





20. Oktober 2025
Ein großflächiger Ausfall bei Amazon Web Services (AWS) hat zahlreiche Online-Dienste wie Alexa, Ring, Reddit, Snapchat und weitere Plattformen beeinträchtigt.
Laut Berichten traten die Probleme gegen 7:40 Uhr britischer Zeit auf. Zu diesem Zeitpunkt registrierte die Störungsplattform Downdetector einen deutlichen Anstieg der Meldungen zu Amazon Web Services, was in der Folge viele cloudbasierte Dienste in Mitleidenschaft zog.
Die Ursache des Ausfalls ist derzeit noch unklar. Auf dem AWS-Statusdashboard wird ein „Betriebsproblem“ im Rechenzentrumsstandort Nord-Virginia ausgewiesen. Dort heißt es, Techniker seien „sofort eingeschaltet worden und arbeiten aktiv an der Behebung des Problems“. In einer späteren Aktualisierung teilte AWS mit, es gebe „deutliche Anzeichen einer Erholung“.
Die Auswirkungen des Ausfalls sind weitreichend und betreffen neben Online-Plattformen auch zahlreiche Banken.
Derzeit verzeichnen Alexa, Snapchat, Ring, Roblox, Fortnite, Zero, Signal, Canva und unzählige andere Dienste einen enormen Anstieg der Meldungen auf Downdetector.
AWS Health Dashboard
Service-Zustand
Update: 21.10.2025 / 06:31 Uhr
[BEHOBEN] Erhöhte Fehlerraten und Latenzen20. Oktober, 15:53 Uhr PDT Zwischen 23:49 Uhr PDT am 19. Oktober und 2:24 Uhr PDT am 20. Oktober kam es zu erhöhten Fehlerraten und Latenzen für AWS-Services in der Region US-EAST-1. Darüber hinaus traten während dieser Zeit auch Probleme bei Diensten oder Funktionen auf, die auf US-EAST-1-Endpunkten basieren, wie z. B. IAM und DynamoDB Global Tables. Um 00:26 Uhr am 20. Oktober identifizierten wir den Auslöser des Vorfalls als DNS-Auflösungsprobleme für die regionalen DynamoDB-Dienstendpunkte. Nachdem das DynamoDB-DNS-Problem um 2:24 Uhr behoben worden war, begannen sich die Dienste zu erholen, aber wir hatten anschließend eine Beeinträchtigung im internen Subsystem von EC2, das für den Start von EC2-Instanzen zuständig ist, da es von DynamoDB abhängig ist. Während wir weiter an der Behebung der Beeinträchtigungen beim Start von EC2-Instanzen arbeiteten, wurden auch die Integritätsprüfungen des Network Load Balancer beeinträchtigt, was zu Netzwerkverbindungsproblemen bei mehreren Diensten wie Lambda, DynamoDB und CloudWatch führte. Um 9:38 Uhr konnten wir die Integritätsprüfungen des Network Load Balancers wiederherstellen. Im Rahmen der Wiederherstellungsmaßnahmen haben wir einige Vorgänge vorübergehend gedrosselt, darunter das Starten von EC2-Instanzen, die Verarbeitung von SQS-Warteschlangen über Lambda Event Source Mappings und asynchrone Lambda-Aufrufe. Im Laufe der Zeit haben wir die Drosselung der Vorgänge reduziert und parallel daran gearbeitet, die Probleme mit der Netzwerkkonnektivität zu beheben, bis die Dienste vollständig wiederhergestellt waren.
Um 15:01 Uhr waren alle AWS-Dienste wieder normal verfügbar. Bei einigen Diensten wie AWS Config, Redshift und Connect gibt es weiterhin einen Rückstand an Nachrichten, deren Verarbeitung in den nächsten Stunden abgeschlossen sein wird. Wir werden einen detaillierten Bericht über die Ereignisse bei AWS veröffentlichen.
Zeigen Sie den aktuellen und historischen Status aller AWS-Services an.
Erhöhte Fehlerraten und Latenzen
Erhöhte Fehlerraten und Latenzen
20. Oktober, 12:15 Uhr PDT Wir beobachten weiterhin eine Erholung aller AWS-Dienste, und Instanzstarts sind in mehreren Verfügbarkeitszonen in den US-EAST-1-Regionen erfolgreich. Bei Lambda kann es für Kunden zu zeitweiligen Funktionsfehlern bei Funktionen kommen, die Netzwerkanfragen an andere Dienste oder Systeme stellen, da wir daran arbeiten, verbleibende Probleme mit der Netzwerkkonnektivität zu beheben. Um die Aufruffehler von Lambda zu beheben, haben wir die Rate der SQS-Abfragen über Lambda Event Source Mappings verlangsamt. Da wir nun mehr erfolgreiche Aufrufe und weniger Funktionsfehler verzeichnen, erhöhen wir die Rate der SQS-Abfragen wieder. Wir werden um 13:00 Uhr PDT ein weiteres Update bereitstellen.
