9. Februar 2026
Ein neues KI-basiertes Erkennungssystem identifiziert DNS-Tunneling-Angriffe mit einer Präzision von 99,9 Prozent. Die Lösung kombiniert Autoencoder-Technologie mit Convolutional Neural Networks und erreicht dabei eine Wiederauffindungsrate von 99,5 Prozent bei gleichzeitig niedrigen Falsch-Positiv-Raten im produktiven Einsatz.
DNS-Tunneling als Sicherheitsrisiko
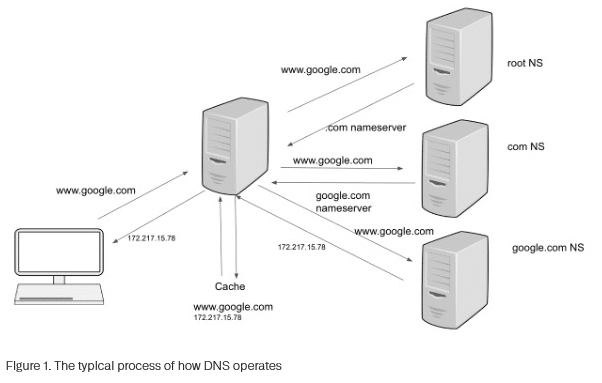
Das Domain Name System dient der Übersetzung von Domainnamen wie www.google.com in IP-Adressen wie 8.8.8.8. Angreifer nutzen diesen vertrauenswürdigen Mechanismus jedoch zunehmend für illegitime Zwecke: Sie betten unerlaubte Kommunikation in reguläre DNS-Anfragen ein und schaffen so verdeckte Datenkanäle.
Diese Methode funktioniert, weil DNS-Verkehr üblicherweise durch Firewalls zugelassen wird und häufig keine intensive Überwachung erfährt. Cyberkriminelle nutzen diese Schwachstelle, um Sicherheitsmaßnahmen zu umgehen und Command-and-Control-Verbindungen aufzubauen.
Aktuelle Bedrohungskampagnen wie Decoy Dog, Saitama und DNS Anchor zeigen die wachsende Raffinesse solcher Angriffe. Der Unterschied zwischen legitimem und bösartigem Datenverkehr wird dabei immer schwerer erkennbar: Während normale Anfragen lesbare Domainnamen verwenden, verschlüsseln Angreifer Daten in scheinbar zufälligen Zeichenketten innerhalb der DNS-Abfragen.
Grafik Quelle: Infoblox
Technischer Ansatz der Lösung
Das entwickelte System basiert auf einem patentierten Verfahren, das einen Autoencoder mit einem Convolutional Neural Network verbindet. Diese Architektur generiert eine Rekonstruktionsverlustfunktion und extrahiert gleichzeitig statistische sowie linguistische Merkmale aus DNS-Verkehrsmustern.
Der Autoencoder lernt das typische Abfrageverhalten von Millionen legitimer Domains und erzeugt Rekonstruktionsverlustwerte, die zwischen normalem und anomalem Verhalten unterscheiden. Das Feature Engineering erfasst dabei verschiedene Charakteristika: Abfragefrequenzmuster, Subdomain-Entropie, Wortsegmentierungsverhältnisse und Payload-Größenverteilungen. Ein Random-Forest-Klassifikator verarbeitet diese Merkmale für die endgültige Klassifizierung.
Datenbasis und Trainingsmethodik
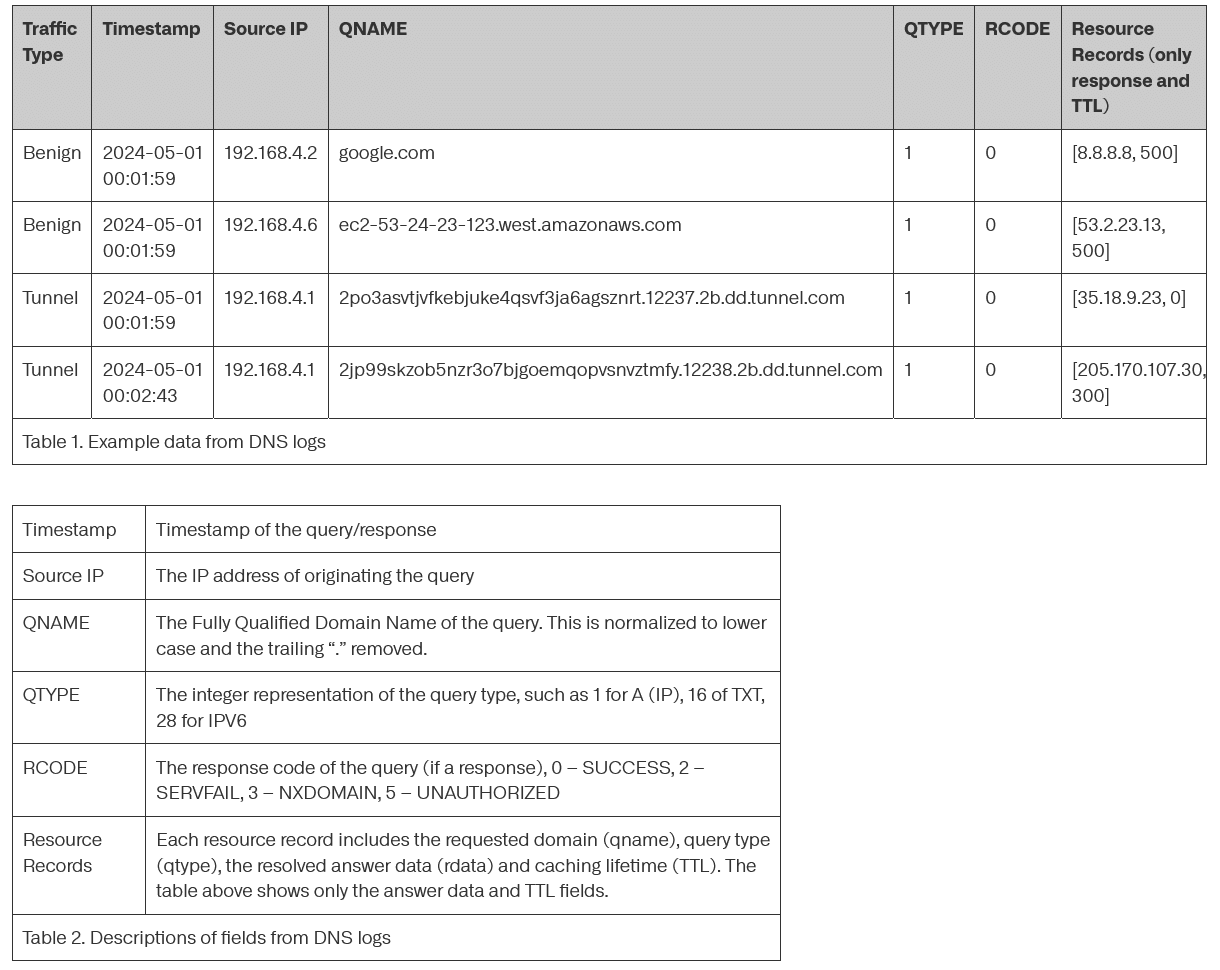
