





12. Februar 2026
Die Wahl der richtigen Speicherarchitektur entscheidet über Erfolg oder Scheitern von KI-Agenten in der Praxis. Während Dateisysteme durch ihre Einfachheit überzeugen, stoßen sie bei Skalierung und gleichzeitigen Zugriffen an Grenzen. Dieser Fachbeitrag analysiert beide Ansätze anhand konkreter Benchmarks.
Warum KI-Agenten externen Speicher benötigen
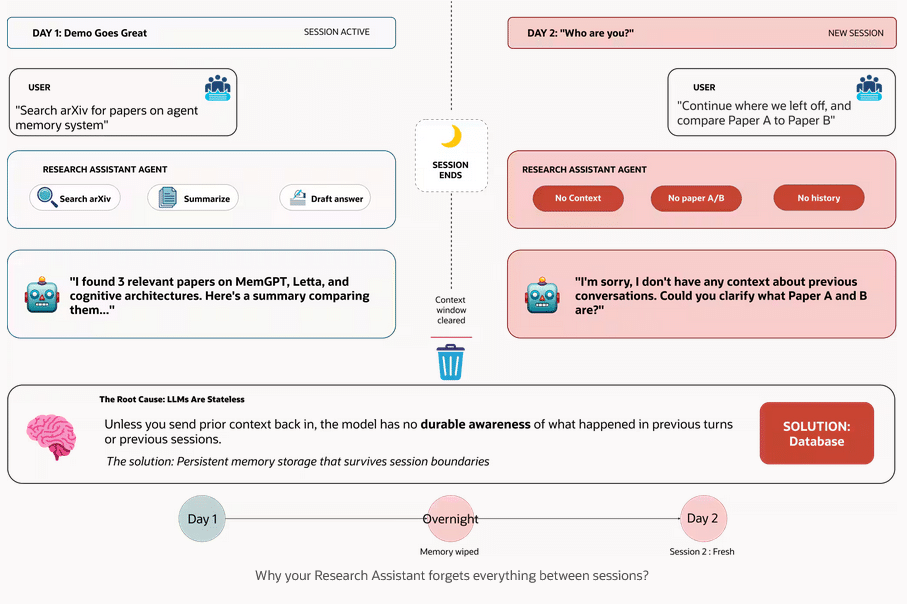
Sprachmodelle arbeiten zustandslos – ohne externen Speicher verlieren sie nach jeder Sitzung alle Informationen. Sobald Aufgaben mehrere Durchläufe erfordern oder verschiedene Nutzer zusammenarbeiten, wird persistenter Speicher notwendig.
Kontextfenster sind begrenzt, die Modellleistung sinkt mit wachsender Token-Anzahl. Die Strategie: Status extern speichern und nur relevante Informationen gezielt abrufen. Modelle zeigen dabei natürliche Affinität zu Verzeichnissen, Markdown-Dateien und CLI-Befehlen – dies erklärt die Beliebtheit dateisystembasierter Ansätze.
Grafik Quelle: Oracle
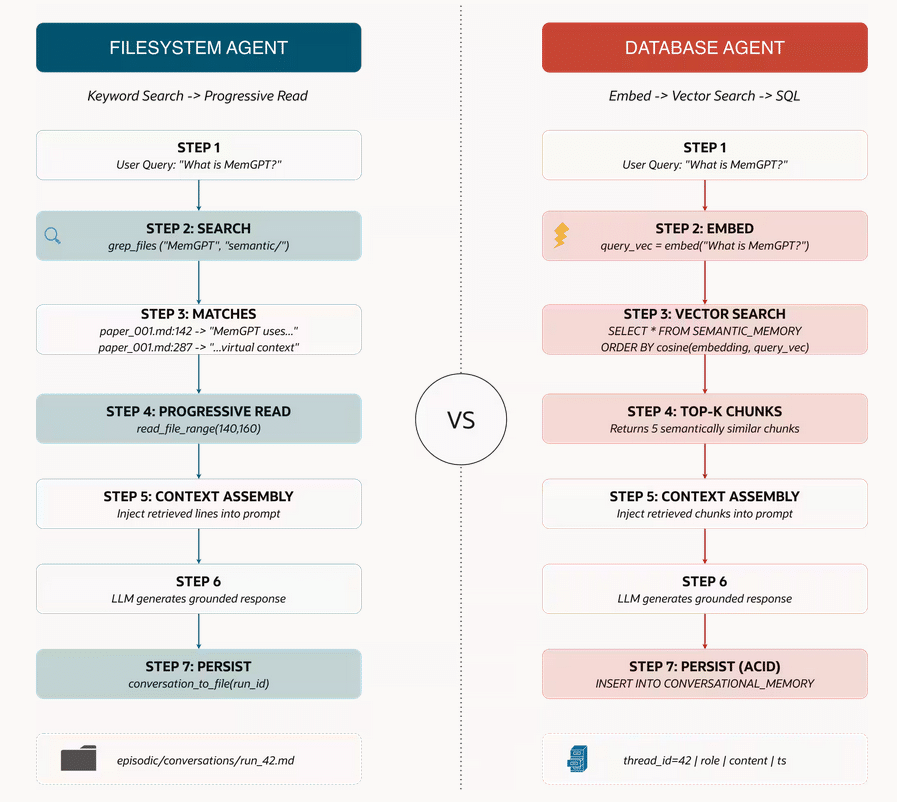
Dateisysteme als Agentenschnittstelle
Praktische Umsetzung
Ein dateisystembasierter Ansatz nutzt das Betriebssystem als Speichersubstrat. Große Ausgaben werden in Files geschrieben, der Agent liest bei Bedarf Ausschnitte – „Dynamic Context Discovery“.
Die Speichertypen:
- Semantischer Speicher: Markdown-Dokumente mit dauerhaftem Wissen
- Episodischer Speicher: Gesprächsprotokolle und Tool-Ausgaben
- Prozeduraler Speicher: Anweisungsdateien für konsistentes Verhalten
Progressive Lesevorgänge vermeiden unnötiges Laden. Drei Tools decken Szenarien ab: Vollständiges Lesen (selten), Tail-Funktion (für Logs), Bereichsauswahl (gezieltes Zoomen).
Suchbasierter Abruf erfolgt über grep-ähnliche Funktionen mit Lazy Iteration – Zeilen werden gestreamt, der Ressourcenverbrauch bleibt konstant.
Tool-Ausgaben landen in Dateien statt im Kontextfenster. Ein Verzeichnis pro Sitzung sammelt alle Aktivitäten ohne Prompt-Belastung.
Stärken
LLMs kennen diese Schnittstelle aus dem Training, primitive Operationen kombinieren sich zu komplexem Verhalten, Token-Effizienz steigt durch progressives Laden. Artefakte bleiben menschenlesbar, Debugging transparent, Portabilität gegeben.
Für Prototypen und artefaktlastige Workflows ist dieser Ansatz optimal. Betriebsaufwand bleibt minimal, Iterationsgeschwindigkeit maximal.
Kritische Schwachstellen
Dateisysteme bieten schwache Garantien bei Parallelität – Prozesse können Schreibvorgänge überschreiben. ACID-Transaktionen existieren nicht, Isolation fehlt.
Suchqualität bleibt auf Keyword-Ebene begrenzt. Synonyme und semantische Zusammenhänge gehen verloren. Mit wachsendem Datenbestand sinkt die Leistung, Indizierung wird zur Eigenentwicklung.
Koordination zwischen mehreren Nutzern bleibt problematisch: Race Conditions und inkonsistente Ansichten sind die Folge.
Grafik Quelle: Oracle
Datenbanken für Produktionsanforderungen
Architektur
Der datenbankgestützte Agent speichert Konversationen als strukturierte Zeilen mit Thread-IDs und Zeitstempeln. Langfristiges Wissen landet in vektorbasierten Speichern, aufgeteilt in Chunks mit Einbettungen. Tool-Aktivitäten werden als Datensätze erfasst.
Der Agent überwacht Token-Nutzung und komprimiert ältere Dialoge zu Zusammenfassungen. Die Arbeits-Prompt bleibt schlank, Historie verfügbar.
Technischer Stack
Die Implementierung trennt klar zwischen Schichten:
- Modellanbieter: Generiert Schlussfolgerungen
- LLM-Framework: Orchestriert Agent-Logik
