





13. August 2025
James Kettle, Forschungsleiter beim Sicherheitsspezialisten PortSwigger, spricht in einem aktuellen Blogbeitrag eine klare Forderung aus: Das Internet müsse sich von HTTP/1.1 verabschieden. Der Grund: Das inzwischen über 25 Jahre alte Protokoll sei „von Natur aus unsicher“ und öffne Angreifern regelmäßig Tür und Tor für sogenannte Desynchronisierungsattacken.
Über sechs Jahre lang seien weltweit Versuche unternommen worden, die Schwachstellen zu schließen. Doch Kettle kommt zu einem ernüchternden Fazit: Die bisherigen Maßnahmen hätten die Probleme lediglich kaschiert, nicht aber gelöst. In seinem Beitrag stellt er neue Varianten von HTTP-Desync-Angriffen vor, mit denen sich massenhaft Benutzerkonten kompromittieren lassen – demonstriert anhand konkreter Fallstudien. Betroffen seien dabei auch zentrale Infrastrukturen großer Anbieter wie Akamai, Cloudflare und Netlify.
Zudem präsentiert der Forscher ein Open-Source-Toolkit, das Diskrepanzen in der Protokollauslegung aufspüren und gezielt Schwachstellen identifizieren kann. Das Werkzeug habe in Kombination mit den neuen Angriffstechniken innerhalb von zwei Wochen zu Bug-Bounty-Prämien von über 200.000 US-Dollar geführt.
Kettle plädiert dafür, HTTP-Request-Smuggling endlich als fundamentalen Designfehler anzuerkennen. „Einzelne Implementierungen zu patchen, wird diese Bedrohung nie vollständig beseitigen“, warnt er. Selbst behobene Schwachstellen ließen Websites anfällig für künftige Angriffsvarianten. Die Ursache sieht er in einem grundlegenden Mangel des Protokolls, der selbst kleine Implementierungsfehler zu gravierenden Sicherheitsrisiken mache.
Sein Fazit: Nur der Umstieg auf HTTP/2 oder neuere Versionen könne diese Gefahr bannen. „Wenn wir ein sicheres Web wollen, muss HTTP/1.1 verschwinden.“
Das Desync-Endspiel
Der fatale Fehler in HTTP/1.1
HTTP/1.1 hat einen fatalen, leicht ausnutzbaren Fehler: Die Grenzen zwischen einzelnen HTTP-Anfragen sind sehr schwach. Anfragen werden einfach ohne Trennzeichen auf dem zugrunde liegenden TCP/TLS-Socket aneinandergehängt, und es gibt mehrere Möglichkeiten, ihre Länge anzugeben. Das bedeutet, dass Angreifer extreme Unklarheiten darüber schaffen können, wo eine Anfrage endet und die nächste beginnt. Große Websites verwenden häufig Reverse-Proxys, die Anfragen von verschiedenen Benutzern über einen gemeinsamen Verbindungspool an den Backend-Server weiterleiten. Das bedeutet, dass ein Angreifer, der auch nur die kleinste Parser-Diskrepanz in der Serverkette findet, eine Desynchronisation verursachen, einen bösartigen Präfix an die Anfragen anderer Benutzer anhängen und in der Regel die vollständige Kontrolle über die Website erlangen kann:

Grafik Quelle: PortSwigger
Kettle erinnert daran, dass HTTP/1.1 als „veraltetes, tolerantes, textbasiertes Protokoll“ mit tausenden Implementierungen naturgemäß fehleranfällig sei. Parser-Diskrepanzen – also Unterschiede in der Interpretation von Anfragen durch verschiedene Systeme – ließen sich leicht aufspüren. Bereits 2019 habe er das Potenzial dieser Schwachstelle erkannt: „Ich hatte das Gefühl, dass man damit alles hacken könnte.“ Damals gelang ihm unter anderem, die Anmeldeseite von PayPal gleich zweimal zu kompromittieren.
Seitdem veröffentlichte PortSwigger nicht nur mehrere Forschungsarbeiten zum Thema „Request Smuggling“, sondern auch einen kostenlosen Online-Kurs. Für Fachleute könne dieser eine wertvolle Hilfe sein, wenn die technischen Details komplex werden.
Nach sechs Jahren intensiver Arbeit hätte man annehmen können, dass das Problem dank strengerer Parser und der Einführung von HTTP/2 – einem binären Protokoll, das solche Angriffe weitgehend verhindert, sofern es für Upstream-Verbindungen eingesetzt wird – gelöst sei. Die Realität sieht jedoch anders aus: „Leider haben wir das Problem nur scheinbar gelöst“, so Kettle.
Abhilfemaßnahmen, die Probleme verbergen, aber nicht beheben
Im Jahr 2025 ist HTTP/1.1 allgegenwärtig – aber nicht unbedingt sichtbar. Server und CDNs geben oft an, HTTP/2 zu unterstützen, stufen eingehende HTTP/2-Anfragen jedoch für die Übertragung an das Backend-System auf HTTP/1.1 herunter, wodurch die meisten Sicherheitsvorteile verloren gehen. Das Herabstufen eingehender HTTP/2-Nachrichten ist sogar noch gefährlicher als die durchgängige Verwendung von HTTP/1.1, da dadurch eine vierte Möglichkeit zur Angabe der Länge einer Nachricht eingeführt wird. In diesem Dokument verwendet er folgende Abkürzungen für die vier wichtigsten Längeninterpretationen:

Auf den ersten Blick könne HTTP/1.1 durchaus sicher wirken, räumt Kettle ein. Wer jedoch nur die ursprüngliche Request-Smuggling-Technik und das damals entwickelte Toolkit einsetze, werde heute oft Mühe haben, eine Desynchronisation auszulösen. Doch dieser trügerische Eindruck habe eine technische Erklärung.
Als Beispiel führt er den klassischen CL.TE-Angriff an. Dabei wird der Transfer-Encoding-Header leicht verschleiert, um die Auswertung der Anfrage durch unterschiedliche Systeme zu beeinflussen. Das Angriffsziel: Der vorgeschaltete Frontend-Server interpretiert die Länge der HTTP-Nachricht auf Basis des Content-Length-Headers, während das dahinterliegende Backend die Länge anhand des Transfer-Encoding-Headers berechnet. Diese Diskrepanz ermöglicht es, die Kommunikationsabläufe zwischen den Systemen aus dem Tritt zu bringen – und so gezielt Sicherheitslücken auszunutzen.

Hier ist das simulierte Opfer:

Früher funktionierte dies auf einer Vielzahl von Websites. Heutzutage schlägt die Prüfung wahrscheinlich aus einem der folgenden drei Gründe fehl, selbst wenn Ihr Ziel tatsächlich anfällig ist:
- WAFs verwenden nun reguläre Ausdrücke, um Anfragen mit einem verschleierten Transfer-Encoding-Header oder potenzielle HTTP-Anfragen im Hauptteil zu erkennen und zu blockieren.
- Das /robots.txt-Erkennungs-Gadget funktioniert bei Ihrem speziellen Ziel nicht.
- Es gibt eine serverseitige Race Condition, die diese Technik bei bestimmten Zielen sehr unzuverlässig macht.
Die alternative, zeitbasierte Erkennungsstrategie, die ich in meiner vorherigen Untersuchung vorgestellt habe, ist ebenfalls stark fingerprinted und wird von WAFs blockiert.
Dies hat zu einem Desync-Endspiel geführt – Sie haben dank spielerischer Abhilfemaßnahmen und selektiver Härtungen, die nur dazu dienen, die etablierte Erkennungsmethodik zu unterlaufen, eine Illusion von Sicherheit. Alles sieht sicher aus, bis Sie die kleinste Änderung vornehmen.
In Wahrheit sind HTTP/1.1-Implementierungen so dicht mit kritischen Schwachstellen gespickt, dass man sie buchstäblich versehentlich finden kann.
Fallstudie: Versehentliches Hacken von 24 Millionen Websites
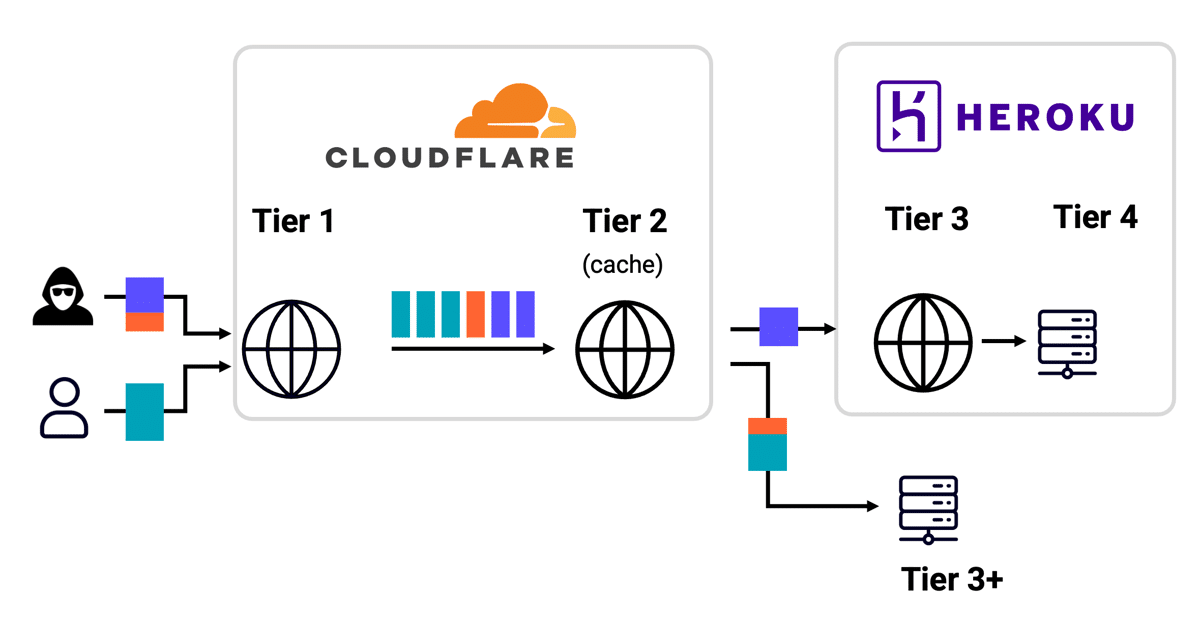
Wie ungeeignet HTTP/1.1 für moderne, mehrschichtige Infrastrukturen ist, zeigt laut Kettle eine Entdeckung des Sicherheitsforschers Wannes Verwimp. Verwimp hatte ein Desynchronisationsproblem im HTTP/2-Protokoll auf einer Website identifiziert, die auf der Plattform Heroku hinter Cloudflare gehostet wurde. Über diese Schwachstelle konnte er Besucher auf eine eigene Website umleiten – und die manipulierten Inhalte wurden sogar im Cloudflare-Cache gespeichert.
Der Clou: Durch das Verfälschen des Cache-Eintrags einer JavaScript-Datei erlangte Verwimp dauerhafte Kontrolle über die betroffene Seite. Brisant wurde der Fall, als klar wurde, dass auch völlig unbeteiligte Drittwebsites – darunter Banken – kompromittiert wurden, obwohl deren Nutzer die eigentliche Zielseite nie aufgerufen hatten.