20. Oktober, 11:22 Uhr PDT Unsere Maßnahmen zur Behebung von Startfehlern bei neuen EC2-Instanzen schreiten weiter voran, und wir beobachten eine Zunahme der Starts neuer EC2-Instanzen sowie eine Abnahme der Netzwerkverbindungsprobleme in der Region US-EAST-1. Wir stellen auch erhebliche Verbesserungen bei den Lambda-Aufruffehlern fest, insbesondere beim Erstellen neuer Ausführungsumgebungen (einschließlich für Lambda@Edge-Aufrufe). Wir werden um 12:00 Uhr PDT ein Update bereitstellen.
20. Oktober, 10:38 Uhr PDT Unsere Maßnahmen zur Behebung der Startfehler bei neuen EC2-Instanzen schreiten voran, und die internen Subsysteme von EC2 zeigen nun erste Anzeichen einer Erholung in einigen Availability Zones (AZs) in der Region US-EAST-1. Wir wenden Abhilfemaßnahmen auf die verbleibenden AZs an und gehen davon aus, dass die Startfehler und Probleme mit der Netzwerkkonnektivität dann nachlassen werden. Wir werden um 11:30 Uhr PDT ein Update bereitstellen.
20. Oktober, 10:03 Uhr PDT Wir wenden weiterhin Abhilfemaßnahmen für die Integrität des Netzwerk-Load-Balancers an und stellen die Konnektivität für die meisten AWS-Services wieder her. Bei Lambda treten Funktionsaufruf-Fehler auf, da ein internes Subsystem von den Integritätsprüfungen des Netzwerk-Load-Balancers betroffen war. Wir ergreifen Maßnahmen, um dieses interne Lambda-System wiederherzustellen. Für EC2-Startinstanzfehler sind wir dabei, eine Korrektur zu validieren, und werden diese in der ersten AZ bereitstellen, sobald wir sicher sind, dass dies ohne Bedenken möglich ist. Wir werden um 10:45 Uhr PDT ein Update bereitstellen.
20. Oktober, 9:13 Uhr PDT Wir haben zusätzliche Maßnahmen ergriffen, um die Wiederherstellung des zugrunde liegenden internen Subsystems zu unterstützen, das für die Überwachung des Zustands unserer Netzwerk-Load-Balancer verantwortlich ist, und sehen nun eine Wiederherstellung der Konnektivität und der API für AWS-Dienste. Wir haben außerdem die nächsten Schritte identifiziert und wenden diese an, um die Drosselung des Starts neuer EC2-Instanzen zu mildern. Wir werden um 10:00 Uhr PDT ein Update bereitstellen.
20. Oktober, 8:43 Uhr PDT Wir haben die Ursache für die Netzwerkverbindungsprobleme, die sich auf AWS-Dienste ausgewirkt haben, eingegrenzt. Die Ursache liegt in einem zugrunde liegenden internen Subsystem, das für die Überwachung des Zustands unserer Netzwerk-Load-Balancer verantwortlich ist. Wir drosseln die Anfragen für den Start neuer EC2-Instanzen, um die Wiederherstellung zu unterstützen, und arbeiten aktiv an Abhilfemaßnahmen.
20. Oktober, 8:04 Uhr PDT Wir untersuchen weiterhin die Ursache für die Netzwerkverbindungsprobleme, die sich auf AWS-Dienste wie DynamoDB, SQS und Amazon Connect in der Region US-EAST-1 auswirken. Wir haben festgestellt, dass das Problem innerhalb des internen EC2-Netzwerks entstanden ist. Wir untersuchen weiterhin die Ursache und suchen nach Abhilfemaßnahmen.
20. Oktober, 7:29 Uhr PDT Wir haben bestätigt, dass mehrere AWS-Dienste in der Region US-EAST-1 Probleme mit der Netzwerkkonnektivität hatten. Wir sehen erste Anzeichen für eine Wiederherstellung der Konnektivität und untersuchen weiterhin die Ursache.
20. Oktober, 7:14 Uhr PDT Wir können erhebliche API-Fehler und Konnektivitätsprobleme bei mehreren Diensten in der Region US-EAST-1 bestätigen. Wir untersuchen den Vorfall und werden in 30 Minuten oder sobald wir weitere Informationen haben, weitere Updates bereitstellen.