- Datenbankkern: Speichert Konversationen (SQL) und semantisches Wissen (Vektorindizes)
Vektorspeicher
Ein Vektorspeicher persistiert Einbettungen und ermöglicht Ähnlichkeitssuche nach semantisch nahestehenden Inhalten. HNSW-Indizes sorgen für schnelle Nearest-Neighbor-Suche bei wachsender Wissensbasis.
Performance-Vergleich: Datei vs. Datenbank
Benchmark-Szenarien
Kleines Korpus: Kompakter Datensatz validiert Basis-Abruf. Großes Korpus: Größerer Datensatz mit Paraphrasen prüft Skalierung. Gleichzeitige Schreibvorgänge: Multi-Worker-Test evaluiert Korrektheit unter Last.
Latenz und Qualität
Der datenbankbasierte Agent zeigte niedrigere Latenz. Grund: Semantische Suche liefert weniger, aber präzisere Ergebnisse – weniger Scans, weniger Token für irrelevanten Text.
Bei kleinen Korpora erreichten beide ähnliche Antwortqualität. Wenn Fragen keyword-freundlich sind und Daten überschaubar bleiben, funktionieren beide Wege.
Skalierung
Die Unterschiede vergrößern sich mit wachsendem Korpus. Dateisystem-Agenten mit grep:
- Paraphrasen führen zu Fehlschlägen
- Häufige Keywords erzeugen zu viele Treffer
- Unsicherheit führt zum Laden großer Ausschnitte
Datenbankagenten mit Einbettungen:
- Exakte Formulierung unnötig
- Kleine Gruppen hochähnlicher Chunks genügen
- Indizierter Abruf skaliert vorhersagbar
Large-Corpus-Test: Dateisystem 29,7%, Datenbank 87,1% Bewertung.
Integritätstest
Dateisystem ohne Sperren: Hoher Durchsatz, aber Datenverlust durch Race Conditions. Dateisystem mit Sperren: Integrität gegeben, Entwickler übernehmen Komplexität. Datenbank mit Transaktionen: ACID-Garantien standardmäßig, Korrektheit sichergestellt.
Bewertungsmethodik
Antwortqualität wurde mittels LLM-Bewertung analysiert. Für Produktionssysteme empfiehlt sich ein Mix aus referenzbasierter Bewertung, Retrieval-Metriken und Tracing-Tools zur Fehlerkorrelation.
Entscheidungsrahmen
Wählen Sie Dateisysteme wenn:
- Einzelnutzer-Prototypen im Fokus stehen
- Iterationsgeschwindigkeit über Garantien geht
- Datenvolumen überschaubar bleibt
Wählen Sie Datenbanken wenn:
- Mehrere Nutzer Speicher teilen
- Gleichzeitige Zugriffe die Norm sind
- Semantische Suche erforderlich ist
- Skalierung auf große Korpora geplant ist
Polyglotte Persistenz vermeiden
Viele KI-Stacks nutzen separate Systeme: Vektor-DB für Einbettungen, NoSQL für JSON, relationale DB für Transaktionen. Das bedeutet multiple Sicherheitsmodelle, Backup-Strategien und Fehlerpunkte.
Konvergente Datenbankansätze, die Vektoren, Dokumente und Transaktionen in einer Engine vereinen, reduzieren diese Komplexität erheblich.
Fazit
Die Wahl hängt von Optimierungszielen ab. Dateisysteme bieten die bessere Schnittstelle – LLMs verstehen sie intuitiv. Datenbanken liefern das bessere Substrat für Korrektheit, Parallelität und Abfragbarkeit.
Smart entwickelte Systeme kombinieren beide Stärken: Dateiähnliche Interaktionsmuster mit Datenbank-Garantien im Hintergrund.
Der entscheidende Punkt: Wer Dateisystem-Speicher produktionsreif entwickelt, implementiert zunehmend Datenbankfunktionalität. Statt eine Datenbank zu vermeiden, baut man eine neue mit weniger Garantien.
Die Frage lautet nicht ob, sondern wann der Übergang sinnvoll wird. Für die meisten Teams: Sobald der Prototyp funktioniert und echte Nutzer bedient werden sollen.
Quelle: Oracle Developers Blog – Detaillierte Benchmarks und Code-Implementierungen mit LangChain und Oracle AI Database sind im Original-Beitrag verfügbar.
Weiterlesen

