Jetzt, da sich der Innovationsstaub vom Hype um ChatGPT gelegt hat, ist es vielleicht an der Zeit, die volle Tragweite dieser Technologie zu beleuchten. Sie hilft zwar schlaflosen Studenten bei Hausarbeiten und gibt Werbetextern einen Kreativitätsschub, hat aber auch eine potenziell dunkle Kehrseite. David Carvalho, CEO und Mitbegründer von Naoris Protocol, packt einige der nicht so schönen Aspekte der aufkommenden KI-Technologie und ihr Potenzial aus, Unternehmen weltweit zu schädigen.
Wie kann ChatGPT verwendet werden, um Code auszunutzen, und kann es wirklich Code erstellen?
Die kurze Antwort lautet: Ja. ChatGPT von OpenAI ist ein auf einem großen Sprachmodell (LLM) basierender Textgenerator für künstliche Intelligenz (KI), der lediglich eine Eingabeaufforderung mit einer normalen englischen Sprachabfrage benötigt.
GPT steht für Generative Pre-Trained Transformer (generativer, vortrainierter Transformator). Er wird auf einer großen Datenmenge von Texten aus dem Internet trainiert, die Milliarden von Wörtern enthält, und lernt so auf alle Themen in den Proben. Es kann alles „denken“, von Aufsätzen, Gedichten, E-Mails und ja, auch Computercode.
Es kann Code aus einfachem englischen Text generieren oder neuen und bestehenden Code als Eingabe erhalten. Dieser Code kann jedoch für bösartige Zwecke ausgenutzt werden, oder, was noch wichtiger ist, er kann für defensive und schützende Anwendungen verwendet werden, es kommt nur auf die Absichten des Benutzers an. Während Google Ihnen einen Artikel zeigen kann, wie Sie ein bestimmtes Programmierproblem lösen können, könnte ChatGPT den Code für Sie schreiben. Dies ist ein entscheidender Vorteil, denn es bedeutet, dass Entwickler nahezu sofortige Sicherheitsprüfungen des Anwendungscodes und des Smart-Contract-Codes durchführen könnten, um Schwachstellen und Exploits vor der Implementierung zu finden. Es würde Unternehmen auch ermöglichen, ihre Bereitstellungsprozesse zu ändern, um sie vor der Einführung gründlicher zu machen und Schwachstellen nach der Bereitstellung zu reduzieren. Dies wäre ein wichtiger Beitrag zur Bekämpfung von Schäden durch Cyberbedrohungen, die bis 2025 voraussichtlich 10 Billionen US-Dollar übersteigen werden.
Was sind derzeitige Einschränkungen?
Der Nachteil ist, dass böswillige Akteure KI so programmieren können, dass sie Schwachstellen finden, um jeden beliebten, bestehenden Codierungsstandard, Smart Contract-Code oder sogar bekannte Computerplattformen und Betriebssysteme auszunutzen. Dies bedeutet, dass Tausende von bestehenden Umgebungen, die in der realen Welt komplex und gefährdet sind, plötzlich (kurzfristig) offengelegt werden könnten.
KI hat kein Bewusstsein, sie ist ein Algorithmus, der auf mathematischen Prinzipien, Gewichtungen und Vorurteilen beruht. Ihr entgehen grundlegende Vorurteile, Wissen, Emotionen und Feinheiten, die nur der Mensch sieht. Er sollte als ein Werkzeug betrachtet werden, das Schwachstellen verbessert, die von Menschen fehlerhaft kodiert wurden. Obwohl es die Qualität der Kodierung von Web2- und Web3-Anwendungen potenziell erheblich verbessern kann, können und sollten wir seinem Ergebnis nicht völlig vertrauen. Trotz dieser vorsichtigen Herangehensweise sollten wir uns bemühen, darauf zu vertrauen, dass wir in der Lage sein werden, der Basislinie in Zukunft zu vertrauen.
Die Entwickler werden weiterhin die KI-Ausgaben lesen und kritisieren müssen, indem sie ihre Muster lernen und nach Schwachstellen suchen, wobei sie sich der Tatsache bewusst sein müssen, dass Bedrohungsakteure sie kurzfristig für schändliche Zwecke nutzen. Ich glaube jedoch, dass der Netto-Output langfristig eine positive Ergänzung zur Reife aller Prozesse darstellt. Es wird immer wieder neue Bedrohungen geben, die es zu analysieren und zu entschärfen gilt. Obwohl es also ein großartiges Werkzeug zur Unterstützung der Entwickler sein kann, muss es mit den Entwicklungsteams zusammenarbeiten, um den Code zu stärken und die Systeme zu schützen. Die Angriffsposition wird darin bestehen, Bugs oder Fehler in der Ausgabe der KI und nicht im Code selbst zu finden. Die KI wird ein großartiges Werkzeug sein, aber der Mensch wird hoffentlich das letzte Wort haben. Abgesehen von einigen Schwierigkeiten auf dem Weg dorthin wird sich dies positiv auf das Vertrauen in die Cybersicherheit und die Sicherheit auswirken. Kurzfristig wird die KI Schwachstellen aufdecken, die sehr schnell behoben werden müssen, und es könnte zu einer Häufung von Sicherheitsverletzungen kommen.