Die Grundlage bilden DNS-Protokolle, die unterhalb des Resolvers erfasst wurden und Zeitstempel, Quell-IP, Abfragenamen, Abfragetypen, Antwortcodes und Ressourceneinträge umfassen. Für harmlose Domain-Daten nutzen die Entwickler DNS-Protokolle verschiedener Unternehmen, Internetdienstanbieter und Bildungseinrichtungen aus einstündigen Zeitfenstern über vier Tage verteilt.
Zwei zentrale Filtermaßnahmen optimieren den Datensatz: Die 500 häufigsten Second Level Domains werden entfernt, da sie über 50 Prozent des gesamten DNS-Verkehrs ausmachen und triviale Klassifizierungsfälle darstellen. Zudem werden bekannte harmlose DNS-Tunnel wie Antiviren-Tools und Spam-Filter aus dem Datensatz eliminiert.
Der Datensatz böswilliger Proben umfasst Hunderttausende DNS-Tunneling-Anfragen aus weit verbreiteten Open-Source-Frameworks wie Pupy, DNSCat2, Sliver, Iodine und Cobalt Strike sowie speziell entwickelte Implementierungen. Diese wurden durch verschiedene Erfassungsmethoden zusammengetragen: Einsatz früherer Erkennungsalgorithmen in Produktivumgebungen, retrospektive Analyse historischer Netzwerkdaten und kontrollierte Sandbox-Ausführungen.
Grafik Quelle: Infoblox
Innovative Merkmalsextraktion
Autoencoder-Technik
Der Ansatz verwendet einen flachen eindimensionalen CNN-Autoencoder zur Ableitung von Rekonstruktionsverlustmerkmalen. Das System wandelt zunächst jedes Zeichen eines DNS-Präfixes in numerische Einbettungen um. Das Präfix „Infoblox“ wird beispielsweise in eine Zeichenvektorsequenz [„i“, „n“, „f“, „o“, „b“, „l“, „o“, „x“] konvertiert.
Der Encoder komprimiert diese Sequenz zu einer latenten Darstellung geringerer Dimension und erfasst wesentliche Muster der Eingabezeichenfolge. Der Decoder rekonstruiert anschließend die ursprüngliche Zeichenfolge aus dieser komprimierten Form.
Das Training erfolgt mit vier Millionen Präfixen aus legitimen Domains. Das unüberwachte Modell lernt dabei typische Muster legitimer Domain-Präfixe wie Wörter der natürlichen Sprache, gängige Abkürzungen und erkennbare Namenskonventionen.
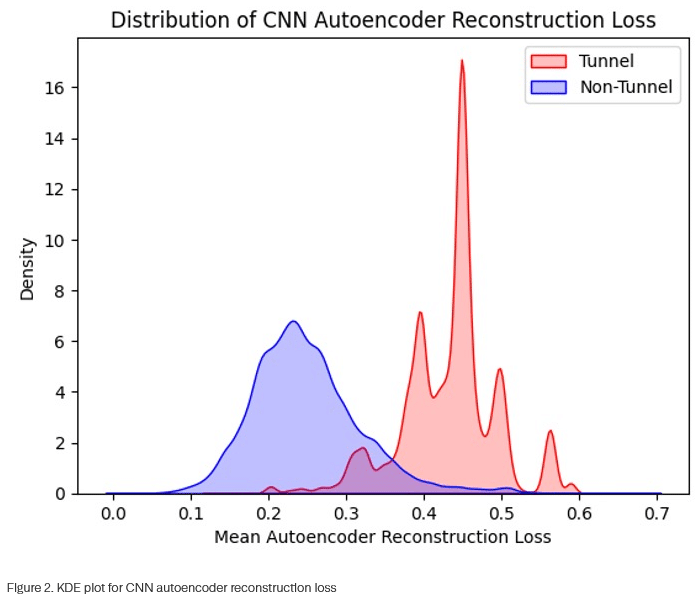
Bei der Auswertung zeigt normaler Verkehr niedrigen Rekonstruktionsverlust, während Tunneling-Aktivitäten durch hohe Verlustwerte auffallen. Verschlüsselte oder zufällig generierte Daten in Tunneling-Präfixen – etwa „2po3asvtjvfkebjuke4qsvf3ja6agsznrt“ – können vom Autoencoder nicht rekonstruiert werden, was zu charakteristisch erhöhten Verlustwerten führt.