Liebe Leserinnen und Leser,
es ist wieder Zeit für eine kurze Umfrage – und wir zählen auf Ihre Meinung! So können wir sicherstellen, dass unsere Inhalte genau das treffen, was Sie interessiert. Die Umfrage ist kurz und einfach auszufüllen – es dauert nur wenige Minuten. Vielen Dank, dass Sie sich die Zeit nehmen!
Hier geht es zur Umfrage
Fachartikel

KI-Agenten: Dateisystem vs. Datenbank – Welche Speicherlösung passt zu Ihrem Projekt?

NPM-Paket „duer-js“ tarnt Infostealer mit Mehrfach-Payload-Architektur

Ivanti-Exploits: 83 Prozent der Angriffe stammen von einer einzigen IP-Adresse

Cyberangriffe auf Verteidigungsunternehmen: Wie Geheimdienste und Hacker die Rüstungsindustrie infiltrieren

UNC1069: Nordkoreanische Hacker setzen auf KI-gestützte Angriffe gegen Finanzbranche
Studien

Deutsche Wirtschaft unzureichend auf hybride Bedrohungen vorbereitet

Cyberkriminalität im Dark Web: Wie KI-Systeme Betrüger ausbremsen

Sicherheitsstudie 2026: Menschliche Faktoren übertreffen KI-Risiken

Studie: Unternehmen müssen ihre DNS- und IP-Management-Strukturen für das KI-Zeitalter neu denken

Deutsche Unicorn-Gründer bevorzugen zunehmend den Standort Deutschland
Whitepaper

Token Exchange: Sichere Authentifizierung über Identity-Provider-Grenzen

KI-Agenten in Unternehmen: Governance-Lücken als Sicherheitsrisiko

KuppingerCole legt Forschungsagenda für IAM und Cybersecurity 2026 vor

IT-Budgets 2026 im Fokus: Wie Unternehmen 27 % Cloud-Kosten einsparen können

DigiCert veröffentlicht RADAR-Bericht für Q4 2025
Hamsterrad-Rebell

KI‑basierte E‑Mail‑Angriffe: Einfach gestartet, kaum zu stoppen

NIS2: „Zum Glück gezwungen“ – mit OKR-basiertem Vorgehen zum nachhaltigen Erfolg

Cyberversicherung ohne Datenbasis? Warum CIOs und CISOs jetzt auf quantifizierbare Risikomodelle setzen müssen

Identity Security Posture Management (ISPM): Rettung oder Hype?
