Wenn eine Anwendung nicht funktioniert, IoT-Geräte oder Webseiten nicht erreichbar sind, verlieren Unternehmen innerhalb kürzester Zeit viel Geld. Und das entsprechende Ausfälle kommen, ist in der modernen Welt der Hochgeschwindigekits-Anwendungsentwicklung keine Frage des Ob, sondern des Wann. Um darauf vorbereitet zu sein, müssen Zeit und Ressourcen aufgewendet werden, um eine ineffektive und unorganisierte Reaktion auf Störungen zu vermeiden, die im schlimmsten Fall zu weiteren Umsatzverlusten führen kann.
Die gute Nachricht: Es ist möglich, Best Practices und Workflow zu etablieren und die notwendigen Tools zu finden, die sicherstellen, dass jeder Vorfall so schnell wie möglich behoben wird und aus ihm für die Zukunft gelernt werden kann. Ein effizienter Incident Management-Prozess kann so die Resilience der gesamten Infrastruktur stärken. Doch wie sollte ein solcher Prozess aussehen, welche Schritte müssen unternommen welchen, wie sieht die Zusammenarbeit von Teams im besten Fall aus und welche Daten sollten zum Einsatz kommen?
Komplex aber nachhaltig
Tools und Daten bilden die Grundlage für Entwicklerteams, um auf Incidents zu reagieren – von Metriken über Logs bis hin zu Anwendungs-Traces, sowie Chat-, Messaging- und Video-Tools für die Kommunikation. Ein strukturierter Incident Management-Prozess ordnet die einzelnen Maßnahmen und Möglichkeiten und sorgt für klare Zuständigkeiten bei Alarmierung, Zusammenarbeit und der Dokumentation der Vorfälle.
Um im Worst Case den Plan in der Schublade zu haben, sollte der Prozess dann festgelegt und etabliert werden, wenn die Systeme reibungslos laufen. Und selbst wenn alles läuft, sorgen komplexe Prozesse und notwendiges Expertenwissen dafür, dass die Workflow-Definition kein Strandspaziergang ist. Es muss zunächst festgelegt werden, wer für das Reaktionsmanagement verantwortlich ist, welche Informationen benötigt werden und wie ein Vorfall dokumentiert wird, um daraus Learnings für die Zukunft zu ziehen. Dafür erforderlich sind zugängliche Daten, klar definierte Kommunikationskanäle, sowie Rollen und Verantwortlichkeiten innerhalb des Teams – alles im Voraus geplant und dokumentiert, damit der Umgang mit dem Problem nicht mit der eigentlichen Lösung des Problems kollidiert.
Was? Wer? Warum?
Der Auslöser eines Incident Management-Workflows ist in der Regel ein ausgelöster Alarm. Es ist entsprechend wichtig, festzulegen, welche Daten oder Anomalien überhaupt für einen Alarmsignal in Frage kommen. Welche Daten deuten darauf hin, dass hier gerade etwas gewaltig schiefläuft? Und im nächsten Schritt: Wer wird alarmiert und wann?
Um effektiv auf einen Vorfall reagieren zu können, müssen die richtigen Personen mit den richtigen Informationen alarmiert und versorgt werden, um dann auf Grundlage eines gemeinsamen Informationspools an der Lösung arbeiten können. Dafür müssen der Alarm ebenso wie die dazugehörigen Grafiken und Diagramme in kollaborativen Tools zugänglich gemacht werden.
Schnelle Reaktion durch einheitliche Workflows
