29. Oktober 2025
Zuschauer von Sport-, Gaming- und interaktiven Events erwarten Streaming in Echtzeit mit minimaler Latenz. Um diesem Anspruch gerecht zu werden, haben sich die Branche und Entwickler auf zwei Protokolle verständigt: Low-Latency HLS (LL-HLS) und Low-Latency DASH (LL-DASH).
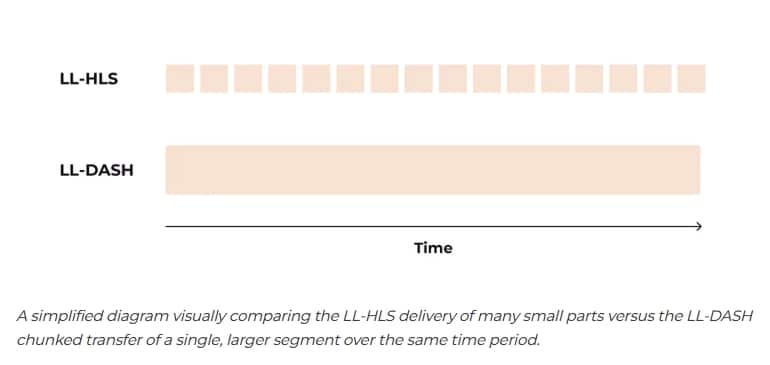
Obwohl beide dasselbe Ziel verfolgen, unterscheiden sie sich grundlegend in der Umsetzung. LL-HLS liefert Videos in einer Reihe kleiner, einzelner Dateien, während LL-DASH einen kontinuierlichen Download eines größeren, in Segmente zerlegten Inhalts bereitstellt. Dieser Unterschied betrifft nicht nur die Syntax, sondern wirkt sich auch stark auf das Verhalten von Packager, CDN und Player aus.
Diese Dualität stellt eine technische Herausforderung dar: Wie lässt sich eine einzige, effiziente und kostengünstige Pipeline entwickeln, die beide Protokolle gleichzeitig aus einer Quelle bedient?
Gcore hat sich dieser Aufgabe gestellt. Das Ergebnis ist eine robuste Pipeline, die Streams mit einer Latenz von etwa 2,0 Sekunden für LL-DASH und 3,0 Sekunden für LL-HLS liefert. Der folgende Bericht beschreibt die Entwicklung dieser Lösung.
Die Dualität verstehen
Um eine einheitliche Streaming-Pipeline zu entwickeln, war zunächst ein genaues Verständnis der Unterschiede auf Übertragungsebene erforderlich.
LL-DASH: die kontinuierliche Übertragung
MPEG-DASH verwendet traditionell eine einzelne Manifestdatei, die Mediensegmente anhand ihres Timings definiert. Low-Latency DASH baut darauf auf und nutzt Chunked CMAF-Segmente.
Dabei kann eine Datei, die noch auf den Server geschrieben wird, vom Player angefordert werden. Der Server sendet sie in kleinen Abschnitten mittels Chunked Transfer Encoding, sodass der Player die Wiedergabe starten kann, sobald genügend Daten vorliegen.
-
Einzelne, langlebige Dateien: Segmente dauern 2 bis 6 Sekunden, werden jedoch während der Erstellung bereitgestellt.
-
Zeitbasierte Anfragen: Der Player weiß, wann ein Segment verfügbar sein sollte, und fordert es an; der Server sendet, was bisher vorliegt.
-
Player-gesteuerte Latenz: Das Manifest enthält ein targetLatency-Attribut, das dem Player vorgibt, wie nah an der Live-Kante abgespielt werden soll.
LL-HLS: die schnelle Bereitstellung
LL-HLS erweitert das traditionelle playlist-basierte HLS, indem Segmente in kleinere Teile, sogenannte Parts, aufgeteilt werden.
Der Server kündigt bevorstehende Parts bereits im Manifest an, bevor sie vollständig verfügbar sind. Der Player fordert einen Part an, doch der Server hält die Anfrage offen, bis der Part bereit ist – ein Verfahren, das als Blocking Playlist Reload bekannt ist.
-
Viele kleine Dateien (Parts): Ein 2-Sekunden-Segment kann in vier 0,5-Sekunden-Teile unterteilt werden, die einzeln angefordert werden.
-
Manifestgesteuerte Aktualisierungen: Der Server aktualisiert das Manifest kontinuierlich und verwendet spezielle Tags wie #EXT-X-PART-INF und #EXT-X-SERVER-CONTROL zur Verwaltung der Bereitstellung.
-
Vom Server erzwungene Zeitsteuerung: Der Server bestimmt, wann der Player Daten empfängt, indem er Anfragen zurückhält, was die Synchronisierung aller Zuschauer unterstützt.
Grafik Quelle: Gcore
Diese beiden Philosophien stellen unterschiedliche Anforderungen an ein CDN. LL-DASH erfordert, dass das CDN teilweise vollständige Dateien intelligent zwischenspeichert und bereitstellt. LL-HLS erfordert, dass das CDN eine große Menge kurzer, sporadischer Anfragen verarbeitet und Verbindungen für Manifest-Aktualisierungen offen hält. Ein herkömmliches CDN ist für keines von beiden optimiert.
Entwicklung einer einheitlichen Strategie
Um eine einheitliche Pipeline für zwei unterschiedliche Bereitstellungsmodelle zu entwickeln, konzentrierte sich Gcore auf ein zentrales Element: den Keyframe.
