Es hat eine Weile gedauert, nun ist er auch hierzulande endgültig geplatzt: der Knoten um die (hybride) Cloud. Zahlreiche deutsche Unternehmen nutzen inzwischen Cloud-Services – oder haben vor, dies in den kommenden Jahren zu tun. Während unter anderem Sicherheitsbedenken anfänglich für Zurückhaltung sorgten, scheint die große Datenwolke inzwischen zum Heilsversprechen für die unternehmenseigene IT-Umgebung geworden zu sein. Sicherlich kann sie vielen Erwartungen gerecht werden – wenn die IT-Verantwortlichen ein übergreifendes Monitoring nutzen und damit ihre zahlreichen Einzelkomponenten im Blick behalten.
Die Verlagerung unternehmenseigener IT-Komponenten in die Cloud entwickelt sich mehr und mehr zur Norm. Vom Mittelstand bis in die Großkonzerne hat sich die Überzeugung durchgesetzt, dass eine Migration auf externe Ressourcen zahlreiche Vorteile mit sich bringt. Was genau sich Unternehmen davon versprechen, erklärt unter anderem die IDG-Studie „Cloud Migration 2018“: Es sind vornehmlich geringere Ausfallzeiten, mehr Sicherheit, ein höherer Bedienkomfort sowie Governance und Kontrollmöglichkeiten. In der Tat verheißungsvoll – nur ohne die passenden Maßnahmen und Instrumente bleiben diese Ziele Wunschdenken. Insbesondere in heterogenen und hybriden Umgebungen, die auf verschiedenen Systemen aufbauen oder in Infrastructure-as-Code-Umgebungen eingebettet sind, entstehen schnell blinde Flecken. Deshalb sollten Unternehmen bei dem Umzug in die Cloud ein Monitoring nutzen, das auch in komplexen Umgebungen zuverlässige Einblicke in die Performance und Produktivität ihrer Anwendungslandschaft bietet, damit groß angelegte Migrationsprojekte nicht hinter den Erwartungen zurückbleiben.
Markt der (beinahe) unbegrenzten Möglichkeiten
Die Akzeptanz der Cloud als probate Geschäftslösung hat eine Anbieterschwemme und damit einhergehend einen regelrechten Produktboom ausgelöst. Für Unternehmen ist diese Marktdynamik in erster Linie ein großer Gewinn, können sie doch aus dem vollen Schöpfen und auf Basis zahlreicher unterschiedlicher Lösungen das für ihr Unternehmen beste Konzept verwirklichen. Ein Segen, der allerdings mit einer nicht unerheblichen Komplexität bei der technischen Umsetzung einhergeht. Die hybride oder auch Multi-Cloud wird vielerorts als der Megatrend 2019 gehandelt. Im Klartext bedeutet das: Organisationen nutzen immer öfter mehr als nur einen Service von mehr als nur einem Public- oder Private Cloud-Anbieter. Es entstehen verteilte Anwendungslandschaften, die in einer Vielzahl von Stacks und auf Hunderten von Maschinen laufen. Um derart heterogene Systeme und Anwendungen tatsächlich optimal zu orchestrieren, setzt eine wachsende Anzahl von IT-Verantwortlichen zum Management ihrer Cloud-Ressourcen auf Open Source-basierte IaC-Umgebungen (Infrastructure-as-Code). Ein Ansatz, der über ein Plus an Systemzuverlässigkeit und Sicherheit hinaus für agilere Prozesse bei der Entwicklung neuer Infrastrukturen, Produkte und Services sorgen kann.
IaC überzeugt durch hohe Anpassungsfähigkeit
Agiler, zuverlässiger, skalierbarer, sicherer. Und nicht zur vergessen: Kostenfaktoren, die sicherlich für jedes IT-Team auf der Agenda stehen. Ein breites Spektrum an Anforderungen, die moderne Cloud-Konzepte abdecken müssen. Wie kann der IaC-Ansatz dabei helfen? Die Lösung liegt in der hohen Anpassungsfähigkeit von Code-gemanagten Umgebungen: Frameworks, die nach dem IaC-Prinzip arbeiten, ersparen Entwicklern und Administratoren aufwändige, händische Systemeinstellungen, indem sie automatisiert Skripts oder Definitionsdateien zur Konfiguration einzelner Module und Maschinen ausrollen. Die programmierten Bereitstellungsprozesse spiegeln komplexe Abläufe wider und sind systemadaptiv. Für Multi-Clouds ist IaC insbesondere deshalb inzwischen Mittel der ersten Wahl, weil sich die Tools und Prozesse dieses Prinzip unabhängig von der Zusammensetzung eines Cloud-Stacks oder von Services unterschiedlicher Cloud-Provider an die Umgebung anpassen. Sie