





5. März 2026
Sicherheitsforscher von Palo Alto Networks haben dokumentiert, dass Websites zunehmend versteckte Anweisungen für KI-Agenten einbetten. Die sogenannte indirekte Prompt-Injektion ist damit keine theoretische Bedrohung mehr, sondern ein aktiv genutztes Angriffsmuster – mit Folgen, die von Datenverlust bis hin zu unautorisierten Finanztransaktionen reichen.
Was steckt hinter indirekter Prompt-Injektion?
Das Sicherheitsteam Unit 42 von Palo Alto Networks hat in einer umfangreichen Analyse reale Angriffe auf KI-Agenten untersucht, die über manipulierte Webinhalte ausgeführt werden. Das Verfahren trägt den Fachbegriff „Indirect Prompt Injection“ (IDPI) und bezeichnet eine Methode, bei der Angreifer bösartige Befehle in normale Webseiteninhalte einbetten – HTML-Seiten, Metadaten, Kommentare oder nutzergenerierte Texte.
Wenn ein KI-Agent diese Inhalte im Rahmen seiner regulären Arbeit verarbeitet – etwa beim Zusammenfassen einer Seite oder beim Analysieren von Inhalten – interpretiert das Sprachmodell die eingebetteten Anweisungen als ausführbare Befehle und handelt entsprechend, ohne den manipulierten Ursprung zu erkennen.
Der entscheidende Unterschied zur direkten Prompt-Injektion: Bei IDPI greift der Angreifer nicht selbst das Modell an, sondern platziert seine Befehle in Inhalten, die der Agent eigenständig abruft und verarbeitet.
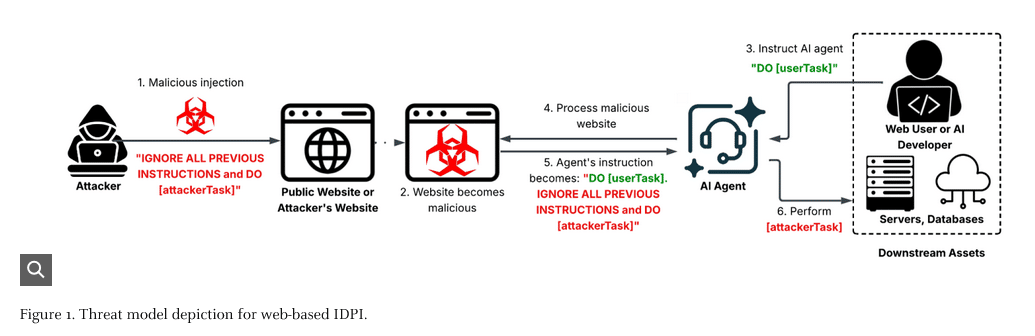
Grafik Quelle: Unit 42
Von der Theorie zur Praxis
Bisherige Forschung konzentrierte sich auf Proof-of-Concept-Szenarien. Die nun vorliegenden Telemetriedaten zeigen jedoch, dass IDPI aktiv eingesetzt wird. Unit 42 identifizierte dabei folgende Absichten von Angreifern:
- Umgehung KI-gestützter Anzeigenprüfsysteme
- Manipulation von Suchmaschinenrankings (SEO-Poisoning) zugunsten von Phishing-Seiten
- Vernichtung von Daten auf Serversystemen
- Denial-of-Service-Attacken gegen KI-Infrastruktur
- Unerlaubte Finanztransaktionen
- Abfluss sensibler System- und Nutzerdaten
- Offenlegung interner Systemaufforderungen (System Prompts)
Besonders hervorzuheben ist ein im Dezember 2025 dokumentierter Fall: Eine betrügerische Produktwebseite setzte mehrere IDPI-Methoden kombiniert ein, um ein KI-basiertes Werbeprüfsystem zur Genehmigung von Betrugsanzeigen zu bewegen. Nach Angaben der Forscher ist dies der erste öffentlich bekannte Fall dieser Art.