Grafik Quelle: PortSwigger
Kettle untersuchte den Vorfall und stellte zunächst fest, dass der Angriff vom Frontend-Cache von Cloudflare blockiert wurde und daher nie das Backend erreichte. Sein erster Verdacht: ein Fehlalarm. Doch Tests mit und ohne sogenannten Cache-Buster offenbarten das Gegenteil – ohne den Cache-Buster funktionierte der Angriff, mit ihm nicht.
Grafik Quelle: PortSwigger
Die Ursache war eine interne HTTP/1.1-Desynchronisation in der Cloudflare-Infrastruktur. Das Ausmaß: potenziell 24 Millionen Websites waren für eine vollständige Übernahme verwundbar. „Das ist das Endspiel der Desynchronisation“, kommentiert Kettle – selbst wenn die klassische Angriffsmethodik scheitert, kann die enorme Komplexität auf HTTP/1.1-Basis fatale Lücken schaffen.
Das Problem wurde an Cloudflare gemeldet, innerhalb weniger Stunden behoben und in einem Nachbericht dokumentiert. Verwimp erhielt eine Bug-Bounty-Prämie von 7.000 US-Dollar. Für Außenstehende mögen solche Summen angesichts der Tragweite überraschend niedrig wirken. Kettle erklärt dies mit den festen Obergrenzen vieler Bug-Bounty-Programme – Ausreißer nach oben würden im Whitepaper gesondert hervorgehoben.
„HTTP/1 ist einfach“ – und andere gefährliche Irrtümer
Wie können solch gravierende Fehler überhaupt entstehen? Für Kettle liegt ein Teil der Antwort in der enormen Komplexität moderner Infrastrukturen. So würden etwa Anfragen, die ursprünglich per HTTP/2 bei Cloudflare eintreffen, intern in HTTP/1.1 umgewandelt – nur um anschließend für die Verbindung zum nächsten System wieder auf HTTP/2 zurückkonvertiert zu werden.
Das eigentliche Problem sieht der Forscher jedoch in einem weitverbreiteten Missverständnis: Viele betrachten HTTP/1.1 als robuste und universell geeignete Basis für jede Art von System. Besonders Entwickler ohne Erfahrung im Betrieb von Reverse-Proxys seien oft überzeugt, dass HTTP/1.1 „einfach“ und damit auch sicher sei. Die Realität sei jedoch eine andere – spätestens, wenn man beginne, HTTP/1.1 zu „proxen“.
Kettle illustriert das mit fünf Irrtümern, die er selbst einmal für wahr hielt:
-
Eine HTTP/1.1-Anfrage kann nicht direkt an einen Vermittler gerichtet werden.
-
Eine HTTP/1.1-Antwort enthält alles, was ein Proxy zum Parsen benötigt.
-
Eine HTTP/1.1-Antwort kann nur einen Header-Block enthalten.
-
Eine vollständige HTTP/1.1-Antwort erfordert eine vollständige Anfrage.
Gerade hinter den letzten drei „Lügen“ verberge sich eine technische Realität, die viele unterschätzen: Ein Proxy muss teils schon vor Erhalt der gesamten Anfrage mehrere Header-Blöcke korrekt verarbeiten können, um zu wissen, wie viele Antwortbytes er vom Backend lesen muss. Mitunter trifft die komplette Antwort ein, bevor der Client seine Anfrage überhaupt vollständig gesendet hat.
Für Kettle steht fest: HTTP/1.1 ist voller Fallstricke, die regelmäßig Millionen von Websites in Gefahr bringen. Sechs Jahre lang habe man versucht, Implementierungen zu patchen, um diese Risiken einzudämmen – ohne die zugrunde liegende Unsicherheit zu beseitigen. „Es muss verschwinden“, fordert er. Nur wenn die Branche gemeinsam aufzeigt, dass HTTP/1.1 unsicher ist und Desync-Angriffe weiter zunehmen werden, könne sich etwas ändern.
Alle im Artikel beschriebenen Fallstudien seien im Rahmen autorisierter Sicherheitstests identifiziert, vertraulich gemeldet und – sofern nicht anders vermerkt – behoben worden. Namentlich erwähnte Unternehmen stünden für ein reifes Sicherheitsprogramm. Die während der Untersuchungen erzielten Prämien habe er gemeinsam mit seinen Kollegen geteilt, seinen eigenen Anteil habe PortSwigger verdoppelt und an eine lokale Wohltätigkeitsorganisation gespendet.
Strategie für das „Desync-Endspiel“
Im fortgeschrittenen Stadium der Desynchronisationsforschung – dem, was Kettle das „Desync-Endspiel“ nennt – wird die Erkennung verwundbarer Systeme immer schwieriger. Abhilfemaßnahmen, komplexe Systemarchitekturen und teils sehr spezifische Eigenheiten der Zielumgebungen erschweren den direkten Angriff.
Anstatt sich auf fragile Exploits mit zahlreichen Abhängigkeiten zu verlassen, plädiert Kettle für eine zuverlässigere Vorgehensweise: Nicht den Angriff selbst zuerst versuchen, sondern gezielt die zugrunde liegende Schwachstelle aufspüren, die solche Attacken überhaupt ermöglicht. Wer diese Basisprobleme erkennt, könne auch komplexere Ausnutzungshürden überwinden.
Ein Schlüsselimpuls kam 2021 von Daniel Thacher, der auf der „Black Hat Europe“ seinen Ansatz „Practical HTTP Header Smuggling“ präsentierte. Thacher nutzte gezielt den Content-Length-Header, um Parser-Diskrepanzen – also abweichende Interpretationen zwischen verschiedenen Serverkomponenten – aufzuspüren.
Die Methode überzeugte Kettle so sehr, dass er nach eigenen Tests beschloss, eine eigene Implementierung von Grund auf neu zu entwickeln, einige Details zu verändern und die Resultate zu beobachten. Das Ergebnis ist ein Werkzeug, das sich nach seinen Worten als „äußerst effektiv“ erwiesen hat – und das er nun als Open-Source-Erweiterung „HTTP Request Smuggler v3.0“ für die Burp Suite veröffentlicht.
Der neue Scanner analysiert drei zentrale Elemente, um mögliche Diskrepanzen aufzudecken, und liefert dabei klar kategorisierte Ergebnisse.