wachsen kontinuierlich mit der Infrastruktur und ihren einzelnen Modulen und schaffen damit große Flexibilität bei der Gestaltung individueller, bedarfsangepasster Cloud-Umgebungen. Es ist also kaum verwunderlich, dass inzwischen zahlreiche Unternehmen auf Open Source-Werkzeuge wie Terraform, Puppet oder Ansible setzen, um ihre komplexen Cloud-Umgebungen zu orchestrieren. Trotz aller Vorteile darf eines allerdings nicht vergessen werden: Das IaC-basierte Management von Multi-Cloud-Umgebungen und unterschiedlichen Services kann nur halten, was sich Unternehmen versprechen, wenn IT-Verantwortliche Zugriff auf erfolgsrelevante Kennzahlen haben. Deshalb sollte genau hier ein übergreifendes Cloud-Monitoring ins Spiel kommen.
Monitoring ist ein Muss für hybride Clouds
Terraform & Co. helfen dabei, das Management komplexer Cloud-Gefüge vor allem im Hinblick auf Systemtransparenz, Nachvollziehbarkeit und Skalierbarkeit zu vereinfachen. Darüber hinaus sind sie plattformunabhängig, was einen maßgeblichen Einfluss auf die Interoperabilität der gesamten Cloud-Umgebung und die Portierbarkeit von Daten und Anwendungen hat. Terraform & Co. orchestrieren IT-Infrastrukturen auf Basis maschinenlesbarer Sprachen – IaC-Umgebungen werden deshalb auch als programmierbare Infrastrukturen bezeichnet. Eben weil sie über alle Plattformen hinweg kommunizieren und arbeiten können, ist die Möglichkeit, auf Knopfdruck einen Einblick in heterogene, IaC-basierte Cloud-Umgebungen zu bekommen, essentiell: IT-Verantwortliche, die fehlerhafte Workflows oder akute Auslastungsprobleme nicht erkennen, riskieren im schlimmsten Fall ganze Systemausfälle. Diese halten das IT-Team von ihrer eigentlichen Arbeit abhalten und binden damit wichtige Ressourcen. Ressourcen, die ursprünglich zum Beispiel in die Entwicklung neuer Services fließen sollten. Hier kann die Kombination eines intelligenten Monitorings mit Infrastructure-as-Code-Lösungen viel dazu beitragen, unwirtschaftliche Performance-Stolpersteine ebenso wie Sicherheitsrisiken auszuschließen.
Standard-Werkzeuge sind zu kurzsichtig
Zwar bieten die großen Cloud-Player eigene Monitoring-Lösungen an, allerdings fehlt es diesen Tools in der Regel an Weitsicht: In heterogenen und hybriden Umgebungen stoßen sie in Fragen der Anpassungsfähigkeit schnell an ihre Grenzen. Ein Grund dafür besteht darin, dass die hauseigenen Monitoring-Werkzeuge der Cloud-Riesen AWS, IBM & Co. kaum oder gar nicht mit anderen Systemen zusammenarbeiten, sondern nur ihre native Infrastruktur betrachte. Darüber hinaus weisen sie häufig eine geringere Granularität und eine kürzere Datenvorhaltung auf. Eine Monitoring-Lösung, der nichts entgehen soll, muss jedoch ebenso komplex, dynamisch und plattform-unabhängig arbeiten wie das IaC-basierte Management der Cloud-Umgebung selbst. Deshalb funktioniert das Monitoring in diesem Umfeld nur dann wirklich gut, wenn die eingesetzte Lösung breit aufgestellt ist und zahlreiche Cloud-Module integriert oder die erforderlichen APIs bei Bedarf selbst bauen kann. Apps und Anwendungen, unterschiedliche Cloud-Provider, Internet-of-Things-Umgebungen, wechselnde Container-Technologien, mannigfaltige Endgeräte und Hardware – die Auslastung all dieser Elemente muss zu jeder Zeit erfasst und interpretiert werden können. Geschieht dies nicht, können Prozessfehler, Schnittstellenprobleme oder die Einbindung falscher Komponenten nicht schnell genug erkannt werden.
Die komplette Systemgesundheit im Blick
Ein kluges Monitoring sollte beides können: sowohl ad hoc Probleme erkennen als auch stichhaltige Vorhersagen treffen. Um diese breite Funktionsspanne abzudecken, ist die systematische Erfassung einer Reihe von Kennzahlen gefragt, die sich im Cloud-Kosmos grob in operative Kennzahlen, den „Work Metrics“, und Ressourcenkennzahlen, den sogenannten „Resource Metrics“, unterteilen lassen.