20. Oktober, 6:42 Uhr PDT Wir haben mehrere Abhilfemaßnahmen in mehreren Availability Zones (AZs) in US-EAST-1 durchgeführt und haben weiterhin erhöhte Fehler bei der Starthilfe neuer EC2-Instanzen. Wir begrenzen die Startrate neuer Instanzen, um die Wiederherstellung zu unterstützen. Wir werden um 7:30 Uhr PDT oder früher weitere Informationen bereitstellen, sobald uns diese vorliegen.
20. Oktober, 5:48 Uhr PDT Wir machen Fortschritte bei der Behebung des Problems mit dem Start neuer EC2-Instanzen in der Region US-EAST-1 und können nun in einigen Verfügbarkeitszonen erfolgreich neue Instanzen starten. Wir wenden ähnliche Abhilfemaßnahmen auf die übrigen betroffenen Verfügbarkeitszonen an, um den Start neuer Instanzen wiederherzustellen. Da wir weiterhin Fortschritte erzielen, werden Kunden eine steigende Anzahl erfolgreicher neuer EC2-Starts sehen. Wir empfehlen unseren Kunden weiterhin, neue EC2-Instanzen zu starten, die nicht auf eine bestimmte Verfügbarkeitszone (AZ) ausgerichtet sind, damit EC2 flexibel die geeignete AZ auswählen kann. Wir möchten außerdem mitteilen, dass wir weiterhin erfolgreich den Rückstand an Ereignissen für EventBridge und Cloudtrail bearbeiten. Neue Ereignisse, die an diese Dienste gesendet werden, werden normal zugestellt und es gibt keine erhöhten Latenzen bei der Zustellung. Wir werden um 6:30 Uhr PDT oder früher ein Update bereitstellen, wenn wir weitere Informationen haben.
20. Oktober, 5:10 Uhr PDT Wir bestätigen, dass wir die Verarbeitung von SQS-Warteschlangen über Lambda Event Source Mappings wiederhergestellt haben. Wir arbeiten derzeit daran, den Rückstand an SQS-Nachrichten in Lambda-Warteschlangen zu verarbeiten.
20. Oktober, 4:48 Uhr PDT Wir arbeiten weiterhin daran, neue EC2-Starts in US-EAST-1 vollständig wiederherzustellen. Wir empfehlen EC2-Instanzstarts, die nicht auf eine bestimmte Verfügbarkeitszone (AZ) ausgerichtet sind, damit EC2 flexibel die geeignete AZ auswählen kann. Die Beeinträchtigung bei neuen EC2-Starts wirkt sich auch auf Dienste wie RDS, ECS und Glue aus. Wir empfehlen außerdem, Auto Scaling Groups so zu konfigurieren, dass sie mehrere AZs verwenden, damit Auto Scaling den Start von EC2-Instanzen automatisch verwalten kann. Wir arbeiten an weiteren Maßnahmen, um die Polling-Verzögerungen von Lambda für Event Source Mappings für SQS zu beheben. AWS-Funktionen, die von den SQS-Polling-Funktionen von Lambda abhängen, wie z. B. Aktualisierungen von Organisationsrichtlinien, weisen ebenfalls erhöhte Verarbeitungszeiten auf. Wir werden um 5:30 Uhr PDT ein Update bereitstellen.
20. Oktober, 4:08 Uhr PDT Wir arbeiten weiterhin an der vollständigen Behebung der EC2-Startfehler, die sich als Fehler wegen unzureichender Kapazität äußern können. Darüber hinaus arbeiten wir weiterhin an der Behebung der erhöhten Polling-Verzögerungen für Lambda, insbesondere für Lambda Event Source Mappings für SQS. Wir werden um 5:00 Uhr PDT ein Update bereitstellen.
20. Oktober, 3:35 Uhr PDT Das zugrunde liegende DNS-Problem wurde vollständig behoben, und die meisten AWS-Dienste funktionieren nun wieder normal. Einige Anfragen können während der Arbeiten zur vollständigen Behebung des Problems gedrosselt werden. Darüber hinaus arbeiten einige Dienste weiterhin mit einem Rückstau an Ereignissen wie Cloudtrail und Lambda. Während die meisten Vorgänge wiederhergestellt sind, kommt es bei Anfragen zum Starten neuer EC2-Instanzen (oder Diensten, die EC2-Instanzen starten, wie z. B. ECS) in der Region US-EAST-1 weiterhin zu erhöhten Fehlerraten. Wir arbeiten weiterhin an einer vollständigen Behebung des Problems. Wenn Sie weiterhin Probleme bei der Auflösung der DynamoDB-Dienstendpunkte in US-EAST-1 haben, empfehlen wir Ihnen, Ihren DNS-Cache zu leeren. Wir werden um 4:15 Uhr ein Update bereitstellen oder früher, wenn wir weitere Informationen haben.