Eine speziell entwickelte maskierte MSE-Verlustfunktion (MMSE) berechnet den Verlust ausschließlich über die Nicht-Null-Werte des ursprünglichen Beispiels. Dies reduziert die Empfindlichkeit gegenüber unterschiedlichen Präfixlängen und liefert zuverlässigere Rekonstruktionsverlustmerkmale.
Grafik Quelle: Infoblox
Wortsegmentierungsanalyse
Legitime Präfixe verwenden überwiegend Wörter der natürlichen Sprache, während Tunneling-Präfixe häufig Hex-, Base32- oder ähnliche Kodierungen aufweisen. Eine kostenbasierte Wortsegmentierungstechnik zerlegt Zeichenfolgen in Wörter aus Sprachwörterbüchern.
Die Zeichenfolge „facebooksecurity“ wird dabei in [„face“, „book“, „security“] segmentiert, während eine verschlüsselte Zeichenfolge wie „youjf34gwid86fih“ in [„you“, „j“, „f“, „34“, „g“, „w“, „id“, „86“, „f“, „i“, „h“] zerfällt, da keine Wörterbucheinträge mit dem verschlüsselten Inhalt übereinstimmen.
Das Verhältnis der Segmentanzahl zur Präfixlänge bildet ein aussagekräftiges Merkmal. Tunneling-Domains weisen aufgrund ihrer verschlüsselten Natur deutlich höhere Segment-Längen-Verhältnisse auf. Die harmlose Domain „facebooksecurity“ erreicht ein Verhältnis von 0,19 (3 Segmente/16 Zeichen), während das Tunnelpräfix „youjf34gwid86can“ ein Verhältnis von 0,69 (11 Segmente/16 Zeichen) aufweist.
Leistungskennzahlen im Vergleich
Der Random-Forest-Klassifikator zeigt überlegene Leistung gegenüber logistischer Regression: Auf Abfrageebene erreicht er einen F1-Wert von 99,71 Prozent, auf Domain-Ebene 96,79 Prozent. Die logistische Regression erzielt zwar vergleichbare Recall-Raten (98,13 Prozent auf Abfrageebene, 95,42 Prozent auf Domain-Ebene), ihre Präzision fällt jedoch deutlich geringer aus, insbesondere auf Domain-Ebene mit nur 34,76 Prozent.
Domain-Ebenen-Metriken sind für den operativen Einsatz zentral, da sie die Fähigkeit widerspiegeln, Tunneling-Domains korrekt zu identifizieren statt einzelner Abfragen. Die Recall-Rate auf Domain-Ebene misst korrekt identifizierte eindeutige Tunnel-SLDs geteilt durch die Gesamtzahl eindeutiger Tunnel-SLDs im Testsatz. Die Präzision berechnet sich aus korrekt identifizierten Tunnel-SLDs geteilt durch alle als Tunnel markierten SLDs.
Die hohe Präzision von 95 Prozent auf Domain-Ebene deutet auf effektive Fehlalarmreduktion hin. Ebenso bedeutsam ist die Recall-Rate von 99 Prozent auf Domain-Ebene, die nahezu vollständige Erkennung aller Tunneling-Domains gewährleistet.