Work Metrics können in vier weitere Unterkategorien ausdifferenziert werden: Sie erfassen den Durchsatz („throughput“), den ein System über eine festgelegte Zeitspanne hinweg ausweist; sie zeigen den prozentualen Anteil der erfolgreichen Operationen („success“) an; sie ermitteln die Anzahl fehlerhafter Operationen („error“); sie quantifizieren die Performance („performance“) der einzelnen Komponenten, beispielsweise durch die Ermittlung der Latenz- und Antwortzeiten. Work Metrics können zum Beispiel die Anzahl der Anfragen an einen Web-Server pro Sekunde, also den Durchsatz, oder die durchschnittliche Antwortzeit eines Datenspeichers und damit seine Performance beschreiben. In Summe erlauben all diese Kennzahlen wichtige, übergreifende Rückschlüsse auf die Gesundheit und Leistungsfähigkeit des gemessenen Systems. Darüber hinaus können IT-Verantwortliche anhand von Ressourcenkennzahlen die unterschiedlichen Bestandteile der Systeminfrastruktur detailliert betrachten und ihre Nutzung, („utilization“), Sättigung („saturation“), Verfügbarkeit („Availability“) sowie Fehler („Errors“) auswerten.
Frequenz und Vorhaltungsdauer sind wichtig
Diese Messgrößen lassen sich gut am Beispiel einer Datenbank erläutern: die Nutzungskennzahl beschreibt die durchschnittliche Zeit, in der sämtliche Verbindungen aktiv waren; die Sättigung zeigt an, wie viele Anfragen an die Datenbank über einen definierten Zeitraum in der Warteschlange verbleiben mussten; die Verfügbarkeit zeigt den prozentualen Anteil der Zeit an, in der die Datenbank verfügbar war; die Kennzahl „errors“ gibt Auskunft über interne Fehler wie beispielsweise Speicher- oder Replikationsprobleme. Unabhängig von der Kennzahlkategorien sollten Cloud-Analysten darauf achten, mit der passenden Granularität zu arbeiten: Zu lang gemessene Durchschnittswerte mindern die Aussagekraft von Monitoring-Maßnahmen ebenso wie zu selten oder unregelmäßig erhobene Kennzahlen. Ebenso wichtig ist es, dass erfasste Rohdaten möglichst lange vorgehalten werden. Um monatliche, saisonale oder jährliche Abweichungen klar herausarbeiten zu können, sollten sie mindestens ein Jahr lang gespeichert bleiben. Intelligente, selbstlernende Monitoring-Lösungen entwickeln diese Kennzahlen unter Einbindung von Machine-Learning (ML)-Technologien kontinuierlich weiter, was die Genauigkeit der Kennzahlenauswertung weiter erhöht.
Keine Kompromisse bei der Visualisierung
Damit IT-Teams nicht nur im Bedarfsfall, sondern schon im Vorfeld zielführend agieren können, reicht es nicht aus, lediglich über Observability-Daten zu verfügen. Deshalb darf die Qualität der Reporting-Funktionen bei der Betrachtung von Cloud-Umgebungen nicht ins Hintertreffen geraten. Relevante Daten müssen eingängig aufbereitet sein, sonst verbringen die verantwortlichen Mitarbeiter wertvolle Zeit mit manuellen Datenbankensuchen, aufwändigen händischen Analysen oder gar der nervenaufreibenden Formatierung von Excel-Sheets. Damit dies nicht geschieht, braucht es kluge Visualisierungsfeatures. Denn ein gutes Monitoring entfaltet erst dann sein volles Potenzial, wenn bedeutsame Erkenntnisse ohne Umschweife und auf einen Blick gewonnen werden können. Wird das Monitoring-Tool der Komplexität seines Wirkungsbereichs gerecht – und in hybriden Multi-Cloud und IaC-Umgebungen ist diese wahrlich ausgeprägt – können IT-Entscheider schnell und zielgerichtet sowohl operative als auch strategische Weichen stellen. Und das alles auf Basis gut sichtbarer Daten.
Ob Sicherheit, Transparenz, Performance oder Kosteneffizienz, der Schlüssel für erfolgreiche Cloud-Konzepte wird künftig mehr denn je darin liegen, den Überblick zu behalten. Eine Herausforderung, steigt doch mit den Möglichkeiten der dezentralen Vorhaltung und Virtualisierung von IT-Ressourcen auch die Komplexität der Infrastrukturen. Deshalb werden sich die Erwartungen der Unternehmen an das Potenzial von vielschichtigen Multi-Cloud und IaC-Umgebungen nur dann erfüllen, wenn sie sämtliche Komponenten zu jeder Zeit im Blick haben.
Der Autor:
Stefan Marx ist Director Product Management EMEA bei Datadog
Fachartikel





