24. Februar 2026
Der öffentliche Schlagabtausch zwischen Elon Musk und Anthropic wirft ein Schlaglicht auf eine der zentralen Schwachstellen der KI-Branche: den rechtlich ungeklärten Umgang mit Trainingsdaten. Während das US-amerikanische KI-Labor chinesischen Entwicklern systematische Datenextraktion vorwirft, kontert der xAI-Chef mit Verweis auf Anthropics eigene juristische Vergangenheit.
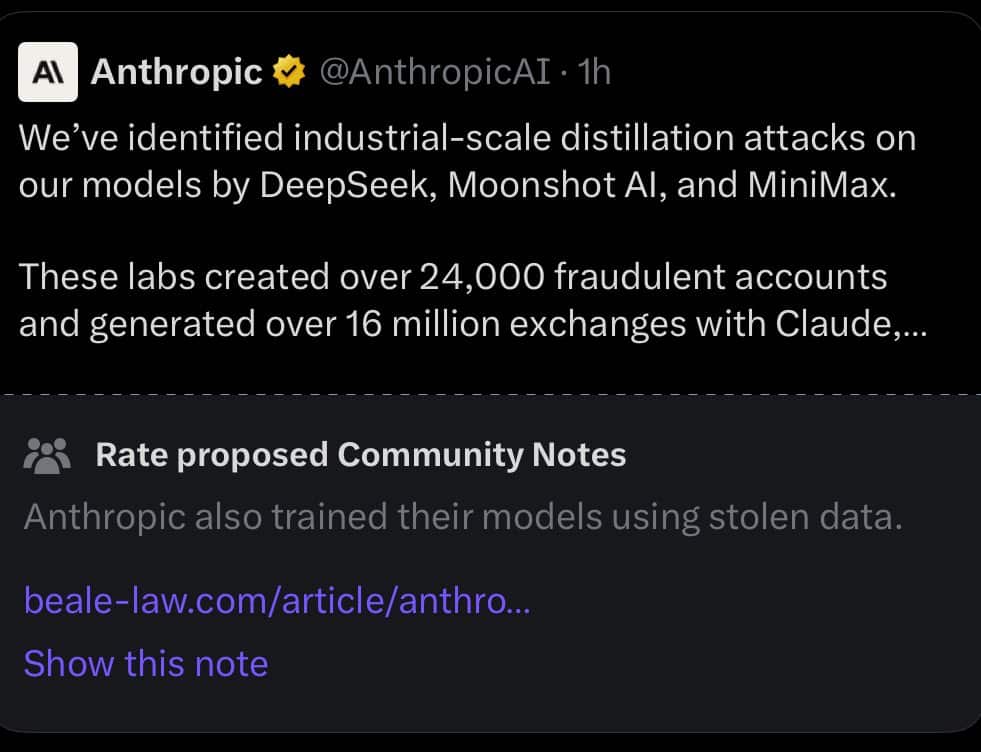
Auslöser des Disputs ist ein Bericht, den Anthropic Anfang der Woche veröffentlichte. Darin beschuldigt das in San Francisco ansässige Unternehmen mehrere chinesische KI-Entwickler – darunter DeepSeek, Moonshot AI und MiniMax – sogenannte Destillationsangriffe in industriellem Ausmaß durchgeführt zu haben. Konkret sollen über 24.000 betrügerische Konten angelegt und mehr als 16 Millionen Interaktionen mit dem hauseigenen Modell Claude generiert worden sein, um dessen Fähigkeiten systematisch zu kopieren.
Bei der Destillation handelt es sich um eine Methode, bei der kleinere Modelle gezielt auf den Ausgaben leistungsstärkerer Systeme trainiert werden, ohne dass dabei direkter Zugang zu den ursprünglichen Trainingsdaten erforderlich ist. Anthropic stuft dieses Vorgehen als Bedrohung für die nationale Sicherheit ein, da es ausländischen Akteuren ermögliche, fortschrittliche KI-Systeme vergleichsweise schnell nachzubauen.
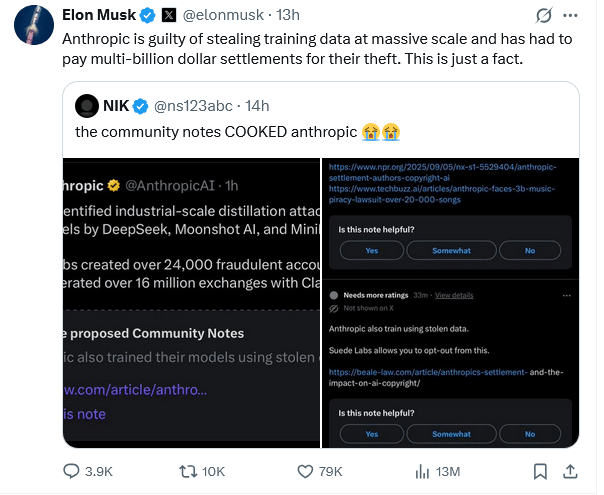
Elon Musk, CEO von xAI und Betreiber der Plattform X, ließ diese Positionierung nicht unkommentiert. Auf X verwies er auf Anthropics eigene Rechtsgeschichte: Das Unternehmen habe Trainingsdaten in großem Umfang unrechtmäßig verwendet und dafür mehrere Milliarden Dollar an Entschädigungen gezahlt – „das ist eine Tatsache“, so Musk.
Tatsächlich einigte sich Anthropic im September 2025 auf einen Vergleich in Höhe von 1,5 Milliarden Dollar in einer Sammelklage von Autoren, die dem Unternehmen vorwarfen, urheberrechtlich geschützte Werke ohne Genehmigung zum Training von Claude verwendet zu haben. Zusätzlich sieht sich das Unternehmen einer weiteren Klage von Musikverlagen ausgesetzt, die Schadensersatz von rund drei Milliarden Dollar fordern – ebenfalls wegen mutmaßlicher Urheberrechtsverletzungen beim Modelltraining.
Der Konflikt verdeutlicht, dass die Frage nach dem legitimen Umgang mit Daten beim Training von KI-Modellen branchenweit ungelöst bleibt – und zunehmend zum Gegenstand juristischer wie öffentlicher Auseinandersetzungen wird.
Entdecke mehr