Grafik Quelle: PortSwigger
V-H- und H-V-Diskrepanzen erkennen
Im nächsten Schritt erläutert Kettle, wie sein neues Tool HTTP Request Smuggler v3.0 konkrete Parser-Diskrepanzen identifiziert und interpretiert.
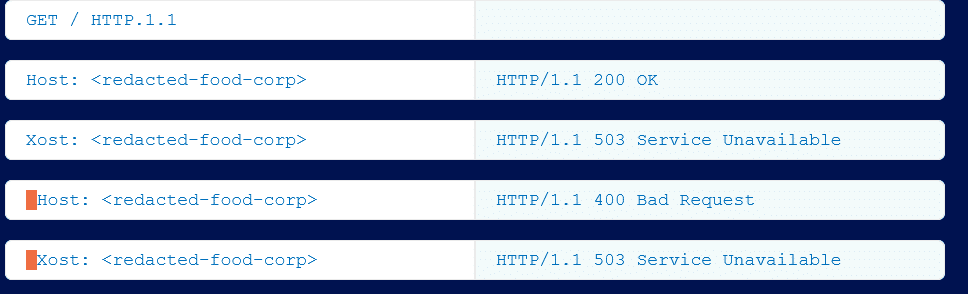
In einem Beispiel sendete das Werkzeug eine Anfrage mit einem teilweise maskierten Host-Header. Das Resultat: Der Server reagierte mit einer Antwort, die weder beim Senden eines regulären Host-Headers, noch beim vollständigen Weglassen oder Austauschen durch einen beliebig maskierten Header auftrat. Für Kettle ist dies ein klarer Indikator, dass innerhalb der Serverkette – also zwischen Frontend und Backend – eine Parser-Diskrepanz existiert.
Er unterscheidet dabei zwei Grundtypen:
-
Visible-Hidden (V-H): Der maskierte Host-Header wird vom Frontend erkannt, bleibt dem Backend jedoch verborgen.
-
Hidden-Visible (H-V): Das Frontend ignoriert den Header, während das Backend ihn verarbeitet.
Oft lasse sich anhand der Antwortmuster ableiten, welcher Fall vorliegt – entscheidend sei, ob die Reaktion eher aus dem Frontend oder dem Backend stammt. Dabei sei es nicht der konkrete HTTP-Statuscode, der zählt, sondern schlicht, dass die Antworten unterschiedlich ausfallen. Im vorliegenden Beispiel handelte es sich um eine V-H-Diskrepanz.
Grafik Quelle: PortSwigger
Von V-H-Diskrepanz zu CL.0-Desynchronisation
V-H-Diskrepanzen lassen sich laut Kettle in konkrete Angriffe umwandeln – etwa in einen TE.CL-Exploit, indem der Transfer-Encoding-Header vor dem Backend verborgen wird, oder in einen CL.0-Exploit, bei dem der Content-Length-Header maskiert wird. Seine Empfehlung: CL.0 bevorzugen, da dieser seltener von Web Application Firewalls (WAF) blockiert wird.
Bei vielen V-H-Zielen, so Kettle, sei die Ausnutzung unkompliziert gewesen. In einem Fall schlug der Ansatz jedoch fehl, weil der Frontend-Server GET-Anfragen mit Body ablehnte. Die Lösung war simpel: auf die HTTP-Methode OPTIONS umstellen. Genau diese Fähigkeit, technische Hürden zu erkennen und zu umgehen, mache das Scannen nach Parser-Diskrepanzen so wertvoll.
Für Ziele in niedrig dotierten Bug-Bounty- oder Vulnerability-Disclosure-Programmen (VDPs) investierte Kettle nach eigener Aussage keine Zeit in voll ausgearbeitete Proof-of-Concepts – der Aufwand lohne wirtschaftlich nicht.
Breite Abdeckung durch variable Erkennungsstrategien
Das Tool kombiniert unterschiedliche Header, Permutationen und Strategien, um eine maximale Erkennungsrate zu erzielen. So identifizierte es etwa bei demselben Host-Header mit identischer Permutation – einem führenden Leerzeichen vor dem Headernamen – durch den Einsatz einer anderen Strategie (doppelter Host-Header mit ungültigem Wert) ein weiteres V-H-Ziel, das sich leicht mit einem CL.0-Desync ausnutzen ließ.