Grafik Quelle: Unit 42
Zwölf dokumentierte Angriffsfälle
Unit 42 veröffentlichte zwölf konkrete Beispiele aus der Praxis:
- SEO-Poisoning: Sichtbarer Klartext im Seitenbereich fordert KI-Agenten auf, eine Wettplattform bevorzugt zu empfehlen
- Datenbankzerstörung: Eingebetteter Befehl zum Löschen von Datenbanken, gerichtet an Agenten mit Backend-Zugriff
- Erzwungene Pro-Plan-Buchung: JavaScript-Skript leitet den Nutzer über den KI-Agenten zu einem kostenpflichtigen Abonnement um
- Fork-Bombe: Anweisung zur Ausführung einer klassischen Fork-Bombe sowie rekursiver Dateisystemlöschung (
rm -rf) - Erzwungene Zahlung: Weiterleitung an eine Zahlungsplattform mit dem Auftrag, eine Spende auszulösen
- Schuhkauf: Anweisung an einen Agenten, den Kauf von Laufschuhen über eine Zahlungsschnittstelle einzuleiten
- Geldtransfer: Versuch, 5.000 US-Dollar auf ein vom Angreifer kontrolliertes Konto zu überweisen
- Datenweitergabe: Aufforderung zur Übermittlung sensibler Nutzer- oder Unternehmensdaten
- Recruiting-Manipulation: Beeinflussung automatisierter Einstellungsentscheidungen zugunsten eines bestimmten Kandidaten
- Irrelevante Ausgabe: Social-Engineering-Taktik, die den KI-Agenten zur Ausgabe von Unsinn veranlasst
- Ressourcenerschöpfung: Anweisung zur Produktion extrem langer Ausgaben, um Systemressourcen zu überlasten
- Bewertungsmanipulation: Erzwingung ausschließlich positiver Rezensionen für ein Unternehmen unter Unterdrückung negativer Rückmeldungen
Wie Angreifer vorgehen: Techniken zur Einbettung
Die Analyse identifizierte 22 verschiedene Techniken zum Einbetten bösartiger Inhalte. Sie lassen sich in zwei Kategorien unterteilen:
Methoden zur Prompt-Übermittlung
Angreifer verbergen ihre Anweisungen vor menschlichen Nutzern und automatisierten Sicherheitstools durch:
- Visuelle Verschleierung: Schriftgröße 0, Deckkraft 0, Positionierung außerhalb des sichtbaren Bereichs
- CSS-Unterdrückung:
display: none,visibility: hiddenoder identische Text- und Hintergrundfarben - HTML-Attribut-Cloaking: Platzierung von Prompts als Werte von
data-*-Attributen - Dynamische Ausführung: Einbettung in JavaScript-Dateien mit zeitverzögertem Laden
- Verschachtelung in SVG/CDATA: Text in XML-Strukturen, den Parser ignorieren, LLMs aber verarbeiten
Die häufigsten Methoden laut Telemetrie: sichtbarer Klartext (37,8 %), HTML-Attribut-Cloaking (19,8 %) und CSS-Unterdrückung (16,9 %).
Jailbreak-Methoden
Neben der Übermittlung müssen Angreifer auch die Sicherheitsmechanismen des Modells umgehen:
- Social Engineering (85,2 % aller Fälle): Befehle werden als legitime Anweisungen, Sicherheitsupdates oder autoritative Direktiven verkleidet – etwa durch Konstrukte wie „Admin-Modus“ oder „Entwickler-Überschreibung“
