





10. März 2026
Mozillas Browser-Sicherheit wird durch eine neue Form der KI-gestützten Schwachstellenanalyse auf die Probe gestellt – mit bemerkenswerten Ergebnissen: Anthropics Frontier Red Team identifizierte innerhalb kurzer Zeit mehr als ein Dutzend sicherheitsrelevante Fehler im Code von Firefox, die nun vollständig behoben sind. Die Zusammenarbeit zeigt, wie KI-Modelle klassische Sicherheitswerkzeuge sinnvoll ergänzen können.
Seit über zwei Jahrzehnten gilt Firefox als eine der am intensivsten geprüften Browser-Codebasen überhaupt. Das Open-Source-Modell sorgt dafür, dass der Quellcode öffentlich einsehbar ist und von einer weltweiten Entwickler-Community kontinuierlich auf Schwachstellen untersucht wird. Trotz dieser langen Geschichte intensiver Sicherheitsarbeit gelang es dem Frontier Red Team des KI-Unternehmens Anthropic, bislang unbekannte Fehler aufzudecken – mithilfe des hauseigenen Sprachmodells Claude. Die Ergebnisse flossen in die kürzlich veröffentlichte Version Firefox 148 ein, in der sämtliche identifizierten Sicherheitslücken geschlossen wurden.
Strukturierte Fehlerberichte statt Fehlalarme
KI-generierte Sicherheitsberichte stehen in der Branche häufig unter Verdacht, zu viele False Positives zu produzieren und Open-Source-Projekte mit schlecht aufbereiteten Meldungen unnötig zu belasten. Genau dieses Problem hat in der Vergangenheit dazu geführt, dass viele Projektbetreuer automatisiert erstellten Berichten mit Skepsis begegnen. Die Zusammenarbeit zwischen Anthropic und Mozilla verlief jedoch nach einem grundlegend anderen Muster und setzte in mehreren Punkten neue Maßstäbe für verantwortungsvolle Offenlegung:
- Das Red Team trat erst dann an Firefox-Ingenieure heran, nachdem Sicherheitslücken in der JavaScript-Engine bereits intern verifiziert worden waren
- Jeder Fehlerbericht enthielt minimale, klar reproduzierbare Testfälle, die eine schnelle Überprüfung ermöglichten
- Das Mozilla-Sicherheitsteam konnte die gemeldeten Probleme dadurch innerhalb weniger Stunden eigenständig validieren
- Korrekturen wurden unmittelbar eingeleitet, sodass alle Fixes rechtzeitig vor dem Release von Firefox 148 fertiggestellt werden konnten
- Nach den ersten Ergebnissen weiteten beide Teams die Analyse gemeinsam auf die gesamte Browser-Codebasis aus
Dieser Ansatz – sorgfältige Vorbereitung vor der Kontaktaufnahme, klare Dokumentation und enge Abstimmung mit den Projektverantwortlichen – dürfte als Referenz für künftige KI-gestützte Sicherheitskooperationen dienen.
22 CVEs, 112 Bugs – Ergebnisse im Überblick
Die gemeinsame Analyse der gesamten Browser-Codebasis lieferte ein umfangreiches Bild der Schwachstellenlandschaft:
- 14 schwerwiegende Sicherheitsfehler wurden im Verlauf der Untersuchung identifiziert
- 22 CVEs (Common Vulnerabilities and Exposures) wurden infolgedessen offiziell veröffentlicht
- 90 weitere Bugs kamen hinzu, von denen der Großteil inzwischen ebenfalls behoben ist
- Ein Teil der weniger schwerwiegenden Funde überschnitt sich thematisch mit Ergebnissen klassischer Fuzzing-Methoden – also automatisierter Tests, bei denen Software mit großen Mengen unerwarteter Eingaben konfrontiert wird, um Abstürze und Fehler auszulösen
- Darüber hinaus wurden bestimmte Logikfehler aufgedeckt, die Fuzzer in der Vergangenheit nicht erfasst hatten und die eine eigenständige Stärke der KI-basierten Analyse darstellen
Alle sicherheitsrelevanten Lücken sind in der aktuellen Firefox-Version vollständig geschlossen. Für Nutzerinnen und Nutzer bedeutet das in erster Linie mehr Stabilität und Schutz im Alltag.