Besonders Web-VPNs hält Kettle für riskant: Sie wiesen oft fehlerhafte HTTP-Implementierungen auf und sollten keinesfalls hinter einem Reverse-Proxy betrieben werden.
Risikoerkennung durch Abweichung von Parsing-Standards
Der Diskrepanz-Scanner kann auch Server entlarven, die von etablierten Parsing-Konventionen abweichen und dadurch angreifbar werden, wenn sie hinter einem Reverse-Proxy stehen. So entdeckte Kettle bei einem nicht näher genannten Zielsystem, dass es \n\n nicht als Ende des HTTP-Header-Blocks wertete.
Für den Direktzugriff sei dies unkritisch, so Kettle. Doch laut RFC 9112 „KANN“ ein Empfänger ein einzelnes LF als Zeilenende erkennen – was in bestimmten Proxy-Konstellationen ausnutzbar wäre. Die Schwachstelle wurde auf eine fehlerhafte HTTP-Bibliothek zurückgeführt; ein Patch ist in Arbeit. Solche „theoretischen“ Funde brächten zwar selten hohe Prämien, könnten aber erheblich zur allgemeinen Sicherheit beitragen.
H-V-Diskrepanz auf Microsoft IIS hinter AWS ALB
Das Tool fand zudem zahlreiche Systeme, die Microsoft IIS hinter einem AWS Application Load Balancer (ALB) betreiben – mit einer H-V-Diskrepanz: Ein verschleierter Host-Header wird von ALB ignoriert und ungeprüft an das Backend weitergeleitet.
Klassisch ließe sich dieser Fehler über einen CL.TE-Desync ausnutzen, da Transfer-Encoding üblicherweise Vorrang vor Content-Length hat. AWS’ „Desync Guardian“ blockiert diese Methode jedoch. Zwar legte Kettle das Thema beiseite, doch der Sicherheitsforscher Thomas Stacey fand unabhängig davon eine Umgehung über H2.TE-Desync. Selbst wenn diese Lücke geschlossen wird, bleibt die Möglichkeit, Header einzuschleusen – was unter anderem IP-Spoofing und teils die vollständige Umgehung von Authentifizierung ermöglicht.
AWS sei der Schwachstelle bekannt, habe aber aus Kompatibilitätsgründen mit älteren, fehlerhaften HTTP/1-Clients beschlossen, sie nicht zu schließen. Betroffene könnten das Problem selbst beheben, indem sie folgende Einstellungen setzen:
-
routing.http.drop_invalid_header_fields.enabled -
routing.http.desync_mitigation_mode = strictest
Für Kettle ist dies ein Lehrbeispiel für ein strukturelles Risiko: Wer Cloud-Proxys nutzt, importiert automatisch auch die technischen Schulden des Anbieters – und damit potenzielle Sicherheitslücken – in die eigene Infrastruktur.
Ausnutzen von H-V ohne Transfer-Encoding
Der nächste große Durchbruch in dieser Forschung kam, als er eine H-V-Diskrepanz auf einer bestimmten Website entdeckte, die alle Anfragen mit Transfer-Encoding blockiert und damit CL.TE-Angriffe unmöglich macht. Es gab nur einen Weg, um weiterzukommen: einen 0.CL-Desync-Angriff.
0.CL-Desynchronisationsangriffe
Der 0.CL-Deadlock
0.CL-Desynchronisationsangriffe gelten allgemein als nicht ausnutzbar. Um zu verstehen, warum dies so ist, betrachten Sie, was passiert, wenn Sie den folgenden Angriff an ein Ziel mit einer H-V-Parser-Diskrepanz senden:

Das Frontend sieht den Content-Length-Header nicht und betrachtet daher die orangefarbene Nutzlast als Beginn einer zweiten Anfrage. Das bedeutet, dass es die orangefarbene Nutzlast puffert und nur den Header-Block an das Backend weiterleitet:

Das Backend sieht den Content-Length-Header und wartet daher auf das Eintreffen des Hauptteils. In der Zwischenzeit wartet das Frontend auf die Antwort des Backends. Schließlich läuft einer der Server ab und setzt die Verbindung zurück, wodurch der Angriff abgebrochen wird. Im Wesentlichen führen 0.CL-Desync-Angriffe in der Regel zu einem Deadlock der Upstream-Verbindung.
Die nächsten Schritte gestalten sich wie folgt:
Umwandlung von 0.CL in CL.0 mit einer doppelten Desynchronisierung
Weitere Desynchronisierungsangriffe stehen bevor
Expect-basierte Desynchronisierungsangriffe
- Umgehung der Entfernung von Antwort-Headern
- 0.CL-Desynchronisierung über Vanilla Expect – T-Mobile
- 0.CL-Desynchronisierung über verschleiertes Expect – Gitlab
- CL.0-Desync über Vanilla Expect – Netlify CDN
- CL.0-Desync über verschleiertes Expect – Akamai CDN
Abwehr von HTTP-Desync-Angriffen
- Warum das Patchen von HTTP/1.1 nicht ausreicht
- Wie sicher ist HTTP/2 im Vergleich zu HTTP/1?
- Wie Sie mit HTTP/1.1 überleben können
- Wie Sie dazu beitragen können, HTTP/1.1 zu beenden
Fazit
Nach sechs Jahren intensiver Forschung zieht James Kettle eine klare Bilanz: HTTP/1.1 leidet unter einem grundlegenden Designfehler, der Websites immer wieder für kritische Angriffe verwundbar macht. Einzelne Hotfixes und Implementierungspatches konnten mit der fortschreitenden Bedrohungslage nicht Schritt halten.
Für ihn gibt es nur eine langfristig tragfähige Lösung: der vollständige Umstieg auf Upstream HTTP/2. Zwar sei dies kein schneller Prozess, doch der Weg beginne mit Aufklärung. „Nur wenn wir deutlich machen, wie gefährlich Upstream HTTP/1.1 wirklich ist, können wir seine Abschaffung vorantreiben“, so Kettle.
Unsere Leseempfehlungen

Fachartikel

OpenAI präsentiert GPT-5.2-Codex: KI-Revolution für autonome Softwareentwicklung und IT-Sicherheit

Speicherfehler in Live-Systemen aufspüren: GWP-ASan macht es möglich

Geparkte Domains als Einfallstor für Cyberkriminalität: Über 90 Prozent leiten zu Schadsoftware weiter

Umfassender Schutz für geschäftskritische SAP-Systeme: Strategien und Best Practices

Perfide Masche: Wie Cyberkriminelle über WhatsApp-Pairing ganze Konten übernehmen
Studien
![Featured image for “Phishing-Studie deckt auf: [EXTERN]-Markierung schützt Klinikpersonal kaum”](https://www.all-about-security.de/wp-content/uploads/2025/12/phishing-4.jpg)
Phishing-Studie deckt auf: [EXTERN]-Markierung schützt Klinikpersonal kaum

Gartner-Umfrage: Mehrheit der nicht geschäftsführenden Direktoren zweifelt am wirtschaftlichen Wert von Cybersicherheit

49 Prozent der IT-Verantwortlichen in Sicherheitsirrtum

Deutschland im Glasfaserausbau international abgehängt

NIS2 kommt – Proliance-Studie zeigt die Lage im Mittelstand
Whitepaper

State of Cloud Security Report 2025: Cloud-Angriffsfläche wächst schnell durch KI

BITMi zum Gutachten zum Datenzugriff von US-Behörden: EU-Unternehmen als Schlüssel zur Datensouveränität

Agentic AI als Katalysator: Wie die Software Defined Industry die Produktion revolutioniert

OWASP veröffentlicht Security-Framework für autonome KI-Systeme

Malware in Bewegung: Wie animierte Köder Nutzer in die Infektionsfalle locken
Hamsterrad-Rebell
Platform Security: Warum ERP-Systeme besondere Sicherheitsmaßnahmen erfordern
Daten in eigener Hand: Europas Souveränität im Fokus

Sicherer Remote-Zugriff (SRA) für Operational Technology (OT) und industrielle Steuerungs- und Produktionssysteme (ICS)

Identity und Access Management (IAM) im Zeitalter der KI-Agenten: Sichere Integration von KI in Unternehmenssysteme
