13. Februar 2026
LinkedIn verarbeitet seit dem 3. November 2025 Profildaten ihrer europäischen Mitglieder für das Training künstlicher Intelligenz. Die Funktion ist standardmäßig aktiviert – Nutzer müssen aktiv widersprechen, um ihre Daten zu schützen. Ein interessanter Beitrag von Tuta beleuchtet die Hintergründe dieser Entwicklung.
Standardmäßige Datennutzung betrifft alle Regionen
LinkedIn hat am 18. September 2025 angekündigt, Informationen von Mitgliedern aus der EU, dem EWR und der Schweiz für KI-Zwecke zu verwenden. Die Datenverarbeitung umfasst Inhalte, die bis ins Jahr 2003 zurückreichen. Für Nutzer außerhalb dieser Regionen erfolgt die Verarbeitung bereits seit 2024.
Das Unternehmen beruft sich auf berechtigtes Interesse gemäß der Datenschutz-Grundverordnung (DSGVO). Eine automatische Zustimmung der Nutzer liegt nicht vor – stattdessen müssen Mitglieder die Funktion manuell in ihren Kontoeinstellungen deaktivieren.
Welche Informationen werden verarbeitet?
Die Datensammlung erstreckt sich über verschiedene Bereiche des LinkedIn-Profils:
Profildaten: Name, Profilbild, berufliche Stationen, Ausbildung, Qualifikationen, Standortangaben, Empfehlungen und Veröffentlichungen werden erfasst.
Veröffentlichte Inhalte: Beiträge, Artikel, Kommentare und Umfrageantworten fließen in die Trainingsdaten ein.
Bewerbungsinformationen: Lebensläufe, Stellenanzeigen, auf die sich Nutzer beworben haben, sowie Antworten auf Auswahlfragen werden gespeichert.
Gruppenaktivitäten: Interaktionen in LinkedIn-Gruppen und entsprechende Nachrichten werden verarbeitet.
Nutzerfeedback: Bewertungen und Rückmeldungen verschiedener Art sind Teil des Datensatzes.
Private Direktnachrichten, Anmeldeinformationen und Zahlungsdaten bleiben nach Unternehmensangaben von der Erfassung ausgenommen.
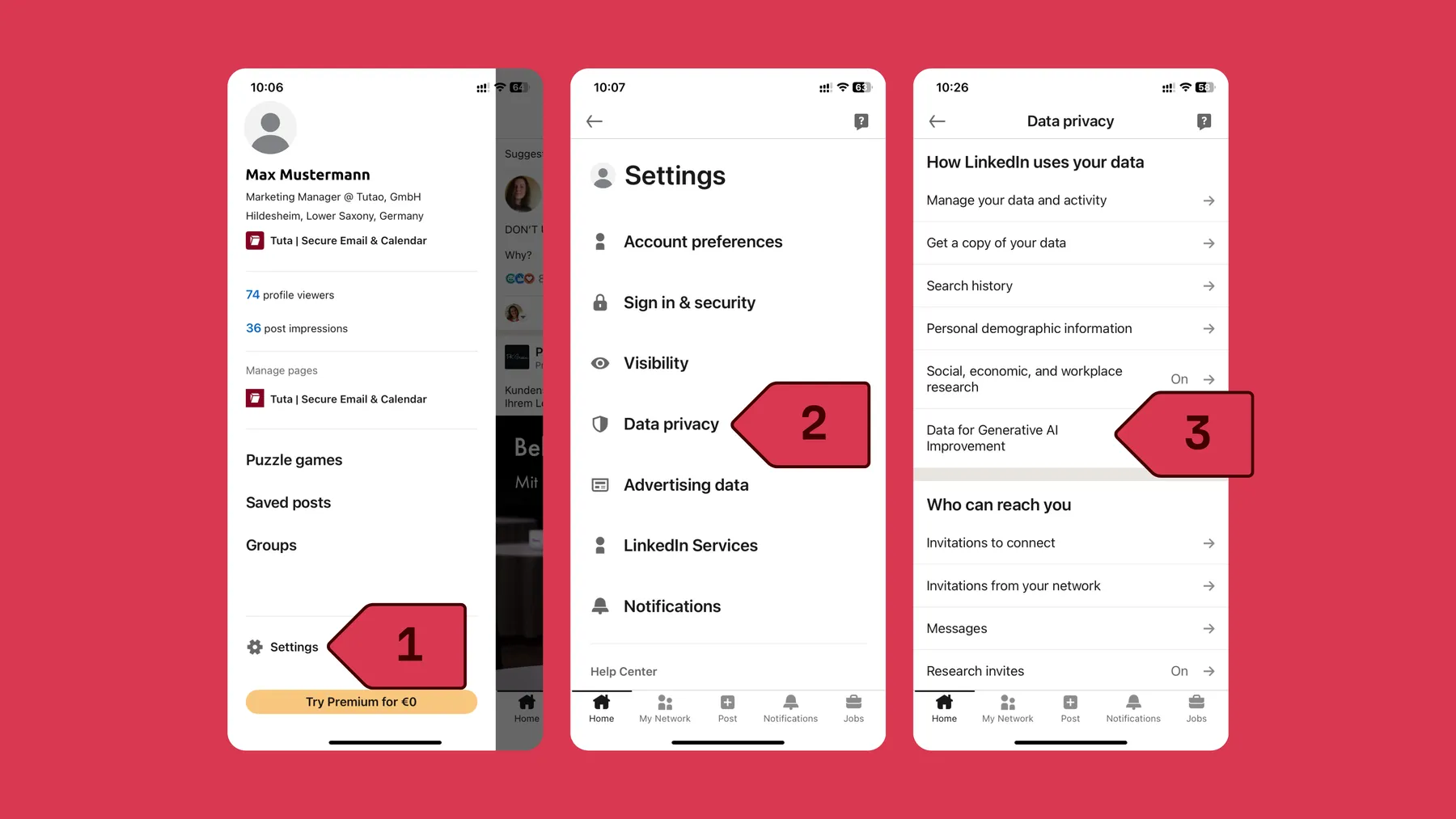
Anleitung zur Deaktivierung der Datenfreigabe
Die Abmeldung ist über verschiedene Geräte möglich und folgt einem einheitlichen Ablauf:
- Anmeldung beim LinkedIn-Konto
- Klick auf das Profilbild
- Auswahl der Einstellungen
- Navigation zu „Daten und Datenschutz“
- Öffnen des Menüpunkts „Daten für generative KI-Verbesserung“
- Deaktivierung des Schalters bei „Meine Daten zum Trainieren von KI-Modellen für die Erstellung von Inhalten verwenden“
Die Deaktivierung verhindert die zukünftige Nutzung der Daten. Bereits verarbeitete Informationen werden nicht aus den Trainingsdatensätzen entfernt. Zusätzlich können Nutzer ein Widerspruchsformular ausfüllen, um die Verarbeitung ihrer personenbezogenen Daten einzuschränken oder abzulehnen.
Grafik Quelle: Tuta / weitere Anleitungen bei Tuta
Zeitlicher Ablauf und Transparenz