Die richtigen Personen sind alarmiert, der erste Schritt des Incident Management-Prozesses gegangen. Nun brauchen die Verantwortlichen nicht nur den Zugriff auf die erste Fehlermeldung, sondern auch auf alle relevanten Daten; sowohl die des aktuellen Vorfalls als auch die früherer sowie der Baseline im ungestörten Regelbetrieb. Die Teams benötigen außerdem die Möglichkeit, Vorfälle nach wichtigen Metadaten zu sortieren und eine chronologische Liste der zum Problem beitragenden Aktualisierungen abrufen zu können. Über integrierte Tools, die alle notwendigen Daten an einem Ort zusammenführen, wird diese Zusammenarbeit einfacher und sinnvoller.
Aus der Vergangenheit lernen
Wie welche Situationen bewältigt werden können, liegt ist natürlich für viele Vorfälle individuell anders. Dieser Schritt lässt sich nicht pauschal von Vornherein festlegen. Sobald das Problem aber behoben ist, gilt es, Maßnahmen zu ergreifen, um die Wahrscheinlichkeit zu verringern, dass das gleiche Problem erneut auftritt beziehungsweise beim nächsten Mal die Identifikation und Behebung beschleunigt werden kann.
Dokumentation und Postmortems sind daher entscheidend für das Incident Management. Wenn ein neuer Vorfall mit einem vergangenen Vorfall korreliert, kann herausgefunden werden, ob das Problem bereits bekannt ist. Zu einer entsprechenden Dokumentation gehören daher eine Liste mit Folgeaufgaben zur Behebung akuter Probleme, fixe Pläne zur Aktualisierung von Warnmeldungen und ein detailliertes, öffentliches Postmortem-Dokument, damit alle im Team das Problem besser verstehen und ähnliche Probleme schneller identifizieren können. Wenn dann ein ähnlicher Vorfall in der Zukunft auftritt, hat das Team auf diese Weise alle historischen Informationen, die es braucht, an einem Ort. Außerdem helfen aussagekräftige Postmortem-Dokumente dabei, die Ursachen im Rahmen einer Softwareänderung zu beseitigen und diese Änderung nach deren Umsetzung auf Wirksamkeit zu Überprüfen.
Zeit für Neues
Wer für sich einen Incident Management-Workflow festlegt, der sich an den beschriebenen Prinzipien orientiert, der kann auf Vorfälle effektiver und effizienter reagieren. Einen solchen Plan in der Schublade zu haben spart Zeit und ermöglicht es den Teams, sich auf die Entwicklung neue Produkte und Funktionen zu konzentrieren, statt sich planlos um Probleme kümmern zu müssen.
Außerdem gilt: Wer das, was bereits aufgebaut ist, nicht richtig pflegt und wartet, wird nicht in der Lage sein, Neues zu bauen. Ein effizientes Incident Management ist ein wichtiger Weg, um dies zu ermöglichen und Freiräume zu schaffen.
Autor: Stefan Marx ist Director Product Management für die EMEA-Region beim Cloud-Monitoring-Anbieter Datadog. Marx ist seit über 20 Jahren in der IT-Entwicklung und -Beratung tätig. In den vergangenen Jahren arbeitete er mit verschiedenen Architekturen und Techniken wie Java Enterprise Systemen und spezialisierten Webanwendungen. Seine Tätigkeitsschwerpunkte liegen in der Planung, dem Aufbau und dem Betrieb der Anwendungen mit Blick auf die Anforderungen und Problemstellungen hinter den konkreten IT-Projekten.
Fachartikel