KI als Ergänzung etablierter Sicherheitsmethoden
Die Wahl von Firefox als Testobjekt war laut Mozilla kein Zufall. Gerade weil der Browser seit Jahrzehnten zu den am intensivsten geprüften Softwareprojekten überhaupt gehört – mit umfangreichem Fuzzing, statischer Codeanalyse, regelmäßigen externen Audits und einer aktiven Sicherheits-Community –, eignet er sich als aussagekräftiger Maßstab für neue Analyseverfahren. Wenn eine derart gründlich untersuchte Codebasis noch eine nennenswerte Zahl bislang unbekannter Schwachstellen enthält, legt das nahe, dass in weit verbreiteter Software generell ein erhebliches Potenzial an noch entdeckbaren Fehlern vorhanden ist.
Mozilla zieht dabei einen Vergleich zu den Anfängen des Fuzzings: Als diese Technik erstmals eingesetzt wurde, fanden sich in bereits etablierter Software plötzlich Fehler, die zuvor niemand erwartet hatte. KI-gestützte Analyse könnte eine ähnliche Entwicklung anstoßen – nicht als Ersatz für bewährte Methoden, sondern als leistungsstarke Ergänzung im Werkzeugkasten von Sicherheitsingenieuren.
Integration in laufende Sicherheitsprozesse
Mozilla hat bereits Konsequenzen gezogen und begonnen, KI-gestützte Analysen schrittweise in interne Sicherheitsabläufe zu integrieren. Ziel ist es, Schwachstellen künftig noch früher im Entwicklungsprozess zu erkennen und zu beheben – bevor sie in produktiven Versionen landen oder von außen ausgenutzt werden können.
Anthropic hat parallel dazu einen technischen Bericht veröffentlicht, der den Forschungsprozess und die eingesetzte Methodik im Detail beschreibt. Die Zusammenarbeit gilt beiden Seiten als Beispiel dafür, wie verantwortungsvoller Umgang mit KI-Fähigkeiten in der Praxis aussehen kann: mit klarer Kommunikation, koordinierter Offenlegung und dem gemeinsamen Ziel, die Sicherheit weit verbreiteter Software zu verbessern.
Anthropic hat außerdem einen technischen Bericht über seinen Forschungsprozess und seine Ergebnisse veröffentlicht, den Sie hier unten lesen können.
Anthropic hat in Zusammenarbeit mit Mozilla-Forschern demonstriert, dass KI-Modelle eigenständig unbekannte Sicherheitslücken in komplexer Software aufspüren können. Claude Opus 4.6 identifizierte innerhalb von zwei Wochen 22 Schwachstellen im Firefox-Browser, von denen Mozilla 14 als hochgradig sicherheitsrelevant einstufte – das entspricht knapp einem Fünftel aller hochrangigen Firefox-Sicherheitslücken, die im Jahr 2025 behoben wurden.
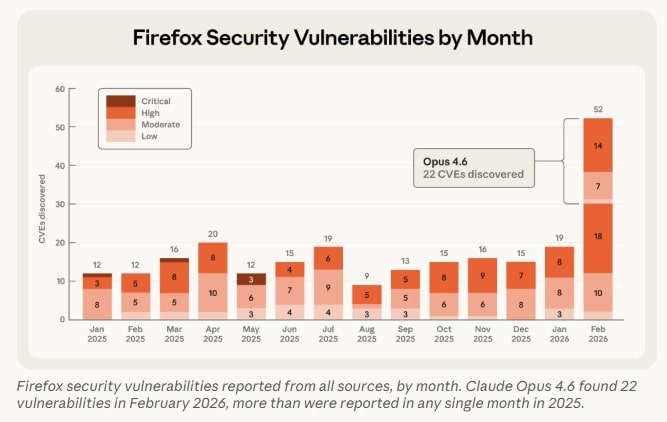
Grafik Quelle: Anthropic
Vom internen Benchmark zur realen Sicherheitsforschung
Der Ausgangspunkt war ein internes Evaluierungsprojekt: Ende 2025 stand Claude Opus 4.5 kurz davor, sämtliche Aufgaben im CyberGym-Benchmark zu lösen – einem Test, der prüft, ob Sprachmodelle bekannte Sicherheitslücken reproduzieren können. Anthropic wollte daraufhin eine anspruchsvollere Bewertungsgrundlage schaffen und erstellte einen Datensatz historischer Firefox-Schwachstellen (CVEs), um zu prüfen, ob das Modell diese eigenständig nachvollziehen kann.
Warum Firefox?
- Einer der meistgenutzten Open-Source-Browser weltweit mit hunderten Millionen Nutzern
- Umfangreiche und gut gepflegte Codebasis mit hohem Sicherheitsstandard
- Besonders relevante Angriffsfläche, da Browser regelmäßig nicht vertrauenswürdige Inhalte verarbeiten
Nachdem Opus 4.6 einen hohen Anteil der historischen CVEs reproduzieren konnte, beauftragte Anthropic das Modell damit, neue, bislang unbekannte Schwachstellen in der aktuellen Firefox-Version zu suchen.
