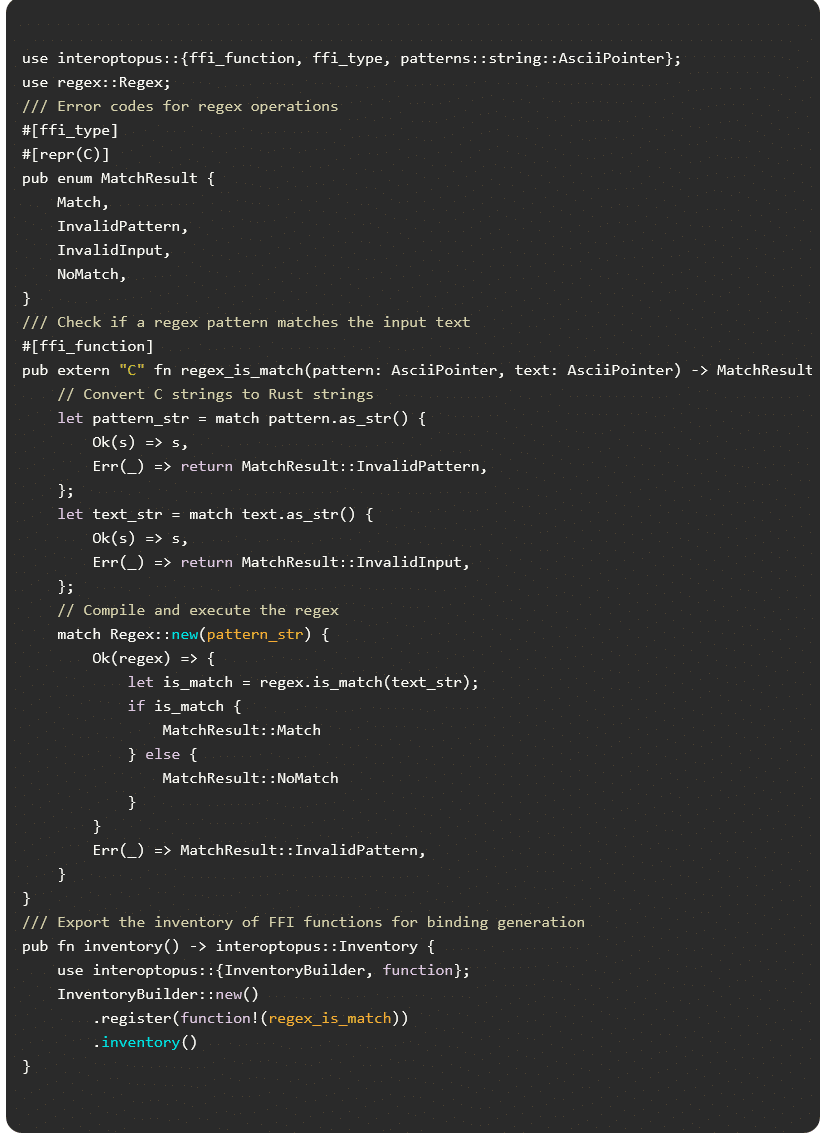
Das von Cursor generierte Rust-Projekt gliedert sich in zwei zentrale Dateien:
lib.rs fungiert als Einstiegspunkt und generiert automatisch C#-Bindungen aus den Rust-FFI-Funktionen. Der Code ist spezifisch für das interoptopus-Framework.
ffi.rs deklariert Funktionen, Datentypen und Fehlerbehandlung, die mit dem Attribut [ffi_type] für den Export in C#-Code gekennzeichnet sind.
Grafik Quelle: Island
Fazit: Pragmatischer Ansatz für Performance-kritische Szenarien
Die Integration von Rust-Komponenten über FFI erwies sich als praktikable Methode, um Leistungsengpässe in C#-Anwendungen zu adressieren. Im konkreten Fall ermöglichte der Ansatz eine etwa sechsfach schnellere Ausführung bei regex-intensiven Operationen.
Werkzeuge wie Cursor vereinfachen die Implementierung erheblich, indem sie notwendige Bindungen und Boilerplate-Code automatisch generieren. So können Entwickler sich auf die eigentliche Problemlösung konzentrieren, statt sich in technischen Details der Sprachintegration zu verlieren.
Der Ansatz eignet sich besonders dort, wo spezifische Performance-Anforderungen die Komplexität einer Multi-Language-Architektur rechtfertigen – nicht als Universallösung, sondern als gezieltes Instrument für klar definierte Engpässe.
„Die in diesem Beitrag bereitgestellten Informationen wurden sorgfältig recherchiert, erheben jedoch keinen Anspruch auf Vollständigkeit oder absolute Richtigkeit. Sie dienen ausschließlich der allgemeinen Orientierung und ersetzen keine professionelle Beratung. Die Redaktion übernimmt keine Haftung für eventuelle Fehler, Auslassungen oder Folgen, die aus der Nutzung der Informationen entstehen.“
Weitere Informationen

Fachartikel

Schatten-DNS-Netzwerk nutzt kompromittierte Router für verdeckte Werbeumleitung
Performance-Boost für C#: Integration von Rust über FFI bringt sechsfache Beschleunigung

KI-gestützte DNS-Sicherheit: Autoencoder-Technologie optimiert Tunneling-Erkennung

Millionen Webserver legen sensible Git-Daten offen – Sicherheitslücke durch Fehlkonfiguration

Neue Apple Pay-Betrugsmasche: Gefälschte Support-Anrufe zielen auf Zahlungsdaten ab
Studien

Sicherheitsstudie 2026: Menschliche Faktoren übertreffen KI-Risiken

Studie: Unternehmen müssen ihre DNS- und IP-Management-Strukturen für das KI-Zeitalter neu denken
Deutsche Unicorn-Gründer bevorzugen zunehmend den Standort Deutschland

IT-Modernisierung entscheidet über KI-Erfolg und Cybersicherheit

Neue ISACA-Studie: Datenschutzbudgets werden trotz steigender Risiken voraussichtlich schrumpfen
Whitepaper

KuppingerCole legt Forschungsagenda für IAM und Cybersecurity 2026 vor

IT-Budgets 2026 im Fokus: Wie Unternehmen 27 % Cloud-Kosten einsparen können

DigiCert veröffentlicht RADAR-Bericht für Q4 2025

Koordinierte Cyberangriffe auf polnische Energieinfrastruktur im Dezember 2025

Künstliche Intelligenz bedroht demokratische Grundpfeiler
Hamsterrad-Rebell

KI‑basierte E‑Mail‑Angriffe: Einfach gestartet, kaum zu stoppen

NIS2: „Zum Glück gezwungen“ – mit OKR-basiertem Vorgehen zum nachhaltigen Erfolg

Cyberversicherung ohne Datenbasis? Warum CIOs und CISOs jetzt auf quantifizierbare Risikomodelle setzen müssen
Identity Security Posture Management (ISPM): Rettung oder Hype?