





22. August 2025
Ein von den Cybersicherheitsforschern Efi Weiss und Nahman Khayet entwickeltes KI-System sorgt für Aufsehen: Es ist in der Lage, innerhalb von nur 10 bis 15 Minuten funktionierende Exploits für bekannte Sicherheitslücken (CVEs) zu erstellen. Der Kostenpunkt liegt bei gerade einmal rund einem US-Dollar pro Angriffscode. Damit stellt die Technologie gängige Annahmen über Reaktionszeiten in der IT-Sicherheit infrage – und könnte das Zeitfenster, auf das sich Verteidiger bislang verlassen, drastisch verkleinern.
Forscher demonstrieren KI-System zur automatischen Exploit-Generierung
Die Sicherheitsforscher Efi Weiss und Nahman Khayet berichten, dass die von ihrer KI generierten Exploits öffentlich einsehbar sind. Normalerweise verfügen Verteidiger über ein Zeitfenster von Stunden bis Tagen – in manchen Fällen sogar Wochen –, um Schwachstellen zu schließen, bevor ein funktionsfähiger Exploit veröffentlicht wird. Ein KI-System, das die täglich gemeldeten rund 130 CVEs binnen Minuten analysieren und ausnutzen könnte, würde diese „Gnadenfrist“ praktisch aufheben.
Das entwickelte System basiert auf einer mehrstufigen Pipeline: Zunächst werden CVE-Beschreibungen und Code-Patches analysiert. Anschließend erstellt die KI sowohl anfällige Testanwendungen als auch Exploit-Code und überprüft deren Wirksamkeit mithilfe verwundbarer und gepatchter Versionen, um Fehlalarme zu vermeiden. In großem Maßstab könnte ein solches System den täglichen Strom an Schwachstellen deutlich schneller und kostengünstiger verarbeiten als menschliche Analysten.
Die generierten Exploits können Sie hier einsehen.
Seit dem Aufkommen großer Sprachmodelle suchen Forscher und Entwickler nach komplexen Einsatzmöglichkeiten – von sinnvoller Grundlagenforschung wie der Proteinfaltungsanalyse bis hin zu zweifelhaften Anwendungen wie dem Bau von Phishing-Websites. Als „heiliger Gral“ der Cybersicherheit gilt es, ein LLM dazu zu befähigen, Systeme eigenständig auszunutzen. Erste Ansätze existieren bereits: So belegte XBow den ersten Platz auf der Plattform HackerOne, während Pattern Labs ein Experiment mit GPT-5 präsentierte.
Doch wie steht es um die Entwicklung konkreter Exploits? KI-Systeme verlieren bei langen Schlussfolgerungsketten an Genauigkeit. Werden sie jedoch mit deterministischen Exploits ausgestattet, ließe sich dieser Prozess vereinfachen – und die Trefferquote erhöhen.
Forschungsansatz: So funktioniert die Methodik
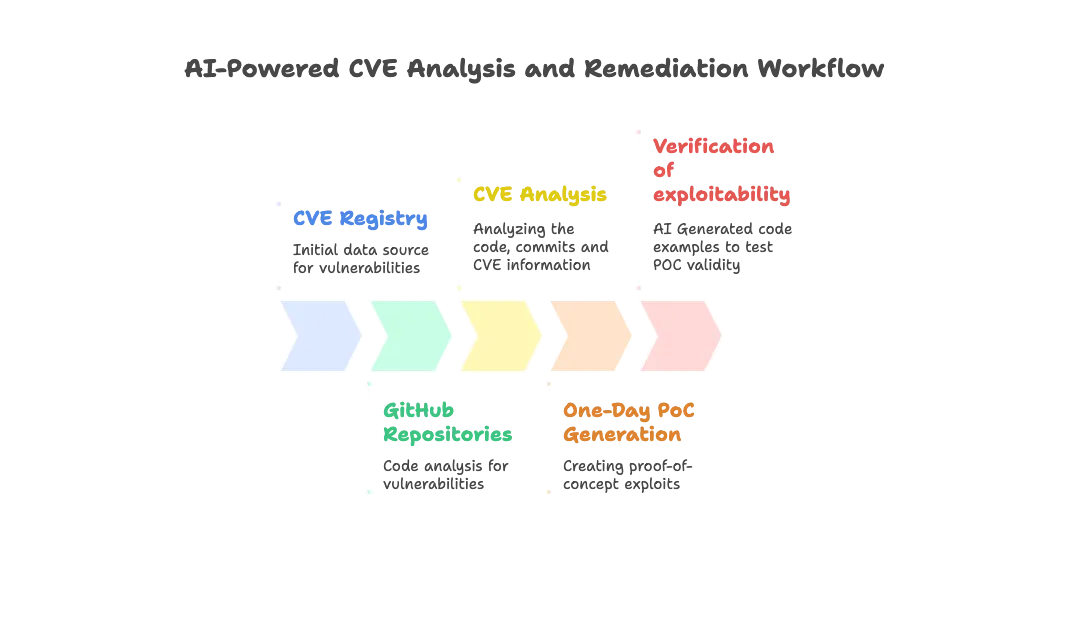
CVE und Behebungsmaßnahmen Workflow Grafik Quelle: Efi Weiss und Nahman Khayet
