On one hand no. AWS handled the issue very well. Problems were reported at around 10:45am (ET) and within an hour AWS had acknowledged the issue and found the cause. It executed mitigations and within a few hours the problem was mostly resolved.
When things go wrong, we’re often quick to point out the frailty of the cloud as ‘someone else’s computer’ but actually, the cloud providers usually respond and resolve issues far faster than in-house IT teams could.
On the other hand, outages like this serve to highlight just how dependent we are on AWS in particular, but also a small number of very powerful cloud companies.
The hosting landscape has changed dramatically in just a few years. A decade ago, the market was much more fragmented with hundreds (or thousands) of data centre and hosting companies each with a relatively small portion of market-share. Now, we have an oligarchy of the major cloud providers.
This issue for AWS affected Amazon’s own services like Ring and IMDB. It also affected Tinder, Roku, Coinbase, iRobot and Duolingo.
An enormous number of SaaS business services are hosted on AWS and when these tools are hit, the knock-on effect impacts thousands of downstream businesses. The technology supply-chain is a big, interconnected web, but often it leads back to AWS, Microsoft Azure or Google.
The other positive we can take from this incident is that it was localised to specific AWS Regions. In many ways, we shouldn’t think of AWS as just one cloud, but rather a collection of connected data centres spread across the world. It is designed so that an issue in US-East-1 doesn’t affect Seoul or London.
Architecting for continuity is always a balance of risk vs cost. Infrastructure should always be spread across multiple Availability Zones (the actual data centres) but can be spread over multiple Regions or even cloud providers to protect against wider outages. Depending on the criticality of the application, you can make it as resilient as it demands.
Peter Groucutt, Managing Director at Databarracks
Fachartikel





Studien

Threat Report: Anstieg der Ransomware-Vorfälle durch ERP-Kompromittierung um 400 %

Studie zu PKI und Post-Quanten-Kryptographie verdeutlicht wachsenden Bedarf an digitalem Vertrauen bei DACH-Organisationen

Zunahme von „Evasive Malware“ verstärkt Bedrohungswelle

Neuer Report bestätigt: Die Zukunft KI-gestützter Content Creation ist längst Gegenwart

Neue Erkenntnisse: Trend-Report zu Bankbetrug und Finanzdelikten in Europa veröffentlicht
Whitepaper




Unter4Ohren

Datenklassifizierung: Sicherheit, Konformität und Kontrolle

Die Rolle der KI in der IT-Sicherheit
CrowdStrike Global Threat Report 2024 – Einblicke in die aktuelle Bedrohungslandschaft
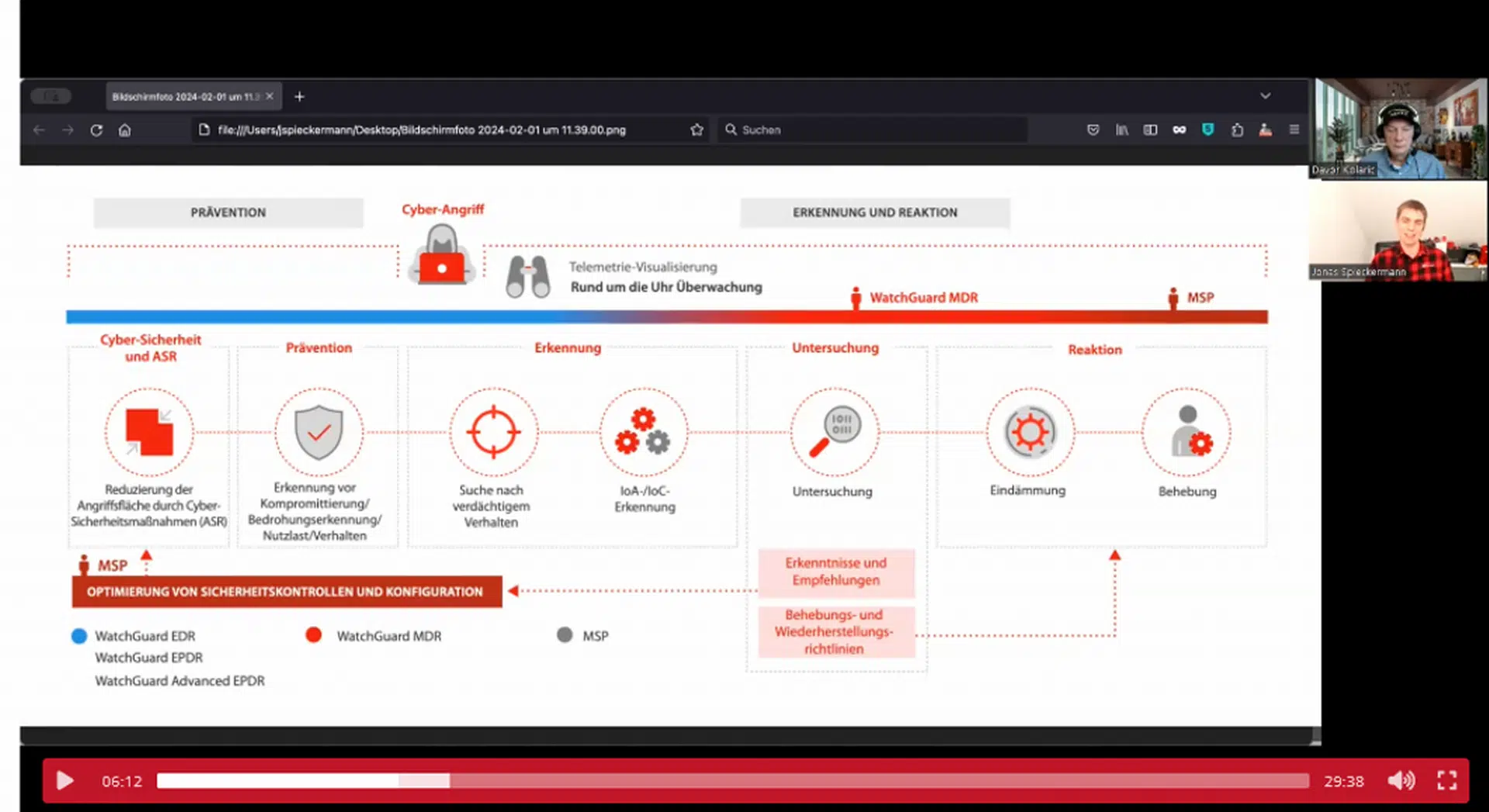
WatchGuard Managed Detection & Response – Erkennung und Reaktion rund um die Uhr ohne Mehraufwand