Müssen die Vorschriften aktualisiert werden, um diese Modelle einzubeziehen bzw. zu berücksichtigen?
Die Regulierung wird für die Einführung dieser Art von KI von entscheidender Bedeutung sein, aber sie kann auch vermieden werden, weil die derzeitige Regulierung analog ist, d. h. breit angelegt, selbstgesteuert, in der Regel eher reaktiv als proaktiv und unglaublich langsam in der Entwicklung, insbesondere in einem sich schnell verändernden und innovativen „Zielbereich“ wie KI. Die Regulierungsbehörden in ihrer jetzigen Funktion könnten sehr wohl den Überblick verlieren und überfordert sein; sie sollten direkt von Fachleuten auf diesem Gebiet und in der Wissenschaft beraten werden, um schnelle Reaktionen zu gewährleisten. Vielleicht sollten sie die Einrichtung einer völlig separaten Regulierungsbehörde oder eines Ethikrates in Erwägung ziehen, um zu regeln oder grundlegende Regeln dafür aufzustellen, was bei der Nutzung derart leistungsfähiger Technologien mit doppeltem Verwendungszweck nicht zulässig ist. Vorschriften kommen in der Regel erst dann zum Tragen, wenn etwas schief gelaufen ist, und dann dauert es Monate, wenn nicht Jahre, bis die Vorschriften die verschiedenen Iterationen und Genehmigungsverfahren durchlaufen haben. Derzeit ist die Regulierung in diesem Bereich nicht zweckmäßig. Die Möglichkeit, die Geschwindigkeit, mit der KI lernt und ihre Leistung erbringt, zu überwachen und zu regulieren, ist ein dringend benötigter zusätzlicher Baustein für die Einhaltung der Vorschriften.
Die KI selbst muss reguliert werden, die brennende Frage lautet: „Sollte sie zentralisiert werden?“ Wir müssen ernsthaft darüber nachdenken, ob zentralisierte Technologieunternehmen oder Regierungen die Schlüssel in der Hand halten und in der Lage sein sollten, die KI zu beeinflussen, um die Ergebnisse zu beeinflussen. Ein besser geeignetes Modell wäre eine dezentrale Lösung oder zumindest ein dezentrales Verwaltungssystem, das das Vertrauen in die Basissysteme, die die Antworten liefern, gewährleistet und die Daten für die Antworten und alle ihre Prozesse über ein Sicherheitsnetz bereitstellt. Wir sollten vielleicht ein Modell in Betracht ziehen, das der Art und Weise ähnelt, wie Web 3-Entwickler und Validierer entlohnt werden. Die KI sollte über einen Pool professioneller Befürworter verfügen, die einen Anreiz haben, die KI so zu entwickeln und weiterzuentwickeln, dass sie bestimmte gemeinsame ethische Ziele erfüllt, die sicherstellen, dass die Technologie in jedem Sektor, in dem sie eingesetzt wird, zum Guten genutzt wird.
Können Filter entwickelt werden, um diese Modelle zu erkennen?
Ja, aber das würde zu einem „Whack-a-mole“-Effekt führen, ähnlich dem, den wir jetzt haben, es wäre ein guter Versuch, aber definitiv kein Allheilmittel. Filterbasierte ethische Grundsätze könnten programmatisch erstellt werden, um die Modelle von böswilligen oder ausbeuterischen Akteuren zu erkennen oder Bereiche oder Themen zu definieren, die nicht zulässig sind. Es stellt sich jedoch die Frage, wer die Kontrolle über den KI-Code selbst hat und ob wir darauf vertrauen können, dass die KI-Systeme, die die Antworten liefern, nicht voreingenommen sind oder die Integrität der Basisdaten beeinträchtigt ist. Wenn die Basisdaten tatsächlich verfälscht oder kompromittiert wären, müssten wir das zu 100 % wissen.
Die logische Lösung bestünde darin, Netze und Geräte mit dezentralen und verteilten Konsensverfahren zu schützen, so dass der Status und die Vertrauenswürdigkeit der erzeugten Daten als gut, wahr und vertrauenswürdig bekannt sind, und zwar auf eine äußerst widerstandsfähige und kryptografisch starke Weise. Sie müssen überprüfbar und immun gegen lokale Manipulationen oder Unterwanderung durch böswillige Akteure, ob intern oder extern, sein.
Wie geht es nun weiter?
Wie Chat GPT auf den Markt kam, ist vergleichbar mit Supermans Ankunft auf dem Planeten Erde von Krypton aus. Wir wussten nichts von seiner Existenz, bevor er ankam; wir wussten nicht, wie sich seine Kräfte auf die Welt auswirken würden, während er aufwuchs, und wir wussten nicht, wie dunkle Kräfte (Kryponit) das Ergebnis seines Verhaltens beeinflussen könnten. Es wäre anmaßend, wenn nicht gar arrogant, zu behaupten, dass irgendjemand wirklich weiß, wie sich das alles entwickeln wird. Das Einzige, was wir mit Sicherheit wissen, ist, dass sich einige Aspekte der Funktionsweise der Welt unwiderruflich ändern werden. Es wird eine aufregende und fesselnde Reise werden, um zu sehen, wie die Menschheit mit einer weiteren bahnbrechenden Technologie umgeht, die ihrerseits von vielen anderen Innovationen überschattet werden wird. Die Zukunft ist ein Vektor, der seinen eigenen Kurs bestimmen wird, und jeder wird eine Rolle spielen, um sicherzustellen, dass er für die Menschheit positiv ist.