Studien

Cloud-Transformation & GRC: Die Wolkendecke wird zur Superzelle

Threat Report: Anstieg der Ransomware-Vorfälle durch ERP-Kompromittierung um 400 %

Studie zu PKI und Post-Quanten-Kryptographie verdeutlicht wachsenden Bedarf an digitalem Vertrauen bei DACH-Organisationen

Zunahme von „Evasive Malware“ verstärkt Bedrohungswelle

Neuer Report bestätigt: Die Zukunft KI-gestützter Content Creation ist längst Gegenwart
Whitepaper




Unter4Ohren

Datenklassifizierung: Sicherheit, Konformität und Kontrolle

Die Rolle der KI in der IT-Sicherheit
CrowdStrike Global Threat Report 2024 – Einblicke in die aktuelle Bedrohungslandschaft
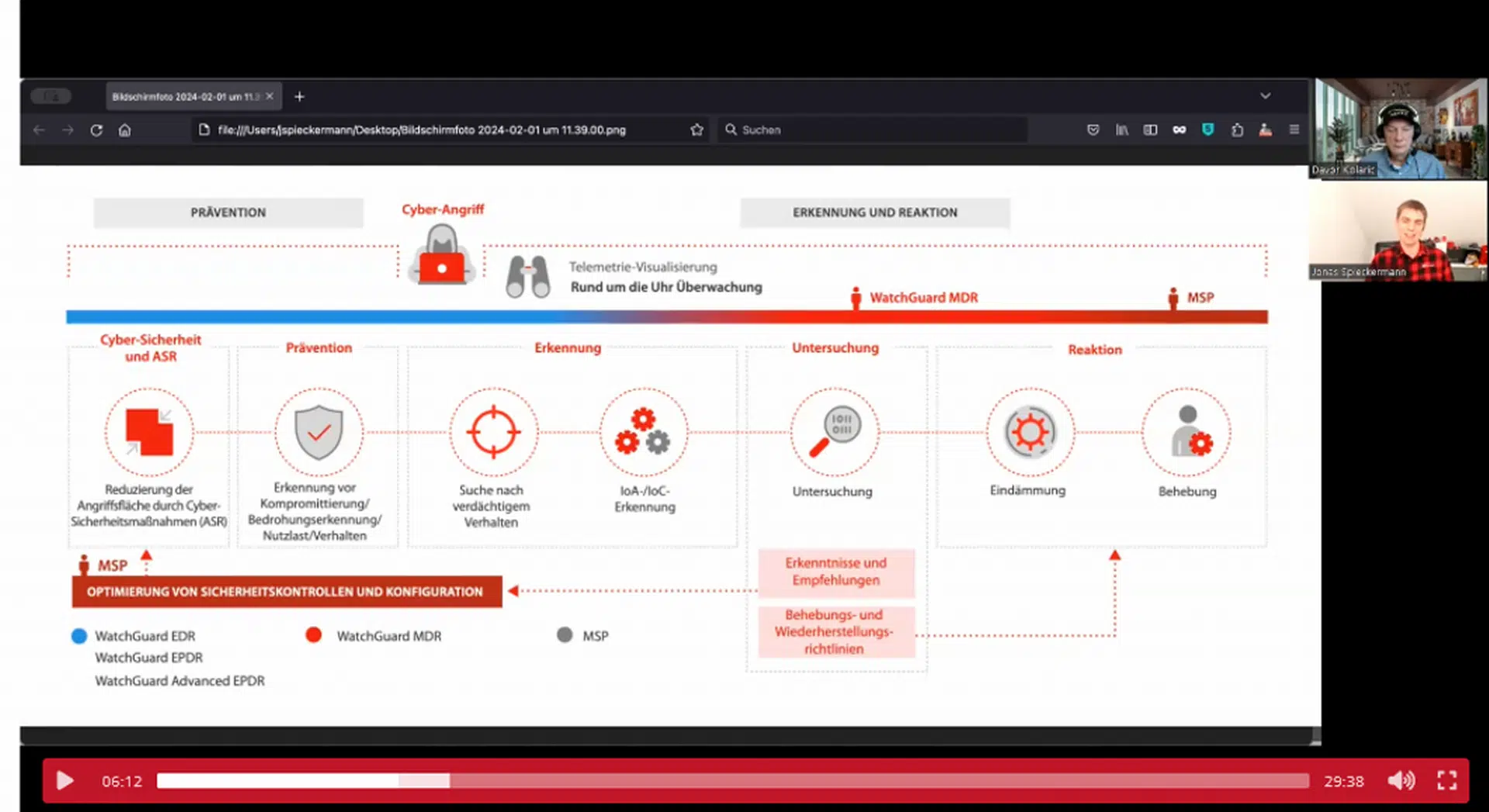
WatchGuard Managed Detection & Response – Erkennung und Reaktion rund um die Uhr ohne Mehraufwand