Die IT-Experten beschreiben ihren Plan in mehreren Phasen.
Datenaufbereitung: Zunächst werden Hinweise und Repositorys ausgewertet, um nachzuvollziehen, wie ein Exploit entsteht. Da sowohl Hinweise als auch Code überwiegend in Textform vorliegen, eignen sich LLMs besonders gut für diese Aufgabe. In den Hinweisen finden sich meist nützliche Informationen, die das Modell anleiten.
Kontextanreicherung: Anschließend wird das LLM in geführten Schritten dazu angeleitet, einen detaillierten Kontext für die Ausnutzung aufzubauen. Dabei geht es um Fragen wie: Wie wird die Nutzlast konstruiert? Wie verläuft der Ablauf bis zur Schwachstelle?
Evaluierungsschleife: Schließlich erstellt das System sowohl einen Exploit als auch eine Beispiel-Anwendung mit eingebauter Schwachstelle, um den Exploit so lange zu testen und anzupassen, bis er zuverlässig funktioniert.
Phase 0 – Das Modell
Kommerzielle SaaS-Modelle wie die APIs von OpenAI, Anthropic oder Google verfügen über Schutzmechanismen, die Proof-of-Concepts in der Regel verhindern – sei es durch direkte Blockaden oder durch nur rudimentäre Code-Vorlagen. Die Forscher begannen daher mit dem lokal auf MacBooks laufenden Modell qwen3:8b und wechselten später zu openai-oss:20b. Dadurch konnten sie zunächst kostenfrei experimentieren und das System schrittweise weiterentwickeln. Mit zunehmender Komplexität der Prompt-Ketten stellte sich heraus, dass die SaaS-Modelle ihre Unterstützung nicht mehr verweigerten.
Als besonders leistungsfähig erwies sich Claude-sonnet-4.0 bei der Erstellung von Proof-of-Concepts. Trotz der fünfmal höheren Kosten bot Opus nur einen geringen Mehrwert.
Phase 0.5 – Der Agent
Zu Beginn erfolgte die Anbindung direkt an LLM-APIs, später erfolgte ein Wechsel zu pydantic-ai, um Typsicherheit sicherzustellen. Ein weiterer entscheidender Punkt war die Einführung einer Cache-Ebene, da LLMs vergleichsweise langsam und kostenintensiv arbeiten. Durch Caching ließen sich Tests deutlich beschleunigen, da nur veränderte Prompts oder deren Abhängigkeiten erneut ausgeführt wurden.
Phase 1 – Von CVE zur technischen Analyse
Ein typischer Arbeitstag startet mit einer Sicherheitsempfehlung – meist in Form einer CVE-Meldung. Open-Source-Projekte veröffentlichen dazu häufig ergänzende GitHub Security Advisories (GHSA).
Exemplarisch verweisen die Forscher auf CVE-2025-54887 – auch um zu betonen, dass es sich nicht um triviale Schwachstellen handelt, sondern um reale Beispiele aus der Praxis.
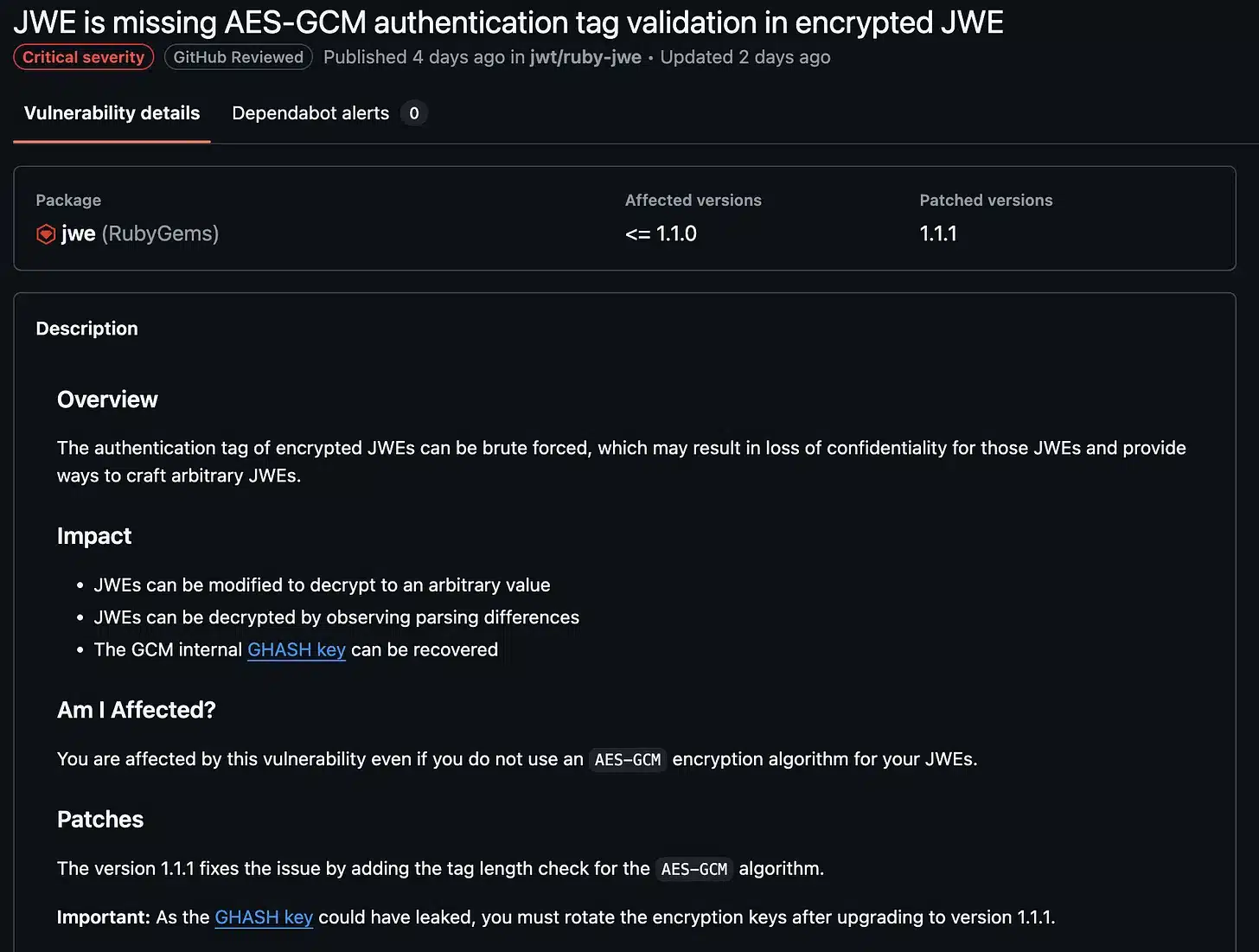
Grafik Quelle: Efi Weiss und Nahman Khayet
Weitere Schritte der Forscher