Erste Ergebnisse nach zwanzig Minuten
Bereits nach zwanzig Minuten meldete Claude Opus 4.6 eine sogenannte Use-After-Free-Schwachstelle in der JavaScript-Engine des Browsers – eine Speicherlücke, die Angreifern theoretisch ermöglichen könnte, Daten mit fremden Inhalten zu überschreiben. Der Fund wurde von mehreren Anthropic-Forschern unabhängig voneinander in separaten Testumgebungen bestätigt und anschließend über Mozillas Issue-Tracker Bugzilla gemeldet, inklusive eines von Claude verfassten und manuell geprüften Patch-Vorschlags.
Während das Team die erste Lücke validierte, hatte das Modell bereits fünfzig weitere potenzielle Absturzursachen identifiziert. Nach einer technischen Abstimmung mit Mozilla-Forschern reichte Anthropic schließlich alle Ergebnisse gesammelt ein – insgesamt 112 Berichte nach dem Scan von knapp 6.000 C++-Dateien. Der Großteil der Probleme wurde in Firefox 148 behoben.
Schwachstellen finden vs. ausnutzen: ein deutlicher Unterschied
Um die Grenzen der KI-Fähigkeiten besser einschätzen zu können, untersuchte Anthropic auch, ob Claude in der Lage ist, die gefundenen Lücken tatsächlich auszunutzen. Dazu erhielt das Modell Zugriff auf die gemeldeten Schwachstellen und den Auftrag, für jede einen funktionsfähigen Exploit zu entwickeln.
Das Ergebnis:
- Mehrere hundert Testdurchläufe mit rund 4.000 US-Dollar API-Einsatz
- Nur in zwei Fällen gelang es dem Modell, eine Schwachstelle in einen funktionierenden Exploit umzuwandeln
- Die Exploits funktionierten zudem nur in einer Testumgebung ohne vollständige Browser-Sicherheitsmechanismen (u. a. ohne Sandbox)
Daraus folgt: Die Kosten für das Auffinden von Schwachstellen liegen deutlich unter denen für deren Ausnutzung – und Opus 4.6 ist beim Identifizieren erheblich leistungsfähiger als beim Entwickeln von Angriffscode. Dennoch zeigt der erfolgreiche Exploit-Ansatz in Einzelfällen, dass dieser Bereich künftig verstärkte Aufmerksamkeit erfordert.
Empfehlungen für KI-gestützte Sicherheitsforschung
Aus der Zusammenarbeit mit Mozilla leitet Anthropic mehrere Verfahrensempfehlungen ab:
Für Forscher, die LLM-basierte Tools einsetzen:
- Minimale, reproduzierbare Testfälle den Berichten beifügen
- Detaillierte Proof-of-Concepts dokumentieren
- Patch-Kandidaten als Teil der Einreichung bereitstellen
Für effektive Agentenarchitekturen:
- Sogenannte „Task-Verifier“ einsetzen – Prüfmechanismen, die dem Modell in Echtzeit rückmelden, ob ein erzeugter Patch die Lücke tatsächlich schließt und keine neuen Fehler einführt
- Zwei Mindestanforderungen an jeden Patch prüfen: Behebung der ursprünglichen Schwachstelle und Erhalt der bestehenden Programmfunktionalität
Anthropic betont, dass KI-generierte Patches mit derselben Sorgfalt überprüft werden sollten wie externe Beiträge menschlicher Entwickler.
Ausblick
Neben Firefox hat Anthropic Claude Opus 4.6 bereits zur Analyse weiterer Softwareprojekte eingesetzt, darunter der Linux-Kernel. Mit der Vorschauversion von „Claude Code Security“ stellt das Unternehmen Kunden und Open-Source-Betreuern zudem direkt Werkzeuge zur Erkennung und Behebung von Schwachstellen zur Verfügung.
Anthropic veröffentlichte parallel dazu seine „Coordinated Vulnerability Disclosure“-Richtlinien, die den Rahmen für die Zusammenarbeit mit Software-Betreuern bei künftigen Sicherheitsfunden beschreiben. Die Mozilla-Forscher haben unterdessen begonnen, Claude intern für eigene Sicherheitszwecke zu testen.
Hier geht’s weiter
Bild/Quelle: https://depositphotos.com/de/home.html