Im November 2024 begann LinkedIn mit der Verwendung von Nutzerdaten für KI-Training außerhalb Europas. Mitglieder aus der EU, dem EWR und der Schweiz waren zunächst ausgenommen.
Am 18. September 2024 berichtete das Nachrichtenportal 404 Media, dass LinkedIn seine Datenschutzrichtlinie nicht vor Beginn der Datenerfassung aktualisiert hatte. Nach der Kontaktaufnahme kündigte das Unternehmen eine baldige Aktualisierung der Nutzungsbedingungen an. Noch am selben Tag veröffentlichte LinkedIn einen Beitrag des General Counsel Blake Lawit, der Änderungen ankündigte, die am 20. November 2024 in Kraft traten.
Vergleichbare Entwicklungen bei anderen Plattformen
Die Praxis der Datenverwendung für KI-Training beschränkt sich nicht auf LinkedIn. Meta versuchte Anfang 2025, Facebook- und Instagram-Daten europäischer Nutzer für seine generative KI zu verwenden. Das Vorhaben wurde nach Widerstand vorerst gestoppt.
In den USA, wo keine vergleichbaren Datenschutzgesetze wie die DSGVO existieren, nutzt Meta die Informationen seiner Plattformen bereits für KI-Zwecke. Eine Widerspruchsmöglichkeit für amerikanische Nutzer besteht nicht.
Google verarbeitet ebenfalls Nutzerdaten für seinen KI-Chatbot Gemini. Ein Fall wurde bekannt, in dem der Chatbot auf Informationen aus dem Gmail-Postfach eines Nutzers zugriff, ohne dass dieser dem System explizit Zugang gewährt hatte.
Geschäftsmodelle und Datenverwendung
Technologieunternehmen finanzieren kostenlose Dienste traditionell durch Werbung, die auf Nutzerdaten basiert. Mit der zunehmenden Integration künstlicher Intelligenz erweitert sich die Verwendung dieser Informationen über Werbezwecke hinaus.
Die kostenlose Bereitstellung umfangreicher Produktpaletten durch Unternehmen wie Meta und Google basiert auf der Monetarisierung von Nutzerdaten. Die aktuelle Entwicklung zeigt eine zusätzliche Verwendung dieser Daten für die Entwicklung und das Training von KI-Systemen.
Alternativen und Datenschutz
Für Nutzer, die ihre Privatsphäre schützen möchten, existieren verschiedene Ansätze. Die Prüfung und das Verständnis von Änderungen in Nutzungsbedingungen und Datenschutzrichtlinien erfordert Zeit, bietet aber Kontrolle über die eigenen Daten.
Als Alternative zu etablierten Diensten haben sich datenschutzorientierte Angebote entwickelt. Beispiele umfassen verschlüsselte E-Mail-Dienste wie Tuta Mail als Gmail-Alternative oder Messenger-Dienste wie Signal anstelle von WhatsApp.
Die Entscheidung für oder gegen die Nutzung bestimmter Plattformen bleibt den einzelnen Nutzern überlassen. Eine informierte Wahl setzt jedoch die Kenntnis darüber voraus, wie Unternehmen mit persönlichen Daten umgehen.
Auch interessant:


Fachartikel

Gefährliche Chrome-Erweiterung entwendet Zugangsdaten von Meta Business-Konten

Agentenbasierte KI im Unternehmen: Wie Rollback-Mechanismen Automatisierung absichern

Google dokumentiert zunehmenden Missbrauch von KI-Systemen durch Cyberkriminelle

Sicherheitslücke in Claude Desktop Extensions gefährdet Tausende Nutzer

KI-Agenten: Dateisystem vs. Datenbank – Welche Speicherlösung passt zu Ihrem Projekt?
Studien

Deutsche Wirtschaft unzureichend auf hybride Bedrohungen vorbereitet

Cyberkriminalität im Dark Web: Wie KI-Systeme Betrüger ausbremsen

Sicherheitsstudie 2026: Menschliche Faktoren übertreffen KI-Risiken

Studie: Unternehmen müssen ihre DNS- und IP-Management-Strukturen für das KI-Zeitalter neu denken
Deutsche Unicorn-Gründer bevorzugen zunehmend den Standort Deutschland
Whitepaper

MITRE ATLAS analysiert OpenClaw: Neue Exploit-Pfade in KI-Agentensystemen
BSI setzt Auslaufdatum für klassische Verschlüsselungsverfahren

Token Exchange: Sichere Authentifizierung über Identity-Provider-Grenzen

KI-Agenten in Unternehmen: Governance-Lücken als Sicherheitsrisiko

KuppingerCole legt Forschungsagenda für IAM und Cybersecurity 2026 vor
Hamsterrad-Rebell

KI‑basierte E‑Mail‑Angriffe: Einfach gestartet, kaum zu stoppen

NIS2: „Zum Glück gezwungen“ – mit OKR-basiertem Vorgehen zum nachhaltigen Erfolg

Cyberversicherung ohne Datenbasis? Warum CIOs und CISOs jetzt auf quantifizierbare Risikomodelle setzen müssen
Identity Security Posture Management (ISPM): Rettung oder Hype?