Die Maximierung der Wiederauffindbarkeit fügt sich strategisch in die mehrstufige Erkennungsarchitektur ein. Der primäre Klassifikator erfasst potenzielle Bedrohungen mit minimalem Risiko, echte Angriffe zu übersehen. Nachfolgende Validierungsprozesse filtern systematisch Fehlalarme durch zusätzliche Verifizierungsmechanismen und Threat-Intelligence-Korrelation heraus.
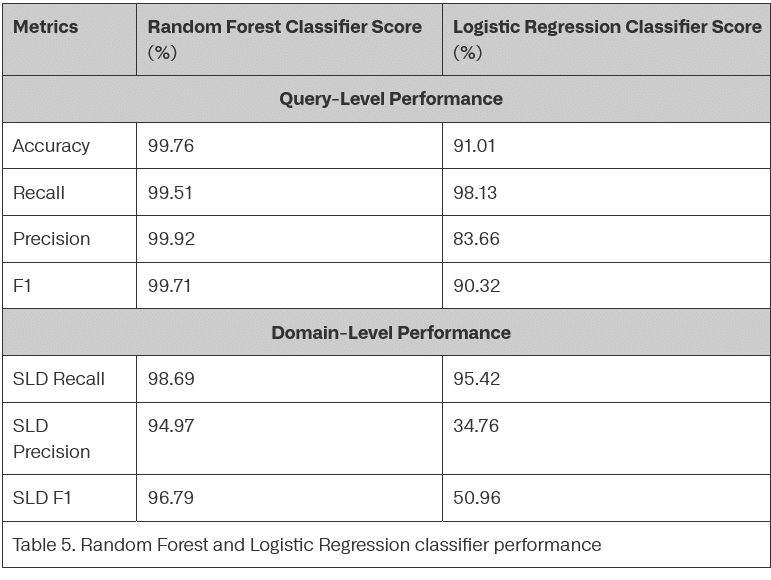
Grafik Quelle: Infoblox
Bedeutung der neuen Merkmale
Eine Ablationsstudie quantifiziert den Beitrag der entwickelten Merkmale. Das Entfernen von Autoencoder-Rekonstruktionsverlust und Wortsegmentierungsverhältnissen führt zu erheblichen Leistungseinbußen: Die Präzision auf SLD-Ebene sinkt von 95 auf 86 Prozent, die Wiederauffindungsrate von 99 auf 98 Prozent. Der F1-Wert fällt von 97 auf 92 Prozent.
Die Präzisionsverbesserung ist angesichts der Verarbeitung von Milliarden DNS-Ereignissen täglich besonders relevant. Selbst geringfügige Präzisionssteigerungen eliminieren potenziell Tausende falscher Markierungen pro Tag. Diese Reduktion wirkt sich direkt auf sekundäre Validierungsaufgaben und Systemeffizienz aus.
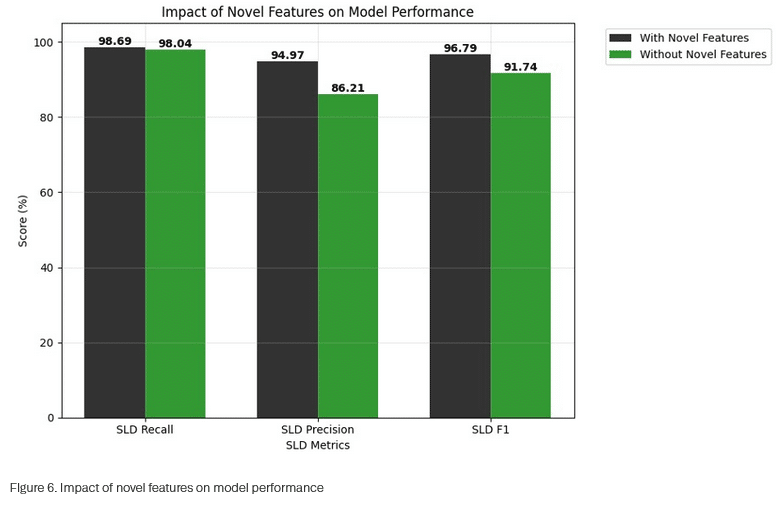
Grafik Quelle: Infoblox
Produktiveinsatz und Validierung
Die Produktionsplattform erstellt Feature-Zusammenfassungen und führt das Modell nahezu in Echtzeit aus. Die Hochdurchsatz-Infrastruktur ermöglicht Erkennung potenzieller Tunneling-Aktivitäten innerhalb von Sekunden.
Nach der primären Erkennung erfolgen sekundäre Validierungsprozesse zur Präzisionsverbesserung und Fehlalarmreduktion:
- Validierung gegen Zulassungslisten bekannter harmloser Tunneling-Anwendungen wie Antivirensoftware und legitime Update-Mechanismen
- Infrastrukturanalyse von Nameservern, Registraren und Hosting-Anbietern markierter SLDs
- Verhaltenskorrelation mit Bedrohungsinformationen und historischen Mustern
Die Validierungsebene funktioniert als skalierbare Microservice-Architektur für robuste Verarbeitung markierter Domains. Nach Abschluss beider Phasen führt das System finale Maßnahmen durch: Alarmierung, Blockierung oder Weiterleitung an Sicherheitsteams zur Untersuchung.
Das System verarbeitet täglich Milliarden DNS-Abfragen bei niedrigen Falsch-Positiv-Raten und ermöglicht automatische Blockierung von DNS-Tunneling-Versuchen unter Aufrechterhaltung legitimen Netzwerkverkehrs.
Weitere Informationen