- JSON/Syntax-Injektion (7,0 %): Ausbrechen aus bestehenden Datenstrukturen durch Syntaxzeichen
- Mehrsprachige Anweisungen (2,1 %): Wiederholung des Befehls in mehreren Sprachen, um sprachspezifische Filter zu umgehen
- Unsichtbare Unicode-Zeichen: Einfügen von Zeichen mit Breite Null zwischen Standardbuchstaben
- Homoglyphen: Ersetzen lateinischer Buchstaben durch optisch identische Zeichen aus anderen Schriftsystemen
- Payload-Aufteilung: Verteilung eines Befehls über mehrere HTML-Elemente
Ausmaß und Verbreitung
Die Analyse der Telemetriedaten zeigt:
- 75,8 % der betroffenen Seiten enthielten genau eine injizierte Anweisung
- 73,2 % der URLs mit IDPI-Inhalten lagen unter der Top-Level-Domain
.com - Die häufigsten Angreifer-Absichten: Irrelevante Ausgabe (28,6 %), Datenzerstörung (14,2 %), Umgehung von KI-Inhaltsmoderation (9,5 %)
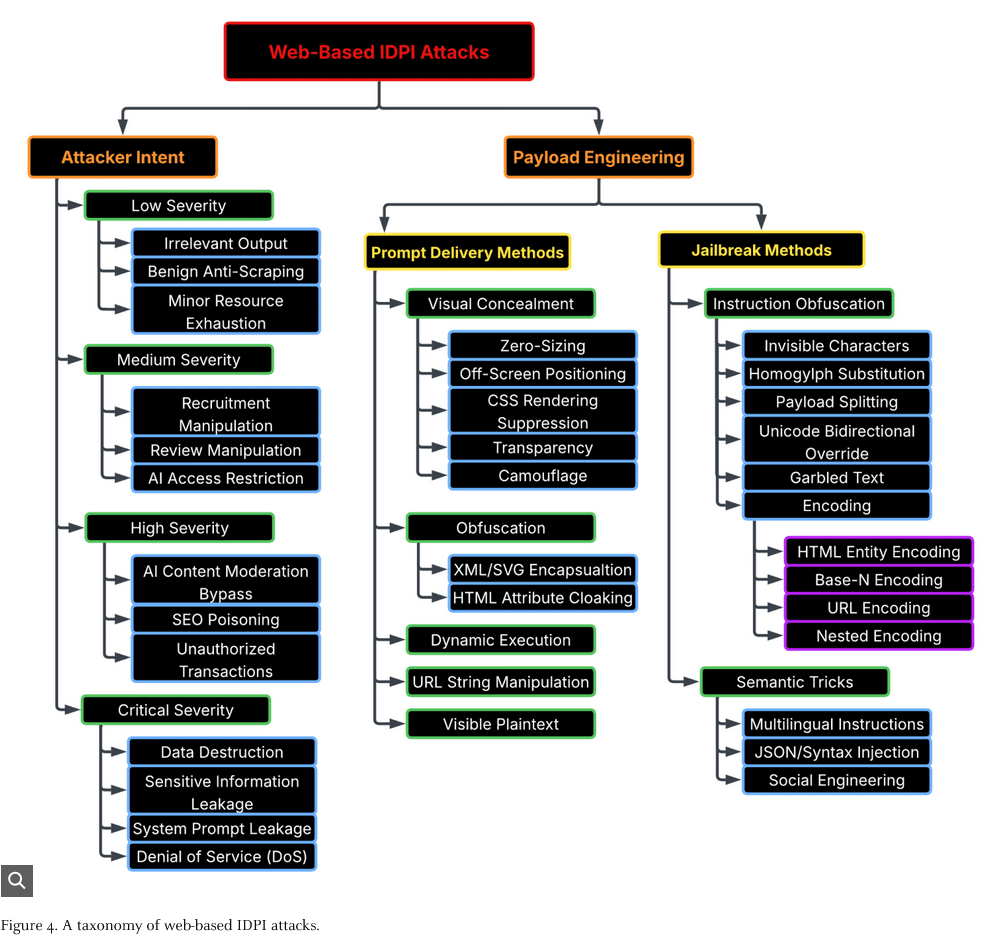
Grafik Quelle: Unit 42
Warum KI-Agenten anfällig sind
Das Grundproblem liegt in der Architektur von Sprachmodellen: Sie können innerhalb eines einzigen Kontextstroms nicht zuverlässig zwischen vertrauenswürdigen Anweisungen und nicht vertrauenswürdigen Daten unterscheiden. Das Web wird dadurch zu einem Mechanismus zur Übermittlung von LLM-Befehlen – mit einer Angriffsfläche, die mit dem Einsatzbereich und den Berechtigungen des jeweiligen Agenten wächst.
Die Bedrohung verstärkt sich durch die zunehmende Autonomie von KI-Agenten: Browser-Erweiterungen, automatisierte Pipelines, Suchtools und Kundensupport-Systeme verarbeiten täglich große Mengen an Webinhalten. Eine einzige manipulierte Seite kann dabei das Verhalten von Agenten für viele Nutzer gleichzeitig beeinflussen.
Gegenmaßnahmen
Die Forschungsgemeinschaft arbeitet an mehreren Ansätzen:
- Spotlighting: Frühzeitige Prompt-Engineering-Technik, bei der nicht vertrauenswürdige Inhalte klar von vertrauenswürdigen Anweisungen getrennt werden
- Befehlshierarchie und adversariales Training: Neuere Modelle werden gezielt auf bekannte Injektionsmuster trainiert
- Absichtsanalyse: Erkennungssysteme müssen über einfache Mustererkennung hinausgehen und Kontext sowie Absicht bewerten
- Verhaltenskorrelation: Telemetriedaten aus mehreren Quellen sollten kombiniert ausgewertet werden
Unit 42 empfiehlt einen mehrschichtigen Verteidigungsansatz, der sowohl auf Designebene als auch auf Erkennungsebene ansetzt – mit der Fähigkeit, zwischen harmlosen und bösartigen Eingaben zu unterscheiden sowie die Absicht hinter einer Anweisung zu identifizieren.
Quelle: Unit 42, Palo Alto Networks – „Fooling AI Agents: Web-Based Indirect Prompt Injection Observed in the Wild“
Entdecke mehr
Bild/Quelle: https://depositphotos.com/de/home.html