Autor: David Carvalho, Co-Founder & CEO, Naoris Protocol
Text in englischer Sprache:
Is ChatGPT AI the next Superman or humanity’s Kryptonite?
Now that the dust of innovation has settled on the hype around ChatGPT, it may be a good time to unpack the full implications of this technology. While it certainly helps sleep-deprived college students ace term papers and gives copywriters a creative boost, it has a potentially dark underbelly. David Carvalho, CEO and co-founder of Naoris Protocol, unpacks some of the not so pretty aspects of emerging AI technology and its potential to wreak havoc for businesses globally.
How can ChatGPT be used to exploit code and can it really create code?
The short answer is yes. OpenAI’s ChatGPT, is a large language model (LLM)-based artificial intelligence (AI) text generator, it just requires a prompt with a normal English language query.
GPT stands for Generative Pre-Trained Transformer, it is trained on a big data sample of text from the internet, containing billions of words to create learnings on all subjects in the samples. It can ‘‘think’ of everything from essays, poems, emails, and yes, computer code.
It can generate code fed to it from plain English text,or receive new and existing code as input. This code can however be exploited for malicious purposes, or more importantly, it can be used for defensive and protective applications, it’s all about the intentions of the user. While Google can show you an article on how to solve a specific coding problem, ChatGPT could write the code for you. This is a game-changer, it means that developers could do near-instant security audits of application code and Smart Contract code to find vulnerabilities and exploits prior to implementation. It would also enable companies to change their deployment processes making them more thorough prior to launch, reducing vulnerabilities once deployed. This would be a significant contribution to the fight against cyberthreat damage, which is expected to exceed $10 trillion by 2025.
What are some of the current limitations?
The downside is that bad actors can program AI to find vulnerabilities to exploit any popular, existing coding standard, Smart Contract code, or even known computing platforms and operating systems. This means that thousands of existing environments that are complex and at risk in the real world, could suddenly be exposed (in the short term).
AI is not conscious, it is an algorithm based on mathematical principles, weights and biases. It will miss basic preconceptions, knowledge, emotions and subtleties that only humans see. It should be seen as a tool that will improve vulnerabilities that are coded in error by humans. While it will potentially significantly improve the quality of coding across web2 and web3 applications, we can never, nor should we, fully trust its output. Despite this cautious approach, we should strive to have confidence that we will be able to trust its baseline in the future
Developers will still need to read and critique AI output by learning its patterns and looking for weak spots, while being cognizant of the fact that threat actors are using it for nefarious purposes in the short term. However I believe the net-output is a positive addition to the maturity of all processes in the long term. There will always be new threats for it to analyse and mitigate, so while it may be a great tool to assist developers, it will need to work in tandem with dev teams to strengthen the code and protect the systems. The attacking position will be to find bugs or errors in the output of the AI instead of the code itself. AI will be a great tool but humans will have the last word, hopefully. With some bumps along the way, this will be a net positive for the future of cyber security trust and assurance. In the short-term AI will expose vulnerabilities which will need to be addressed very quickly, and we could see a potential spike in breaches”.
Does regulation need to be updated to include/consider these models?