20. Oktober, 3:03 Uhr PDT Wir beobachten weiterhin eine Wiederherstellung der meisten betroffenen AWS-Dienste. Wir können bestätigen, dass globale Dienste und Funktionen, die auf US-EAST-1 basieren, ebenfalls wiederhergestellt wurden. Wir arbeiten weiterhin an einer vollständigen Lösung und werden Updates bereitstellen, sobald wir weitere Informationen haben.
20. Oktober, 2:27 Uhr PDT Wir sehen deutliche Anzeichen für eine Wiederherstellung. Die meisten Anfragen sollten nun erfolgreich sein. Wir arbeiten weiterhin an der Bearbeitung der zurückgestellten Anfragen. Wir werden weiterhin zusätzliche Informationen bereitstellen.
20. Oktober, 2:22 Uhr PDT Wir haben erste Abhilfemaßnahmen ergriffen und beobachten erste Anzeichen für eine Wiederherstellung einiger betroffener AWS-Dienste. Während dieser Zeit können Anfragen weiterhin fehlschlagen, während wir an einer vollständigen Lösung arbeiten. Wir empfehlen Kunden, fehlgeschlagene Anfragen erneut zu versuchen. Auch wenn Anfragen nun erfolgreich sind, kann es zu zusätzlichen Verzögerungen kommen, und einige Dienste haben einen Rückstau an Arbeit, dessen vollständige Bearbeitung zusätzliche Zeit in Anspruch nehmen kann. Wir werden weiterhin Updates bereitstellen, sobald wir weitere Informationen haben, oder bis 3:15 Uhr.
20. Oktober, 2:01 Uhr PDT Wir haben eine mögliche Ursache für die Fehlerraten der DynamoDB-APIs in der Region US-EAST-1 identifiziert. Nach unseren Untersuchungen scheint das Problem mit der DNS-Auflösung des DynamoDB-API-Endpunkts in US-EAST-1 zusammenzuhängen. Wir arbeiten an mehreren parallelen Wegen, um die Wiederherstellung zu beschleunigen. Dieses Problem betrifft auch andere AWS-Dienste in der Region US-EAST-1. Globale Dienste oder Funktionen, die auf US-EAST-1-Endpunkten basieren, wie IAM-Updates und DynamoDB Global Tables, können ebenfalls von Problemen betroffen sein. Während dieser Zeit können Kunden möglicherweise keine Support-Fälle erstellen oder aktualisieren. Wir empfehlen Kunden, fehlgeschlagene Anfragen weiterhin zu wiederholen. Wir werden weiterhin Updates bereitstellen, sobald wir weitere Informationen haben, oder bis 2:45 Uhr.
20. Oktober, 1:26 Uhr PDT Wir können erhebliche Fehlerraten bei Anfragen an den DynamoDB-Endpunkt in der Region US-EAST-1 bestätigen. Dieses Problem betrifft auch andere AWS-Services in der Region US-EAST-1. Während dieser Zeit können Kunden möglicherweise keine Supportfälle erstellen oder aktualisieren. Die Techniker wurden sofort eingeschaltet und arbeiten aktiv daran, das Problem zu beheben und die Ursache vollständig zu verstehen. Wir werden weitere Informationen bereitstellen, sobald uns mehr bekannt ist, spätestens jedoch um 2:00 Uhr.
20. Oktober, 00:51 Uhr PDT Wir können erhöhte Fehlerraten und Latenzen für mehrere AWS-Services in der Region US-EAST-1 bestätigen. Dieses Problem betrifft möglicherweise auch die Erstellung von Supportfällen über das AWS Support Center oder die Support-API. Wir arbeiten aktiv daran, das Problem zu beheben und die Ursache zu ermitteln. Wir werden in 45 Minuten ein Update bereitstellen, oder früher, wenn wir weitere Informationen haben.
20. Oktober, 00:11 Uhr PDT Wir untersuchen erhöhte Fehlerraten und Latenzen für mehrere AWS-Services in der Region US-EAST-1. Wir werden in den nächsten 30 bis 45 Minuten ein weiteres Update bereitstellen.
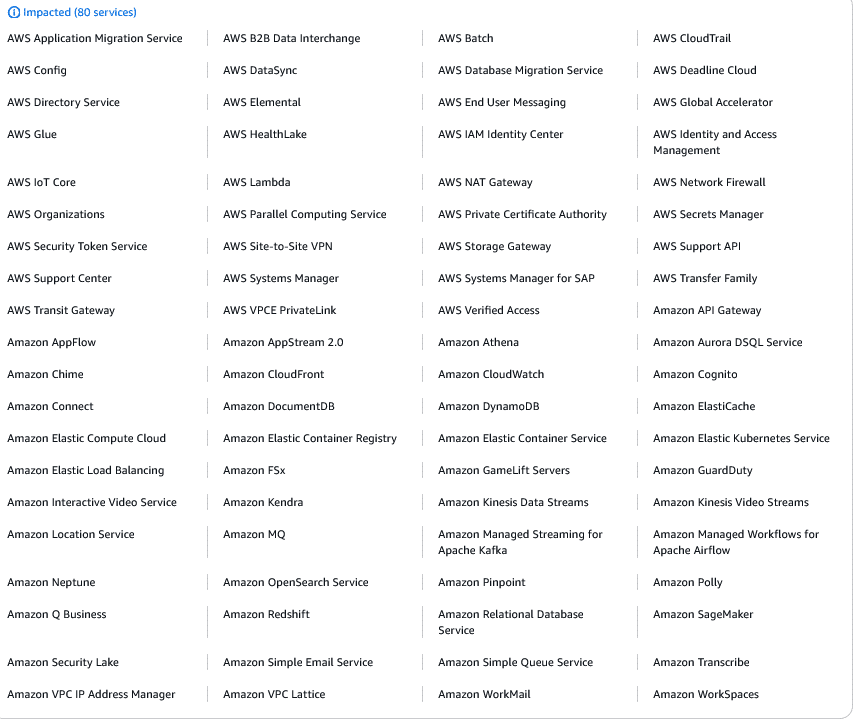
Betroffene AWS-Services
Die folgenden AWS-Services sind von diesem Problem betroffen.
Update: 20.10.2025 / 13:49 Uhr – Impacted Services – 83
Update: 20.10.2025 / 14:14 Uhr – Impacted Services – 65
Update: 20.10.2025 / 21:25 Uhr – Impacted Services – 109
Bild/Quelle: https://depositphotos.com/de/home.html