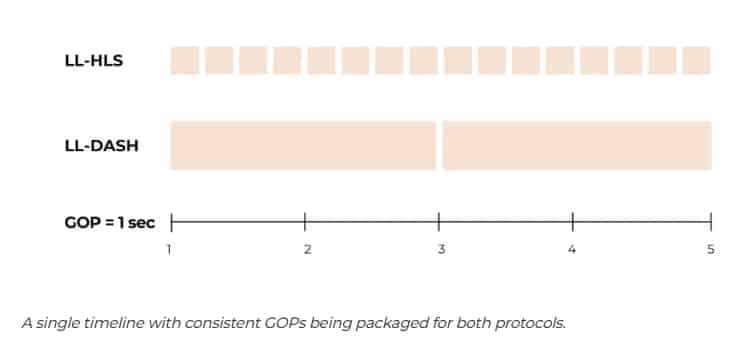
Die Wiedergabe kann nur von einem Keyframe (I-Frame) aus starten. Deshalb ist die Platzierung von Keyframes, die die Group of Pictures (GOP) definieren, die grundlegende Ebene, die sowohl LL-HLS als auch LL-DASH berücksichtigen müssen. Durch ein konsistentes Keyframe-Intervall im Quellstrom ließ sich eine vorhersehbare Medienzeitachse erstellen, die in den Manifesten beider Protokolle unterschiedlich beschrieben werden kann.
Grafik Quelle: Gcore
Diese Erkenntnis bildete die Basis für eine konfigurierte Pipeline, wobei jeder Parameter technische Kompromisse erforderte:
-
GOP: 1 Sekunde. Ein häufiges 1-Sekunden-GOP ermöglicht eine extrem schnelle Stream-Erfassung, da der Player nie länger als eine Sekunde auf einen Keyframe warten muss. Der Nachteil ist eine höhere Bitrate: Im Vergleich zu einem 2-Sekunden-GOP steigt sie um 10–15 %, da mehr Vollbilddaten gespeichert werden. Für interaktive Echtzeitanwendungen wurde die Startgeschwindigkeit gegenüber Bitrateneinsparungen priorisiert.
-
Segmentgröße: 2 Sekunden. Diese Dauer ist kurz genug, um die Manifestgröße für LL-DASH und moderne HLS-Player überschaubar zu halten. Gleichzeitig verhindert sie bei älteren HLS-Clients, dass die Wiedergabe zu weit hinter dem Live-Edge zurückbleibt, wodurch die Latenz gering bleibt.
-
Teilgröße: 0,5 Sekunden. Für LL-HLS liefert dies vier Aktualisierungen pro Segment. Diese Frequenz ermöglicht eine Latenz von unter 3 Sekunden, ohne das Netzwerk durch übermäßigen Request-Overhead zu belasten, wie es bei Teilgrößen von 100–200 Millisekunden der Fall wäre.
Kaskadierende Herausforderungen entlang der Pipeline
1. Ingest: Vorhersagbarkeit ist entscheidend
Für eine saubere, synchronisierte Ausgabe ist eine stabile und vorhersagbare Eingabe unerlässlich. Gcore stellte fest, dass die Encoder-Einstellungen der Quellstreams entscheidend sind. Instabile Quellen mit variabler Bitrate oder unregelmäßiger Keyframe-Platzierung erschweren die Übertragung mit geringer Latenz.
Empfohlen werden Einstellungen, bei denen Geschwindigkeit und Vorhersagbarkeit Vorrang vor Komprimierungseffizienz haben:
-
Ratensteuerung: konstante Bitrate (CBR)
-
Keyframe-Intervall: festes Intervall (z. B. alle 30 Frames bei 30 FPS, passend zum 1-Sekunden-GOP)
-
Encoder-Einstellung: zerolatency
-
Erweiterte Optionen: B-Frames deaktivieren (bframes=0) und Szenenschnitt-Erkennung ausschalten (scenecut=0), um die Keyframe-Platzierung exakt zu steuern
ffmpeg -re -i „source.mp4“ -c:a aac -c:v libx264 \ -profile:v baseline -tune zerolatency -preset veryfast \ -x264opts „bframes=0:scenecut=0:keyint=30“ \ -f flv „rtmp://your-ingest-url“
2. Transcodierung und Verpackung
In der Transcodierungs- und Just-In-Time-Packaging-Ebene (JITP) findet die eigentliche Vereinheitlichung statt. Hier wird ein Stream verarbeitet, der noch unvollständig ist. Der Packager muss Manifeste und Teile aus Mediendateien erzeugen, während der Transcoder diese noch schreibt. Dies erfordert eine eng gekoppelte Architektur, in der der Packager direkt aus dem Transcoder-Puffer lesen kann.
Um mit der Unvorhersehbarkeit von Live-Quellen, insbesondere benutzergenerierten Inhalten über WebRTC, umzugehen, nutzt Gcore einen hybriden Workflow:
-
GPU-Worker (Nvidia/Intel): Verantwortlich für die anspruchsvolle Decodierung und Codierung, entscheidend für minimale Latenz und Unterstützung fortschrittlicher Farbformate wie HDR+.
-
Software-Worker und Filter: Sorgen für Flexibilität. Wenn ein Live-Stream von mobilen Geräten aufgrund schlechter Verbindung die Auflösung oder Bildrate ändert, kann die Software-Ebene den Stream stabilisieren, etwa durch Skalierung und Überlagerung auf eine schwarze Leinwand.
Das JITP erstellt so aus einer einzelnen, widerstandsfähigen Quelle drei synchronisierte Inhaltstypen:
-
LL-DASH (CMAF)
-
LL-HLS (CMAF)
-
Standard-HLS (MPEG-TS) für Abwärtskompatibilität
3. CDN-Bereitstellung: zwei Probleme auf einmal lösen
Die CDN-Ebene stellte die größte technische Herausforderung dar. Sie musste gleichzeitig zwei unterschiedliche Anforderungen meistern.
Für LL-DASH entwickelte Gcore ein benutzerdefiniertes Caching-Modul, den chunked-proxy. Bei der ersten Anfrage eines neuen .m4s-Segments wird der Ursprung kontaktiert, und eingehende Bytes werden sofort an den Client weitergeleitet. Wenn ein zweiter Client dasselbe Segment anfordert, liefert der Edge-Server die bereits zwischengespeicherten Bytes und ergänzt sie gleichzeitig um neue Daten – ein Multi-Client-Cache für In-Flight-Daten.
Für LL-HLS lagen die Herausforderungen woanders:
-
Blockierte Anfragen: Edge-Server mussten Tausende Manifest-Anfragen für mehrere hundert Millisekunden offen halten, ohne Ressourcen zu überlasten.
-
Intelligentes Caching: Der Cache-Status von Manifesten (MISS, EXPIRED) musste korrekt verwaltet werden, um pro Aktualisierung nur eine Anfrage an den Ursprung zu senden und ein Thundering-Herd-Problem zu vermeiden.
-
Hohe Anfragefrequenz: LL-HLS erzeugt eine Vielzahl kleiner Anfragen. Die Infrastruktur wurde skaliert und optimiert, um diese Daten mit minimalem Overhead bereitzustellen.
Der Vorteil: ultimative Flexibilität für Entwickler
Die technische Leistung von Gcore bietet Entwicklern greifbare Vorteile. Der Hauptvorteil liegt in der Vereinfachung durch eine einheitliche Pipeline, der größte Nutzen jedoch in der Möglichkeit, jede Plattform optimal zu bedienen.
Die komplexe Landschaft der Apple-Geräte veranschaulicht dies:
-
iOS 17.1+: LL-DASH über die neue Managed Media Source (MMS)-API mit einer Latenz von etwa 2,0 Sekunden.
-
iOS 14.0–17.0: natives LL-HLS mit rund 3,0 Sekunden Latenz.
-
Ältere iOS-Versionen: automatischer Rückfall auf Standard-HLS mit einer Latenz von etwa 9 Sekunden.
So können Entwickler auf jedem Gerät das bestmögliche Erlebnis bieten – und das alles von einem einzigen Backend und einer einzigen Live-Quelle, ohne zusätzliche Konfiguration.
Nicht blind fliegen: Beobachtbarkeit in einer Welt mit geringer Latenz
Komplexe Systeme benötigen Transparenz. Herkömmliche Metriken reichen bei Streaming mit geringer Latenz nicht aus. Es reicht nicht, nur die response_time aus dem CDN-Protokoll zu betrachten.
-
Bei LL-HLS ist eine hohe response_time (z. B. 500 ms) normal, da sie zeigt, dass der Server die Anfrage korrekt hält, während er auf den nächsten Part wartet. Eine niedrige response_time kann tatsächlich ein Problem signalisieren. Gcore überwacht die Manifest Hold Time, um sicherzustellen, dass dieser Blockierungsmechanismus wie vorgesehen funktioniert.
-
Bei LL-DASH kann ein Player, der einen noch nicht fertigen Chunk anfordert, einen 404-Fehler erhalten. Gelegentliche 404s sind normal, ein Anstieg jedoch deutet auf Latenzprobleme zwischen Ursprung und Edge hin. In Kombination mit der Überwachung des Player-Verhaltens über liveCatchup liefert dies ein realistisches Bild des Stream-Zustands.
Gcore: eine Pipeline für alle
LL-HLS und LL-DASH verfolgen unterschiedliche Wege, aber das gleiche Ziel: Echtzeit-Interaktion mit einem globalen Publikum. Durch die gemeinsame Grundlage – den Keyframe – und die gezielte Entwicklung jeder Pipeline-Komponente konnte Gcore die Vereinheitlichung erfolgreich umsetzen.
Das Ergebnis ist ein einziges, robustes System, das Entwicklern die Vorteile beider Protokolle bietet, ohne die Komplexität zweier Infrastrukturen. Damit erreicht Gcore eine Latenz von ±2,0 Sekunden mit LL-DASH und ±3,0 Sekunden mit LL-HLS – die Basis, um die Grenzen des Echtzeit-Streamings weiter zu verschieben.
Bild/Quelle: https://depositphotos.com/de/home.html