Studien

Drei Viertel aller DACH-Unternehmen haben jetzt CISOs – nur wird diese Rolle oft noch missverstanden

AI-Security-Report 2024 verdeutlicht: Deutsche Unternehmen sind mit Cybersecurity-Markt überfordert

Cloud-Transformation & GRC: Die Wolkendecke wird zur Superzelle

Threat Report: Anstieg der Ransomware-Vorfälle durch ERP-Kompromittierung um 400 %

Studie zu PKI und Post-Quanten-Kryptographie verdeutlicht wachsenden Bedarf an digitalem Vertrauen bei DACH-Organisationen
Whitepaper




Unter4Ohren

Datenklassifizierung: Sicherheit, Konformität und Kontrolle

Die Rolle der KI in der IT-Sicherheit
CrowdStrike Global Threat Report 2024 – Einblicke in die aktuelle Bedrohungslandschaft
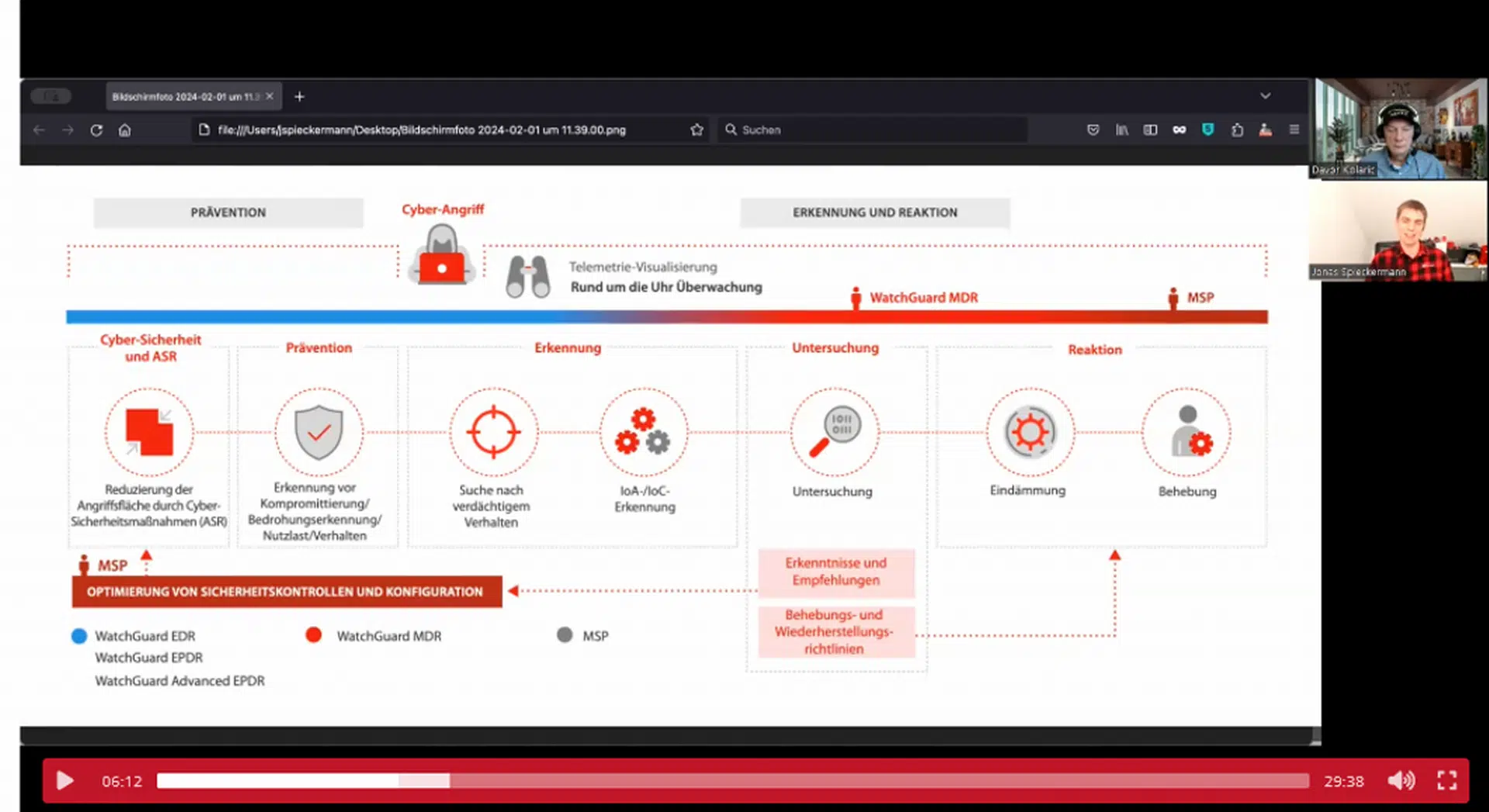
WatchGuard Managed Detection & Response – Erkennung und Reaktion rund um die Uhr ohne Mehraufwand