Die untersuchte Schwachstelle betrifft eine Umgehung der Verschlüsselung, die es Angreifern ermöglicht, unter anderem ungültige JWEs zu entschlüsseln. Neben der NIST-Registrierung griffen die Forscher auch auf GitHub Security Advisories (GHSA) zurück, da diese zusätzliche Details liefern – etwa das betroffene Repository, die betroffenen Versionen, die gepatchte Version sowie eine lesbare Problembeschreibung. Diese Informationen erleichterten den Analyseprozess erheblich.
Um effizient arbeiten zu können, entwickelten die Forscher eine Pipeline, die das Repository klont und den Patch anhand der angegebenen Versionen extrahiert. Mithilfe von LLM-Unterstützung wurden auch Sonderfälle berücksichtigt. Auf dieser Basis konnten Hinweise und Patches in das Modell eingespeist und schrittweise analysiert werden, um einen konkreten Plan zur Ausführung zu erstellen.
Die Aufgabe wurde bewusst in mehrere Prompts unterteilt, sodass die Qualität jeder einzelnen Eingabe separat geprüft und angepasst werden konnte. Nach einer umfassenden Analyse erzeugten die Agenten einen zusammenfassenden Bericht, der wiederum als Kontext für die nächsten Arbeitsschritte diente.
Phase 2 – Testplan
Ziel der Forscher war es, einen funktionierenden Proof-of-Concept (PoC) für Open-Source-Pakete zu entwickeln. Da KI-Modelle beim Codieren ohne Evaluierungsschleifen nur selten funktionierenden Code erzeugen, wurde eine Testumgebung geschaffen. Diese bestand aus einer anfälligen Beispielanwendung und einem Exploit, die wiederholt gegeneinander getestet wurden. Nach jedem Durchlauf erhielt das Modell Feedback und konnte den Ansatz anpassen.
Anfangs sollte ein einziger Agent den gesamten Zyklus steuern. Schnell zeigte sich jedoch, dass dies zu Verwirrung führte – etwa, wenn die anfällige Anwendung in einer anderen Sprache neu geschrieben wurde. Daher wurde die Arbeit auf mehrere spezialisierte Agenten verteilt, die jeweils detaillierte Systemaufforderungen erhielten. Zusätzlich nutzten die Forscher Code-Vorlagen, die sich als zuverlässiger erwiesen als reine Instruktionen.
Für die sichere Ausführung setzten sie auf Dagger, ein Container-Framework, das eine einfache Erstellung von Sandboxes erlaubt. Mit wenigen Befehlen konnten die Container miteinander verbunden werden. Während die aktuelle Umgebung noch auf statischen Anweisungen basiert, könnte in Zukunft auch dieser Teil vom KI-Agenten automatisiert werden.