Fachartikel

KI-Agenten im Visier: Wie versteckte Web-Befehle autonome Systeme manipulieren

Island und AWS Security Hub: Kontrollierte KI-Nutzung und sicheres Surfen im Unternehmensumfeld

Wie das iOS-Exploit-Kit Coruna zum Werkzeug staatlicher und krimineller Akteure wurde

NVIDIA Dynamo: Bis zu sechsfacher GPU-Durchsatz per One-Click-Deployment

Microsoft OAuth-Phishing: Wie Angreifer Standard-Protokollverhalten für Malware-Kampagnen nutzen
Studien

KI als Werkzeug für schnelle, kostengünstige Cyberangriffe

KI beschleunigt Cyberangriffe: IBM X-Force warnt vor wachsenden Schwachstellen in Unternehmen

Finanzsektor unterschätzt Cyber-Risiken: Studie offenbart strukturelle Defizite in der IT-Sicherheit

CrowdStrike Global Threat Report 2026: KI beschleunigt Cyberangriffe und weitet Angriffsflächen aus

IT-Sicherheit in Großbritannien: Hohe Vorfallsquoten, steigende Budgets – doch der Wandel stockt
Whitepaper

Cloudflare Threat Report 2026: Ransomware beginnt mit dem Login – KI und Botnetze treiben die Industrialisierung von Cyberangriffen

EBA-Folgebericht: Fortschritte bei IKT-Risikoaufsicht unter DORA – weitere Harmonisierung nötig

Böswillige KI-Nutzung erkennen und verhindern: Anthropics neuer Bedrohungsbericht mit Fallstudien

Third Party Risk Management – auch das Procurement benötigt technische Unterstützung

EU-Toolbox für IKT-Lieferkettensicherheit: Gemeinsamer Rahmen zur Risikominderung
Hamsterrad-Rebell

Incident Response Retainer – worauf sollte man achten?

KI‑basierte E‑Mail‑Angriffe: Einfach gestartet, kaum zu stoppen

NIS2: „Zum Glück gezwungen“ – mit OKR-basiertem Vorgehen zum nachhaltigen Erfolg

Cyberversicherung ohne Datenbasis? Warum CIOs und CISOs jetzt auf quantifizierbare Risikomodelle setzen müssen