Fachartikel
KI-gestützte DNS-Sicherheit: Autoencoder-Technologie optimiert Tunneling-Erkennung

Millionen Webserver legen sensible Git-Daten offen – Sicherheitslücke durch Fehlkonfiguration

Neue Apple Pay-Betrugsmasche: Gefälschte Support-Anrufe zielen auf Zahlungsdaten ab

OpenClaw-Agenten: Wenn Markdown-Dateien zur Sicherheitslücke werden

KI-Modelle entdecken kritische Sicherheitslücken in jahrzehntealter Software
Studien

Sicherheitsstudie 2026: Menschliche Faktoren übertreffen KI-Risiken

Studie: Unternehmen müssen ihre DNS- und IP-Management-Strukturen für das KI-Zeitalter neu denken
Deutsche Unicorn-Gründer bevorzugen zunehmend den Standort Deutschland

IT-Modernisierung entscheidet über KI-Erfolg und Cybersicherheit

Neue ISACA-Studie: Datenschutzbudgets werden trotz steigender Risiken voraussichtlich schrumpfen
Whitepaper

KuppingerCole legt Forschungsagenda für IAM und Cybersecurity 2026 vor

IT-Budgets 2026 im Fokus: Wie Unternehmen 27 % Cloud-Kosten einsparen können

DigiCert veröffentlicht RADAR-Bericht für Q4 2025

Koordinierte Cyberangriffe auf polnische Energieinfrastruktur im Dezember 2025

Künstliche Intelligenz bedroht demokratische Grundpfeiler
Hamsterrad-Rebell

KI‑basierte E‑Mail‑Angriffe: Einfach gestartet, kaum zu stoppen

NIS2: „Zum Glück gezwungen“ – mit OKR-basiertem Vorgehen zum nachhaltigen Erfolg

Cyberversicherung ohne Datenbasis? Warum CIOs und CISOs jetzt auf quantifizierbare Risikomodelle setzen müssen
Identity Security Posture Management (ISPM): Rettung oder Hype?