Eine besondere Herausforderung bestand in der sogenannten „Verfeinerungsschleife“. Das Modell neigte dazu, den Code so weit zu optimieren, dass die eigentliche Verwundbarkeit verloren ging. Um Fehlalarme zu vermeiden, wurde deshalb eine zusätzliche Testphase eingebaut: Der Exploit musste nicht nur gegen die anfällige, sondern auch gegen die gepatchte Version getestet werden. Nur wenn er dort scheiterte, galt er als valide.
Nach einer Reihe von Optimierungen – inklusive stark hervorgehobener Prompts – gelang es schließlich, einen funktionierenden Exploit zu erzeugen. Der Code nutzte tatsächlich die in der Beispielanwendung enthaltene Schwachstelle aus.
Zum Abschluss fügten die Forscher eine Bestätigung mit Opentimestamps hinzu, einem Dienst zur fälschungssicheren Zeitstempelung von Dateien, um den Zeitpunkt der PoC-Erstellung nachzuweisen.
Fazit und Ausblick
Alle Ergebnisse der Untersuchung sind in einem GitHub-Repository sowie in einem Google-Drive-Ordner verfügbar. Sämtliche ZIP-Dateien wurden mit Opentimestamps versehen, um einen fälschungssicheren Zeitstempel zu gewährleisten. Die vollständige Ausführung für eine einzelne CVE dauert rund 10 bis 15 Minuten. Zum Zeitpunkt der Veröffentlichung lagen zehn funktionierende Exploits vor.
Der Blick in die Zukunft zeigt: Die bisherigen Sicherheitsrichtlinien – etwa die Vorgabe, kritische Schwachstellen innerhalb von sieben Tagen zu beheben – könnten bald überholt sein. Sicherheitsverantwortliche müssen künftig mit deutlich kürzeren Zeitfenstern rechnen. Statt Wochen bleiben möglicherweise nur noch Minuten, um auf neue Bedrohungen zu reagieren.
Nach Einschätzung der Forscher markiert das aktuelle Ergebnis lediglich den Anfang dessen, was mit bestehenden KI-Technologien möglich ist. Zum Einsatz kamen bislang ausschließlich generische Basismodelle, ohne spezifische Feinabstimmung. Schon die direkte Nutzung spezialisierter Codemodelle wie Claude Code könnte die Leistung spürbar erhöhen.
Auch erste Experimente mit zusätzlichen Werkzeugen wurden unternommen – darunter context7 zur Verbesserung von Code-Generierung und Code-Explorationstools für eine tiefere Analyse des Kontrollflusses. Diese Ansätze erwiesen sich jedoch angesichts des hohen Aufwands im Verhältnis zum Mehrwert als wenig effizient.
Perspektivisch halten die Forscher sogar eine Integration von Tools wie Ghidra und Bindiff für denkbar, um auch geschlossene Software-Patches auf Schwachstellen hin zu untersuchen. Damit würde sich die Frage stellen, ob KI nicht nur bekannte Sicherheitslücken, sondern auch Zero-Day-Schwachstellen automatisiert ausnutzen könnte – ein Szenario, das möglicherweise erst nach Veröffentlichung künftiger Patches relevant wird.
Weitere Tipps & Themen
Bild/Quelle: https://depositphotos.com/de/home.html