Regulation will be critical in the adoption of this type of AI, but it may also be avoided because current regulation is analogue in nature, i.e., broad, self-policed, usually reactive rather than proactive, and incredibly slow to evolve, especially in a fast-changing and innovative „target area“ like AI. Regulators in their current capacity might very well find themselves out of touch and out of their depth, they should be directly advised by specialists in the field and in academia to ensure quick reactions. Perhaps they should look at creating a completely separate Regulatory Body or Council for Ethics, with the purpose of regulating or setting up fundamental rules of what is off-limits while using such powerful dual-use technologies. Regulations usually only kick in when something has gone wrong, then it takes months, if not years to get the regulation through the various iterations and approval processes. Currently regulation in this field is not fit for purpose. The ability to oversee and implement regulation that addresses the rate at which AI learns and executes output, is a much-needed extra string to the compliance bow.
AI itself needs to be regulated, the burning question is “Should it be centralised?” We need to seriously consider whether centralised tech companies or governments should hold the keys and be able to “bias the AI” to influence outcomes. A more palatable model would be a decentralised solution, or at least a decentralised governance system that allows for the assurance of trust of the baseline systems that provide answers, and that provide data for the answers and all their processes through an assurance mesh. We should perhaps look at a model similar to how web 3 developers and validators are rewarded. The AI should have a pool of professional advocates who are incentivised to develop and evolve the AI to meet certain publicly ethical shared goals that ensure the technology is used for good in every sector that it’s operating in.
Can filters be created to detect these models?
Yes, but it would result in a whack-a-mole effect similar to what we have now, it would be a good best effort, but definitely no panacea. Filter-based ethical principles could be programmatically created to detect the models of any malicious or exploitative actor or define areas or topics that would be out of bounds. However, we need to ask “Who is in control of the AI code itself?” and “Can we trust the AI systems that are providing the answers not to be biased, or have compromised integrity from a baseline?”. If the baseline was indeed biased or compromised, we would 100% need to know.
The logical solution would be to protect networks and devices using decentralised and distributed consensus methods, so the status and trustworthiness of the data that is being generated is known to be good, true and trusted in a highly resilient and cryptographically strong manner. It must be auditable and immune to local tampering or subversion by malicious actors, whether internal or external.
So where to from here?
How Chat GPT crashed into the market can be compared to Superman’s arrival on planet Earth from Krypton. We had no clue of his existence before he arrived; we were not sure how his powers would impact the world as he grew up, and we were not sure how dark forces (Kryponite) could affect the outcome of his behaviour. It would be presumptuous, if not arrogant to suggest that anyone really knows how this is all going to play out. The only thing we know for sure is that some aspects of the way the world functions will change irrevocably. It will be an exciting and compelling journey to see how humanity deals with yet another game changing technology that in turn, will be overshadowed by many other innovations. We no longer have rear view mirrors to look at the past to help us predict the future, the future is a vector that will chart its own course and everyone will have a role to ensure it is a net positive for humanity.
Über das Naoris-Protokoll
Naoris Protocol ist das dezentralisierte CyberSecurity Mesh für die hypervernetzte Welt. Unser bahnbrechendes Designmuster macht Netzwerke sicherer, da sie wachsen und nicht schwächer werden, indem es jedes verbundene Gerät in einen vertrauenswürdigen Validierungsknoten verwandelt. Ein robustes Blockchain-Protokoll, das jedes Unternehmen zum Schutz vor den eskalierenden Cyber-Bedrohungen nutzen kann.
Geräte werden für vertrauenswürdiges Verhalten belohnt, wodurch eine sichere Umgebung gefördert wird. Teilnehmer verdienen $CYBER-Staking-Belohnungen für die Sicherung des Netzwerks.
Je mehr Nutzer, Unternehmen und Governance-Strukturen das Decentralised Cybersecure Mesh nutzen und Netzwerke von Netzwerken schaffen, desto stärker und sicherer wird es.
Fachartikel