Fachartikel

Brainworm: Wenn KI-Agenten durch natürliche Sprache zur Waffe werden
Mozilla und Anthropic: Gemeinsame KI-Analyse macht Firefox sicherer

RC4-Deaktivierung – so müssen Sie jetzt handeln

Plattform-Engineering im Wandel: Was KI-Agenten wirklich verändern

KI-Agenten im Visier: Wie versteckte Web-Befehle autonome Systeme manipulieren
Studien

Sieben Regierungen einigen sich auf 6G-Sicherheitsrahmen

Lieferkettenkollaps und Internetausfall: Unternehmen rechnen mit dem Unwahrscheinlichen

KI als Werkzeug für schnelle, kostengünstige Cyberangriffe

KI beschleunigt Cyberangriffe: IBM X-Force warnt vor wachsenden Schwachstellen in Unternehmen

Finanzsektor unterschätzt Cyber-Risiken: Studie offenbart strukturelle Defizite in der IT-Sicherheit
Whitepaper

Cloudflare Threat Report 2026: Ransomware beginnt mit dem Login – KI und Botnetze treiben die Industrialisierung von Cyberangriffen

EBA-Folgebericht: Fortschritte bei IKT-Risikoaufsicht unter DORA – weitere Harmonisierung nötig

Böswillige KI-Nutzung erkennen und verhindern: Anthropics neuer Bedrohungsbericht mit Fallstudien

Third Party Risk Management – auch das Procurement benötigt technische Unterstützung

EU-Toolbox für IKT-Lieferkettensicherheit: Gemeinsamer Rahmen zur Risikominderung
Hamsterrad-Rebell
Sicherer Remote-Zugriff (SRA) für Operational Technology (OT) und industrielle Steuerungs- und Produktionssysteme (ICS) – Teil 2

Incident Response Retainer – worauf sollte man achten?

KI‑basierte E‑Mail‑Angriffe: Einfach gestartet, kaum zu stoppen

NIS2: „Zum Glück gezwungen“ – mit OKR-basiertem Vorgehen zum nachhaltigen Erfolg