Fachartikel

RC4-Deaktivierung – so müssen Sie jetzt handeln

Plattform-Engineering im Wandel: Was KI-Agenten wirklich verändern

KI-Agenten im Visier: Wie versteckte Web-Befehle autonome Systeme manipulieren

Island und AWS Security Hub: Kontrollierte KI-Nutzung und sicheres Surfen im Unternehmensumfeld

Wie das iOS-Exploit-Kit Coruna zum Werkzeug staatlicher und krimineller Akteure wurde
Studien

KI als Werkzeug für schnelle, kostengünstige Cyberangriffe

KI beschleunigt Cyberangriffe: IBM X-Force warnt vor wachsenden Schwachstellen in Unternehmen

Finanzsektor unterschätzt Cyber-Risiken: Studie offenbart strukturelle Defizite in der IT-Sicherheit

CrowdStrike Global Threat Report 2026: KI beschleunigt Cyberangriffe und weitet Angriffsflächen aus

IT-Sicherheit in Großbritannien: Hohe Vorfallsquoten, steigende Budgets – doch der Wandel stockt
Whitepaper

Cloudflare Threat Report 2026: Ransomware beginnt mit dem Login – KI und Botnetze treiben die Industrialisierung von Cyberangriffen

EBA-Folgebericht: Fortschritte bei IKT-Risikoaufsicht unter DORA – weitere Harmonisierung nötig

Böswillige KI-Nutzung erkennen und verhindern: Anthropics neuer Bedrohungsbericht mit Fallstudien

Third Party Risk Management – auch das Procurement benötigt technische Unterstützung

EU-Toolbox für IKT-Lieferkettensicherheit: Gemeinsamer Rahmen zur Risikominderung
Hamsterrad-Rebell

Incident Response Retainer – worauf sollte man achten?

KI‑basierte E‑Mail‑Angriffe: Einfach gestartet, kaum zu stoppen

NIS2: „Zum Glück gezwungen“ – mit OKR-basiertem Vorgehen zum nachhaltigen Erfolg

Cyberversicherung ohne Datenbasis? Warum CIOs und CISOs jetzt auf quantifizierbare Risikomodelle setzen müssen