Fachartikel

Starkiller: Phishing-Framework setzt auf Echtzeit-Proxy statt HTML-Klone

LockBit-Ransomware über Apache-ActiveMQ-Lücke: Angriff in zwei Wellen

Infoblox erweitert DDI-Portfolio: Neue Integrationen für Multi-Cloud und stärkere Automatisierung

KI-Agenten ohne Gedächtnis: Warum persistenter Speicher der Schlüssel zur Praxistauglichkeit ist
Oracle erweitert OCI-Netzwerksicherheit: Zero Trust Packet Routing jetzt mit Cross-VCN-Unterstützung
Studien

CrowdStrike Global Threat Report 2026: KI beschleunigt Cyberangriffe und weitet Angriffsflächen aus

IT-Sicherheit in Großbritannien: Hohe Vorfallsquoten, steigende Budgets – doch der Wandel stockt

IT-Budgets 2026: Deutsche Unternehmen investieren mehr – und fordern messbaren Gegenwert

KI-Investitionen in Deutschland: Solide Datenbasis, aber fehlende Erfolgsmessung bremst den ROI

Cybersicherheit 2026: Agentic AI auf dem Vormarsch – aber Unternehmen kämpfen mit wachsenden Schutzlücken
Whitepaper

Third Party Risk Management – auch das Procurement benötigt technische Unterstützung

EU-Toolbox für IKT-Lieferkettensicherheit: Gemeinsamer Rahmen zur Risikominderung

EU-Behörden stärken Cybersicherheit: CERT-EU und ENISA veröffentlichen neue Rahmenwerke

WatchGuard Internet Security Report zeigt über 1.500 Prozent mehr neuartige Malware auf

Armis Labs Report 2026: Früherkennung als Schlüsselfaktor im Finanzsektor angesichts KI-gestützter Bedrohungen
Hamsterrad-Rebell

Incident Response Retainer – worauf sollte man achten?

KI‑basierte E‑Mail‑Angriffe: Einfach gestartet, kaum zu stoppen

NIS2: „Zum Glück gezwungen“ – mit OKR-basiertem Vorgehen zum nachhaltigen Erfolg

Cyberversicherung ohne Datenbasis? Warum CIOs und CISOs jetzt auf quantifizierbare Risikomodelle setzen müssen