Studien

Cloud-Transformation & GRC: Die Wolkendecke wird zur Superzelle

Threat Report: Anstieg der Ransomware-Vorfälle durch ERP-Kompromittierung um 400 %

Studie zu PKI und Post-Quanten-Kryptographie verdeutlicht wachsenden Bedarf an digitalem Vertrauen bei DACH-Organisationen

Zunahme von „Evasive Malware“ verstärkt Bedrohungswelle

Neuer Report bestätigt: Die Zukunft KI-gestützter Content Creation ist längst Gegenwart
Whitepaper




Unter4Ohren

Datenklassifizierung: Sicherheit, Konformität und Kontrolle

Die Rolle der KI in der IT-Sicherheit
CrowdStrike Global Threat Report 2024 – Einblicke in die aktuelle Bedrohungslandschaft
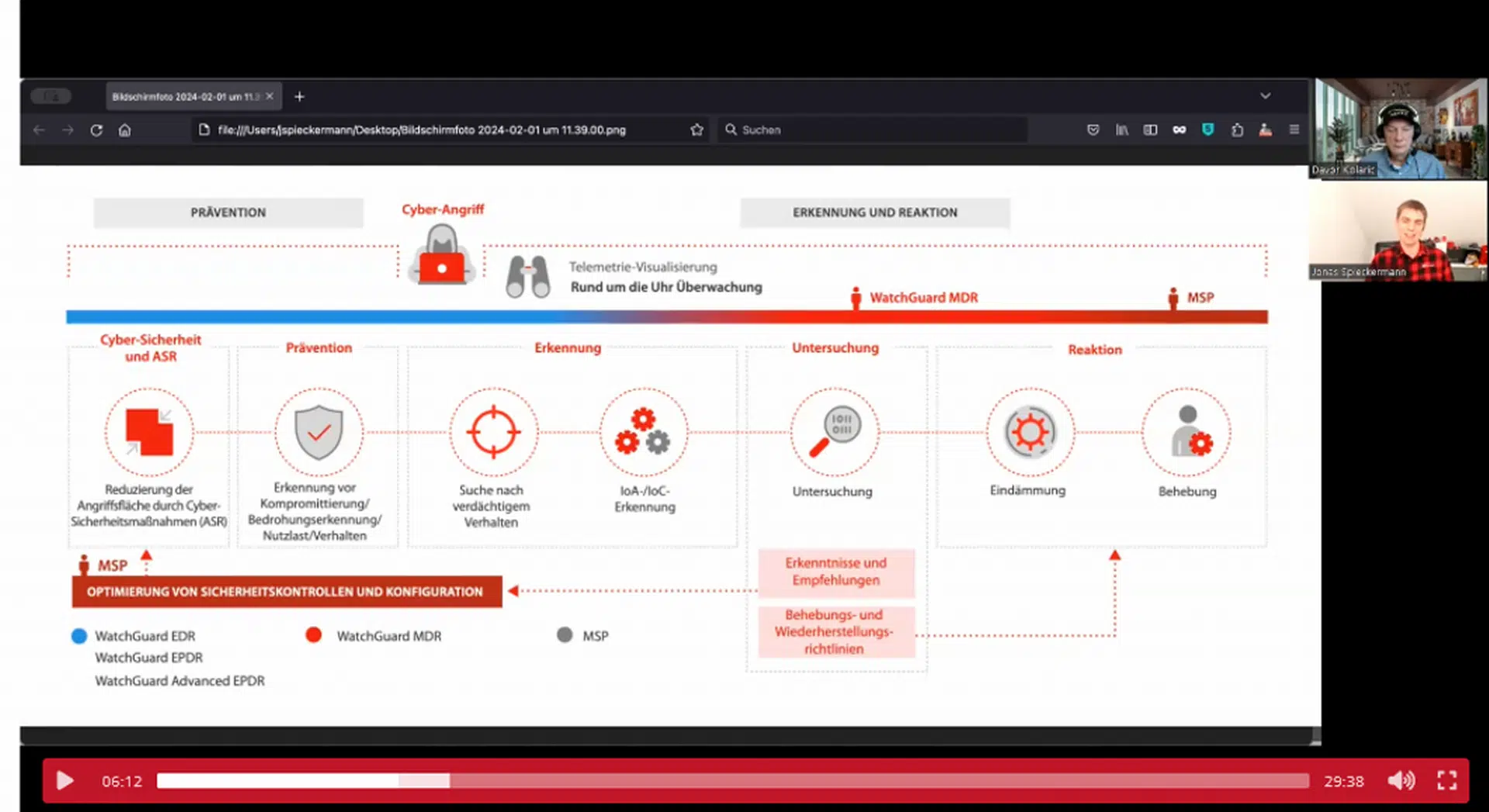
WatchGuard Managed Detection & Response – Erkennung und Reaktion rund um die Uhr ohne Mehraufwand