Fachartikel

ShinyHunters-Angriffe: Mandiant zeigt wirksame Schutzmaßnahmen gegen SaaS-Datendiebstahl

Phishing-Angriff: Cyberkriminelle missbrauchen Microsoft-Infrastruktur für Betrugsmaschen

Wie Angreifer proprietäre KI-Modelle über normale API-Zugriffe stehlen können

KI-Agenten in cyber-physischen Systemen: Wie Deepfakes und MCP neue Sicherheitslücken öffnen

Sicherheitslücke in Cursor-IDE: Shell-Befehle werden zur Angriffsfläche
Studien
Deutsche Unicorn-Gründer bevorzugen zunehmend den Standort Deutschland

IT-Modernisierung entscheidet über KI-Erfolg und Cybersicherheit

Neue ISACA-Studie: Datenschutzbudgets werden trotz steigender Risiken voraussichtlich schrumpfen

Cybersecurity-Jahresrückblick: Wie KI-Agenten und OAuth-Lücken die Bedrohungslandschaft 2025 veränderten
![Featured image for “Phishing-Studie deckt auf: [EXTERN]-Markierung schützt Klinikpersonal kaum”](https://cdn-ileiehn.nitrocdn.com/EZdGeXuGcNedesCQNmzlOazGKKpdLlev/assets/images/optimized/rev-68905f9/www.all-about-security.de/wp-content/uploads/2025/12/phishing-4.jpg)
Phishing-Studie deckt auf: [EXTERN]-Markierung schützt Klinikpersonal kaum
Whitepaper

DigiCert veröffentlicht RADAR-Bericht für Q4 2025

Koordinierte Cyberangriffe auf polnische Energieinfrastruktur im Dezember 2025

Künstliche Intelligenz bedroht demokratische Grundpfeiler

Insider-Risiken in Europa: 84 Prozent der Hochrisiko-Organisationen unzureichend vorbereitet

ETSI veröffentlicht weltweit führenden Standard für die Sicherung von KI
Hamsterrad-Rebell
NIS2: „Zum Glück gezwungen“ – mit OKR-basiertem Vorgehen zum nachhaltigen Erfolg
Cyberversicherung ohne Datenbasis? Warum CIOs und CISOs jetzt auf quantifizierbare Risikomodelle setzen müssen
Identity Security Posture Management (ISPM): Rettung oder Hype?
Platform Security: Warum ERP-Systeme besondere Sicherheitsmaßnahmen erfordern