Fachartikel

RC4-Deaktivierung – so müssen Sie jetzt handeln

Plattform-Engineering im Wandel: Was KI-Agenten wirklich verändern

KI-Agenten im Visier: Wie versteckte Web-Befehle autonome Systeme manipulieren

Island und AWS Security Hub: Kontrollierte KI-Nutzung und sicheres Surfen im Unternehmensumfeld

Wie das iOS-Exploit-Kit Coruna zum Werkzeug staatlicher und krimineller Akteure wurde
Studien

Sieben Regierungen einigen sich auf 6G-Sicherheitsrahmen

Lieferkettenkollaps und Internetausfall: Unternehmen rechnen mit dem Unwahrscheinlichen

KI als Werkzeug für schnelle, kostengünstige Cyberangriffe

KI beschleunigt Cyberangriffe: IBM X-Force warnt vor wachsenden Schwachstellen in Unternehmen

Finanzsektor unterschätzt Cyber-Risiken: Studie offenbart strukturelle Defizite in der IT-Sicherheit
Whitepaper

Cloudflare Threat Report 2026: Ransomware beginnt mit dem Login – KI und Botnetze treiben die Industrialisierung von Cyberangriffen

EBA-Folgebericht: Fortschritte bei IKT-Risikoaufsicht unter DORA – weitere Harmonisierung nötig

Böswillige KI-Nutzung erkennen und verhindern: Anthropics neuer Bedrohungsbericht mit Fallstudien

Third Party Risk Management – auch das Procurement benötigt technische Unterstützung

EU-Toolbox für IKT-Lieferkettensicherheit: Gemeinsamer Rahmen zur Risikominderung
Hamsterrad-Rebell
Sicherer Remote-Zugriff (SRA) für Operational Technology (OT) und industrielle Steuerungs- und Produktionssysteme (ICS) – Teil 2

Incident Response Retainer – worauf sollte man achten?

KI‑basierte E‑Mail‑Angriffe: Einfach gestartet, kaum zu stoppen

NIS2: „Zum Glück gezwungen“ – mit OKR-basiertem Vorgehen zum nachhaltigen Erfolg
